 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRUM: Fine-Grained Self-Rewarding for Unified Multimodal Models
Oct 14, 2025Recently, remarkable progress has been made in Unified Multimodal Models (UMMs), which integrate vision-language generation and understanding capabilities within a single framework. However, a significant gap exists where a model's strong visual understanding often fails to transfer to its visual generation. A model might correctly understand an image based on user instructions, yet be unable to generate a faithful image from text prompts. This phenomenon directly raises a compelling question: Can a model achieve self-improvement by using its understanding module to reward its generation module? To bridge this gap and achieve self-improvement, we introduce SRUM, a self-rewarding post-training framework that can be directly applied to existing UMMs of various designs. SRUM creates a feedback loop where the model's own understanding module acts as an internal ``evaluator'', providing corrective signals to improve its generation module, without requiring additional human-labeled data. To ensure this feedback is comprehensive, we designed a global-local dual reward system. To tackle the inherent structural complexity of images, this system offers multi-scale guidance: a \textbf{global reward} ensures the correctness of the overall visual semantics and layout, while a \textbf{local reward} refines fine-grained, object-level fidelity. SRUM leads to powerful capabilities and shows strong generalization, boosting performance on T2I-CompBench from 82.18 to \textbf{88.37} and on T2I-ReasonBench from 43.82 to \textbf{46.75}. Overall, our work establishes a powerful new paradigm for enabling a UMMs' understanding module to guide and enhance its own generation via self-rewarding.
FUDOKI: Discrete Flow-based Unified Understanding and Generation via Kinetic-Optimal Velocities
May 26, 2025The rapid progress of large language models (LLMs) has catalyzed the emergence of multimodal large language models (MLLMs) that unify visual understanding and image generation within a single framework. However, most existing MLLMs rely on autoregressive (AR) architectures, which impose inherent limitations on future development, such as the raster-scan order in image generation and restricted reasoning abilities in causal context modeling. In this work, we challenge the dominance of AR-based approaches by introducing FUDOKI, a unified multimodal model purely based on discrete flow matching, as an alternative to conventional AR paradigms. By leveraging metric-induced probability paths with kinetic optimal velocities, our framework goes beyond the previous masking-based corruption process, enabling iterative refinement with self-correction capability and richer bidirectional context integration during generation. To mitigate the high cost of training from scratch, we initialize FUDOKI from pre-trained AR-based MLLMs and adaptively transition to the discrete flow matching paradigm. Experimental results show that FUDOKI achieves performance comparable to state-of-the-art AR-based MLLMs across both visual understanding and image generation tasks, highlighting its potential as a foundation for next-generation unified multimodal models. Furthermore, we show that applying test-time scaling techniques to FUDOKI yields significant performance gains, further underscoring its promise for future enhancement through reinforcement learning.
Turbo2K: Towards Ultra-Efficient and High-Quality 2K Video Synthesis
Apr 20, 2025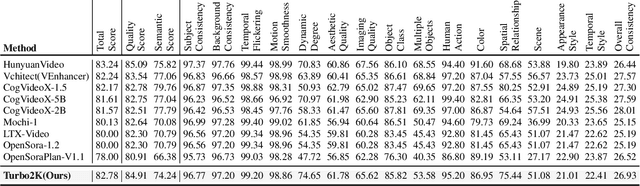

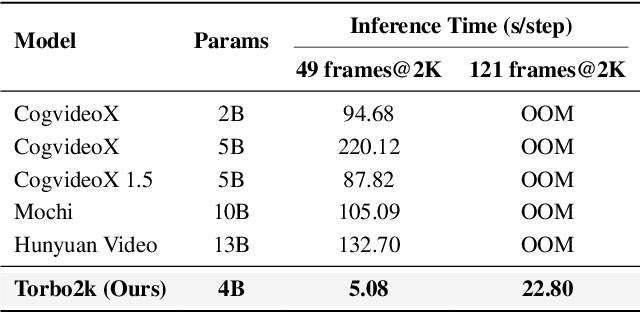

Demand for 2K video synthesis is rising with increasing consumer expectations for ultra-clear visuals. While diffusion transformers (DiTs) have demonstrated remarkable capabilities in high-quality video generation, scaling them to 2K resolution remains computationally prohibitive due to quadratic growth in memory and processing costs. In this work, we propose Turbo2K, an efficient and practical framework for generating detail-rich 2K videos while significantly improving training and inference efficiency. First, Turbo2K operates in a highly compressed latent space, reducing computational complexity and memory footprint, making high-resolution video synthesis feasible. However, the high compression ratio of the VAE and limited model size impose constraints on generative quality. To mitigate this, we introduce a knowledge distillation strategy that enables a smaller student model to inherit the generative capacity of a larger, more powerful teacher model. Our analysis reveals that, despite differences in latent spaces and architectures, DiTs exhibit structural similarities in their internal representations, facilitating effective knowledge transfer. Second, we design a hierarchical two-stage synthesis framework that first generates multi-level feature at lower resolutions before guiding high-resolution video generation. This approach ensures structural coherence and fine-grained detail refinement while eliminating redundant encoding-decoding overhead, further enhancing computational efficiency.Turbo2K achieves state-of-the-art efficiency, generating 5-second, 24fps, 2K videos with significantly reduced computational cost. Compared to existing methods, Turbo2K is up to 20$\times$ faster for inference, making high-resolution video generation more scalable and practical for real-world applications.
