 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFullPart: Generating each 3D Part at Full Resolution
Oct 30, 2025Part-based 3D generation holds great potential for various applications. Previous part generators that represent parts using implicit vector-set tokens often suffer from insufficient geometric details. Another line of work adopts an explicit voxel representation but shares a global voxel grid among all parts; this often causes small parts to occupy too few voxels, leading to degraded quality. In this paper, we propose FullPart, a novel framework that combines both implicit and explicit paradigms. It first derives the bounding box layout through an implicit box vector-set diffusion process, a task that implicit diffusion handles effectively since box tokens contain little geometric detail. Then, it generates detailed parts, each within its own fixed full-resolution voxel grid. Instead of sharing a global low-resolution space, each part in our method - even small ones - is generated at full resolution, enabling the synthesis of intricate details. We further introduce a center-point encoding strategy to address the misalignment issue when exchanging information between parts of different actual sizes, thereby maintaining global coherence. Moreover, to tackle the scarcity of reliable part data, we present PartVerse-XL, the largest human-annotated 3D part dataset to date with 40K objects and 320K parts. Extensive experiments demonstrate that FullPart achieves state-of-the-art results in 3D part generation. We will release all code, data, and model to benefit future research in 3D part generation.
Interactive3D: Create What You Want by Interactive 3D Generation
Apr 25, 2024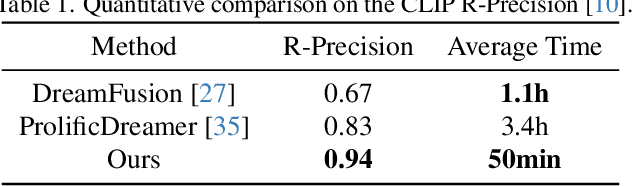


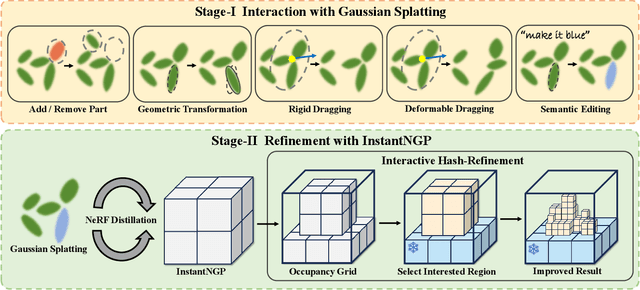
3D object generation has undergone significant advancements, yielding high-quality results. However, fall short of achieving precise user control, often yielding results that do not align with user expectations, thus limiting their applicability. User-envisioning 3D object generation faces significant challenges in realizing its concepts using current generative models due to limited interaction capabilities. Existing methods mainly offer two approaches: (i) interpreting textual instructions with constrained controllability, or (ii) reconstructing 3D objects from 2D images. Both of them limit customization to the confines of the 2D reference and potentially introduce undesirable artifacts during the 3D lifting process, restricting the scope for direct and versatile 3D modifications. In this work, we introduce Interactive3D, an innovative framework for interactive 3D generation that grants users precise control over the generative process through extensive 3D interaction capabilities. Interactive3D is constructed in two cascading stages, utilizing distinct 3D representations. The first stage employs Gaussian Splatting for direct user interaction, allowing modifications and guidance of the generative direction at any intermediate step through (i) Adding and Removing components, (ii) Deformable and Rigid Dragging, (iii) Geometric Transformations, and (iv) Semantic Editing. Subsequently, the Gaussian splats are transformed into InstantNGP. We introduce a novel (v) Interactive Hash Refinement module to further add details and extract the geometry in the second stage. Our experiments demonstrate that Interactive3D markedly improves the controllability and quality of 3D generation. Our project webpage is available at \url{https://interactive-3d.github.io/}.
MsSVT++: Mixed-scale Sparse Voxel Transformer with Center Voting for 3D Object Detection
Jan 22, 2024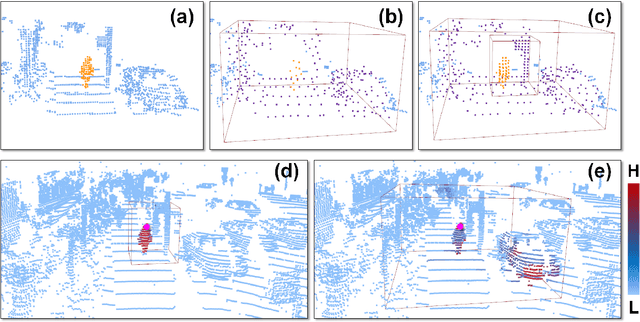
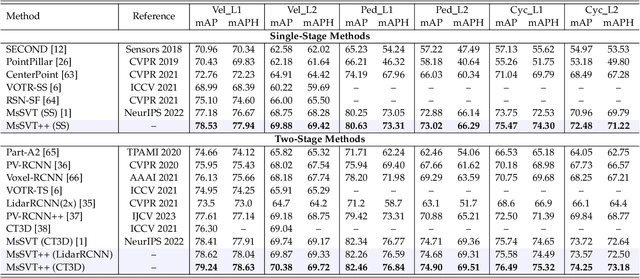
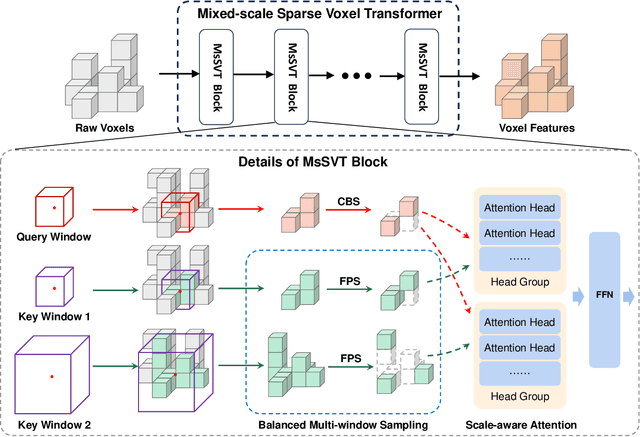
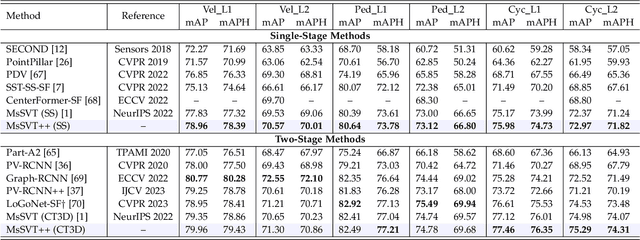
Accurate 3D object detection in large-scale outdoor scenes, characterized by considerable variations in object scales, necessitates features rich in both long-range and fine-grained information. While recent detectors have utilized window-based transformers to model long-range dependencies, they tend to overlook fine-grained details. To bridge this gap, we propose MsSVT++, an innovative Mixed-scale Sparse Voxel Transformer that simultaneously captures both types of information through a divide-and-conquer approach. This approach involves explicitly dividing attention heads into multiple groups, each responsible for attending to information within a specific range. The outputs of these groups are subsequently merged to obtain final mixed-scale features. To mitigate the computational complexity associated with applying a window-based transformer in 3D voxel space, we introduce a novel Chessboard Sampling strategy and implement voxel sampling and gathering operations sparsely using a hash map. Moreover, an important challenge stems from the observation that non-empty voxels are primarily located on the surface of objects, which impedes the accurate estimation of bounding boxes. To overcome this challenge, we introduce a Center Voting module that integrates newly voted voxels enriched with mixed-scale contextual information towards the centers of the objects, thereby improving precise object localization. Extensive experiments demonstrate that our single-stage detector, built upon the foundation of MsSVT++, consistently delivers exceptional performance across diverse datasets.