GenArtist: Multimodal LLM as an Agent for Unified Image Generation and Editing
Jul 08, 2024

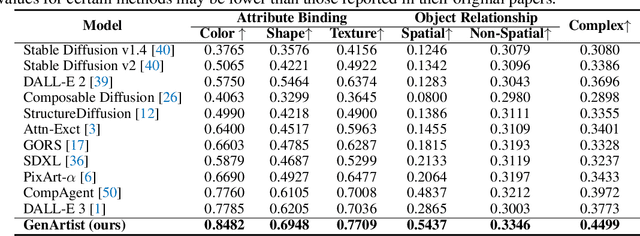
Despite the success achieved by existing image generation and editing methods, current models still struggle with complex problems including intricate text prompts, and the absence of verification and self-correction mechanisms makes the generated images unreliable. Meanwhile, a single model tends to specialize in particular tasks and possess the corresponding capabilities, making it inadequate for fulfilling all user requirements. We propose GenArtist, a unified image generation and editing system, coordinated by a multimodal large language model (MLLM) agent. We integrate a comprehensive range of existing models into the tool library and utilize the agent for tool selection and execution. For a complex problem, the MLLM agent decomposes it into simpler sub-problems and constructs a tree structure to systematically plan the procedure of generation, editing, and self-correction with step-by-step verification. By automatically generating missing position-related inputs and incorporating position information, the appropriate tool can be effectively employed to address each sub-problem. Experiments demonstrate that GenArtist can perform various generation and editing tasks, achieving state-of-the-art performance and surpassing existing models such as SDXL and DALL-E 3, as can be seen in Fig. 1. Project page is https://zhenyuw16.github.io/GenArtist_page.
Towards Understanding the Working Mechanism of Text-to-Image Diffusion Model
May 24, 2024Recently, the strong latent Diffusion Probabilistic Model (DPM) has been applied to high-quality Text-to-Image (T2I) generation (e.g., Stable Diffusion), by injecting the encoded target text prompt into the gradually denoised diffusion image generator. Despite the success of DPM in practice, the mechanism behind it remains to be explored. To fill this blank, we begin by examining the intermediate statuses during the gradual denoising generation process in DPM. The empirical observations indicate, the shape of image is reconstructed after the first few denoising steps, and then the image is filled with details (e.g., texture). The phenomenon is because the low-frequency signal (shape relevant) of the noisy image is not corrupted until the final stage in the forward process (initial stage of generation) of adding noise in DPM. Inspired by the observations, we proceed to explore the influence of each token in the text prompt during the two stages. After a series of experiments of T2I generations conditioned on a set of text prompts. We conclude that in the earlier generation stage, the image is mostly decided by the special token [\texttt{EOS}] in the text prompt, and the information in the text prompt is already conveyed in this stage. After that, the diffusion model completes the details of generated images by information from themselves. Finally, we propose to apply this observation to accelerate the process of T2I generation by properly removing text guidance, which finally accelerates the sampling up to 25\%+.
Enhancing Text-to-Image Editing via Hybrid Mask-Informed Fusion
May 24, 2024Recently, text-to-image (T2I) editing has been greatly pushed forward by applying diffusion models. Despite the visual promise of the generated images, inconsistencies with the expected textual prompt remain prevalent. This paper aims to systematically improve the text-guided image editing techniques based on diffusion models, by addressing their limitations. Notably, the common idea in diffusion-based editing firstly reconstructs the source image via inversion techniques e.g., DDIM Inversion. Then following a fusion process that carefully integrates the source intermediate (hidden) states (obtained by inversion) with the ones of the target image. Unfortunately, such a standard pipeline fails in many cases due to the interference of texture retention and the new characters creation in some regions. To mitigate this, we incorporate human annotation as an external knowledge to confine editing within a ``Mask-informed'' region. Then we carefully Fuse the edited image with the source image and a constructed intermediate image within the model's Self-Attention module. Extensive empirical results demonstrate the proposed ``MaSaFusion'' significantly improves the existing T2I editing techniques.