Text-to-3D Generation with Bidirectional Diffusion using both 2D and 3D priors
Dec 07, 2023



Most 3D generation research focuses on up-projecting 2D foundation models into the 3D space, either by minimizing 2D Score Distillation Sampling (SDS) loss or fine-tuning on multi-view datasets. Without explicit 3D priors, these methods often lead to geometric anomalies and multi-view inconsistency. Recently, researchers have attempted to improve the genuineness of 3D objects by directly training on 3D datasets, albeit at the cost of low-quality texture generation due to the limited texture diversity in 3D datasets. To harness the advantages of both approaches, we propose Bidirectional Diffusion(BiDiff), a unified framework that incorporates both a 3D and a 2D diffusion process, to preserve both 3D fidelity and 2D texture richness, respectively. Moreover, as a simple combination may yield inconsistent generation results, we further bridge them with novel bidirectional guidance. In addition, our method can be used as an initialization of optimization-based models to further improve the quality of 3D model and efficiency of optimization, reducing the generation process from 3.4 hours to 20 minutes. Experimental results have shown that our model achieves high-quality, diverse, and scalable 3D generation. Project website: https://bidiff.github.io/.
Sample-adaptive Augmentation for Point Cloud Recognition Against Real-world Corruptions
Sep 19, 2023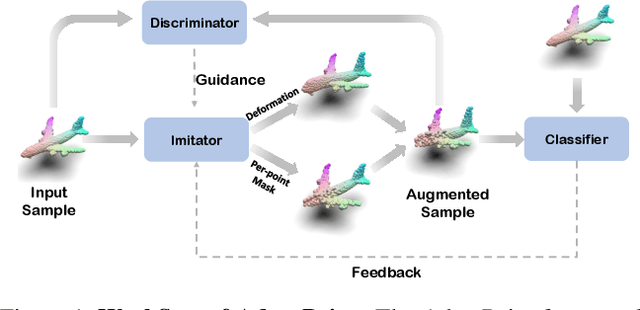

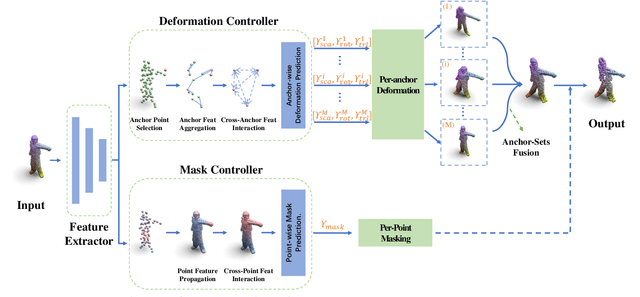

Robust 3D perception under corruption has become an essential task for the realm of 3D vision. While current data augmentation techniques usually perform random transformations on all point cloud objects in an offline way and ignore the structure of the samples, resulting in over-or-under enhancement. In this work, we propose an alternative to make sample-adaptive transformations based on the structure of the sample to cope with potential corruption via an auto-augmentation framework, named as AdaptPoint. Specially, we leverage a imitator, consisting of a Deformation Controller and a Mask Controller, respectively in charge of predicting deformation parameters and producing a per-point mask, based on the intrinsic structural information of the input point cloud, and then conduct corruption simulations on top. Then a discriminator is utilized to prevent the generation of excessive corruption that deviates from the original data distribution. In addition, a perception-guidance feedback mechanism is incorporated to guide the generation of samples with appropriate difficulty level. Furthermore, to address the paucity of real-world corrupted point cloud, we also introduce a new dataset ScanObjectNN-C, that exhibits greater similarity to actual data in real-world environments, especially when contrasted with preceding CAD datasets. Experiments show that our method achieves state-of-the-art results on multiple corruption benchmarks, including ModelNet-C, our ScanObjectNN-C, and ShapeNet-C.
RDFNet: Regional Dynamic FISTA-Net for Spectral Snapshot Compressive Imaging
Feb 06, 2023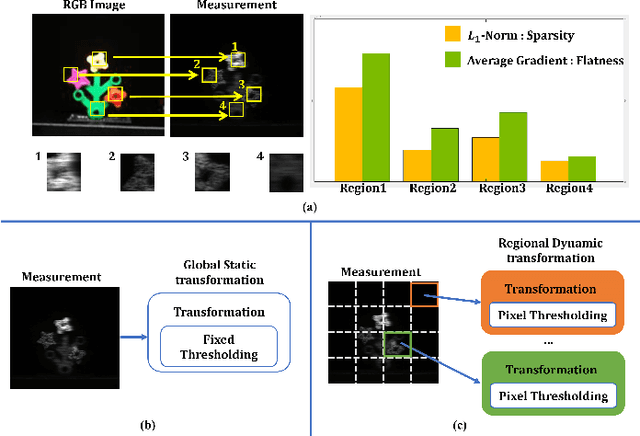
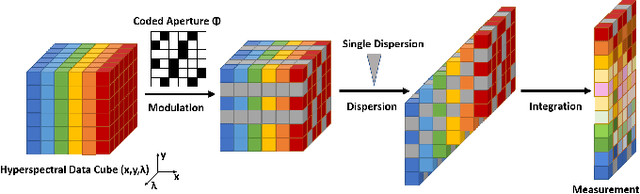
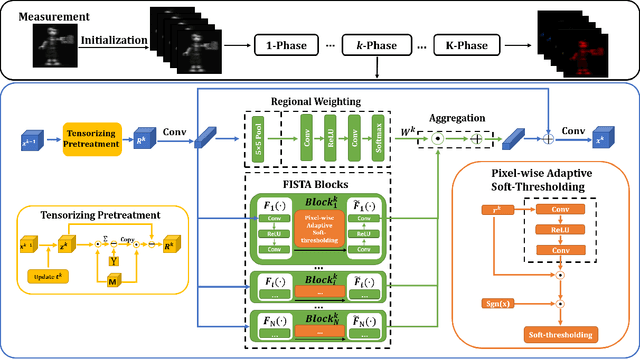
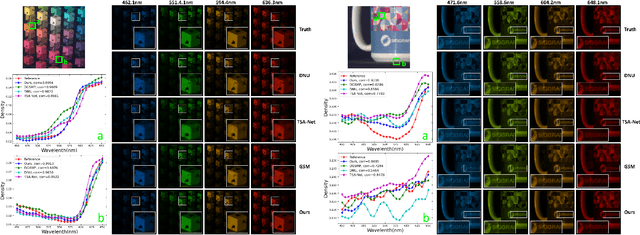
Deep convolutional neural networks have recently shown promising results in compressive spectral reconstruction. Previous methods, however, usually adopt a single mapping function for sparse representation. Considering that different regions have distinct characteristics, it is desirable to apply various mapping functions to adjust different regions' transformations dynamically. With this in mind, we first introduce a regional dynamic way of using Fast Iterative Shrinkage-Thresholding Algorithm (FISTA) to exploit regional characteristics and derive dynamic sparse representations. Then, we propose to unfold the process into a hierarchical dynamic deep network, dubbed RDFNet. The network comprises multiple regional dynamic blocks and corresponding pixel-wise adaptive soft-thresholding modules, respectively in charge of region-based dynamic mapping and pixel-wise soft-thresholding selection. The regional dynamic block guides the network to adjust the transformation domain for different regions. Equipped with the adaptive soft-thresholding, our proposed regional dynamic architecture can also learn appropriate shrinkage scale in a pixel-wise manner. Extensive experiments on both simulated and real data demonstrate that our method outperforms prior state-of-the-arts.
CAGroup3D: Class-Aware Grouping for 3D Object Detection on Point Clouds
Oct 09, 2022
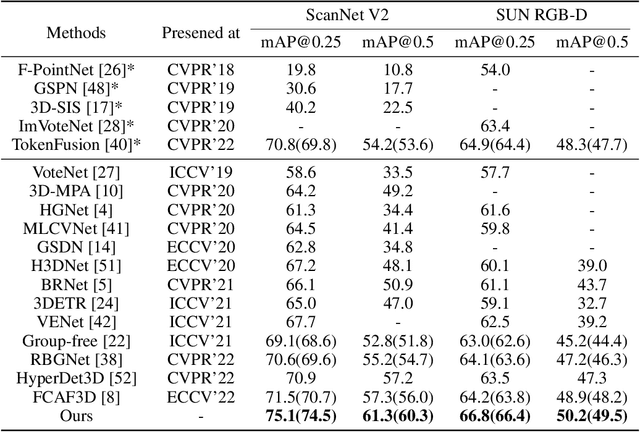
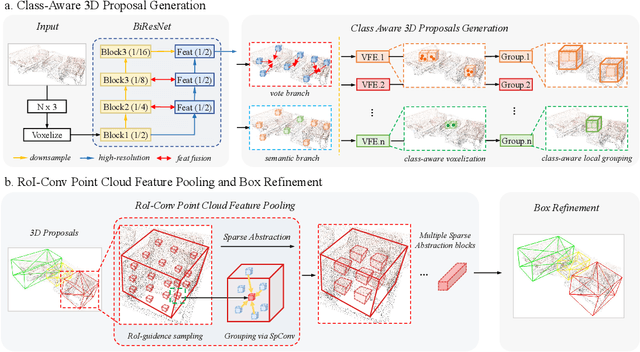

We present a novel two-stage fully sparse convolutional 3D object detection framework, named CAGroup3D. Our proposed method first generates some high-quality 3D proposals by leveraging the class-aware local group strategy on the object surface voxels with the same semantic predictions, which considers semantic consistency and diverse locality abandoned in previous bottom-up approaches. Then, to recover the features of missed voxels due to incorrect voxel-wise segmentation, we build a fully sparse convolutional RoI pooling module to directly aggregate fine-grained spatial information from backbone for further proposal refinement. It is memory-and-computation efficient and can better encode the geometry-specific features of each 3D proposal. Our model achieves state-of-the-art 3D detection performance with remarkable gains of +\textit{3.6\%} on ScanNet V2 and +\textit{2.6}\% on SUN RGB-D in term of mAP@0.25. Code will be available at https://github.com/Haiyang-W/CAGroup3D.
FusionRCNN: LiDAR-Camera Fusion for Two-stage 3D Object Detection
Sep 22, 2022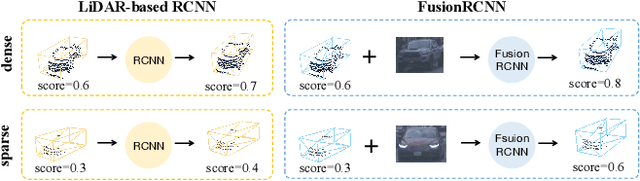



3D object detection with multi-sensors is essential for an accurate and reliable perception system of autonomous driving and robotics. Existing 3D detectors significantly improve the accuracy by adopting a two-stage paradigm which merely relies on LiDAR point clouds for 3D proposal refinement. Though impressive, the sparsity of point clouds, especially for the points far away, making it difficult for the LiDAR-only refinement module to accurately recognize and locate objects.To address this problem, we propose a novel multi-modality two-stage approach named FusionRCNN, which effectively and efficiently fuses point clouds and camera images in the Regions of Interest(RoI). FusionRCNN adaptively integrates both sparse geometry information from LiDAR and dense texture information from camera in a unified attention mechanism. Specifically, it first utilizes RoIPooling to obtain an image set with a unified size and gets the point set by sampling raw points within proposals in the RoI extraction step; then leverages an intra-modality self-attention to enhance the domain-specific features, following by a well-designed cross-attention to fuse the information from two modalities.FusionRCNN is fundamentally plug-and-play and supports different one-stage methods with almost no architectural changes. Extensive experiments on KITTI and Waymo benchmarks demonstrate that our method significantly boosts the performances of popular detectors.Remarkably, FusionRCNN significantly improves the strong SECOND baseline by 6.14% mAP on Waymo, and outperforms competing two-stage approaches. Code will be released soon at https://github.com/xxlbigbrother/Fusion-RCNN.