Open-Vocabulary Object Detection with Meta Prompt Representation and Instance Contrastive Optimization
Mar 14, 2024Classical object detectors are incapable of detecting novel class objects that are not encountered before. Regarding this issue, Open-Vocabulary Object Detection (OVOD) is proposed, which aims to detect the objects in the candidate class list. However, current OVOD models are suffering from overfitting on the base classes, heavily relying on the large-scale extra data, and complex training process. To overcome these issues, we propose a novel framework with Meta prompt and Instance Contrastive learning (MIC) schemes. Firstly, we simulate a novel-class-emerging scenario to help the prompt learner that learns class and background prompts generalize to novel classes. Secondly, we design an instance-level contrastive strategy to promote intra-class compactness and inter-class separation, which benefits generalization of the detector to novel class objects. Without using knowledge distillation, ensemble model or extra training data during detector training, our proposed MIC outperforms previous SOTA methods trained with these complex techniques on LVIS. Most importantly, MIC shows great generalization ability on novel classes, e.g., with $+4.3\%$ and $+1.9\% \ \mathrm{AP}$ improvement compared with previous SOTA on COCO and Objects365, respectively.
Efficient Transferability Assessment for Selection of Pre-trained Detectors
Mar 14, 2024Large-scale pre-training followed by downstream fine-tuning is an effective solution for transferring deep-learning-based models. Since finetuning all possible pre-trained models is computational costly, we aim to predict the transferability performance of these pre-trained models in a computational efficient manner. Different from previous work that seek out suitable models for downstream classification and segmentation tasks, this paper studies the efficient transferability assessment of pre-trained object detectors. To this end, we build up a detector transferability benchmark which contains a large and diverse zoo of pre-trained detectors with various architectures, source datasets and training schemes. Given this zoo, we adopt 7 target datasets from 5 diverse domains as the downstream target tasks for evaluation. Further, we propose to assess classification and regression sub-tasks simultaneously in a unified framework. Additionally, we design a complementary metric for evaluating tasks with varying objects. Experimental results demonstrate that our method outperforms other state-of-the-art approaches in assessing transferability under different target domains while efficiently reducing wall-clock time 32$\times$ and requires a mere 5.2\% memory footprint compared to brute-force fine-tuning of all pre-trained detectors.
Divide and Conquer: Language Models can Plan and Self-Correct for Compositional Text-to-Image Generation
Jan 30, 2024Despite significant advancements in text-to-image models for generating high-quality images, these methods still struggle to ensure the controllability of text prompts over images in the context of complex text prompts, especially when it comes to retaining object attributes and relationships. In this paper, we propose CompAgent, a training-free approach for compositional text-to-image generation, with a large language model (LLM) agent as its core. The fundamental idea underlying CompAgent is premised on a divide-and-conquer methodology. Given a complex text prompt containing multiple concepts including objects, attributes, and relationships, the LLM agent initially decomposes it, which entails the extraction of individual objects, their associated attributes, and the prediction of a coherent scene layout. These individual objects can then be independently conquered. Subsequently, the agent performs reasoning by analyzing the text, plans and employs the tools to compose these isolated objects. The verification and human feedback mechanism is finally incorporated into our agent to further correct the potential attribute errors and refine the generated images. Guided by the LLM agent, we propose a tuning-free multi-concept customization model and a layout-to-image generation model as the tools for concept composition, and a local image editing method as the tool to interact with the agent for verification. The scene layout controls the image generation process among these tools to prevent confusion among multiple objects. Extensive experiments demonstrate the superiority of our approach for compositional text-to-image generation: CompAgent achieves more than 10\% improvement on T2I-CompBench, a comprehensive benchmark for open-world compositional T2I generation. The extension to various related tasks also illustrates the flexibility of our CompAgent for potential applications.
CustomVideo: Customizing Text-to-Video Generation with Multiple Subjects
Jan 18, 2024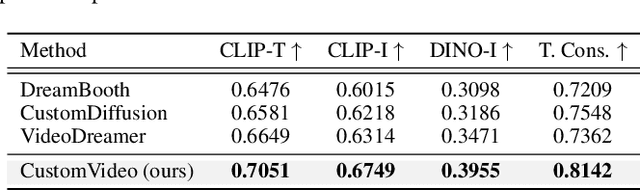
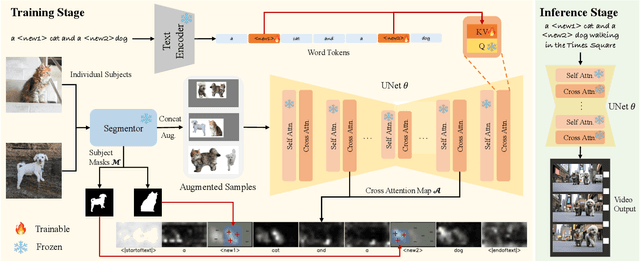
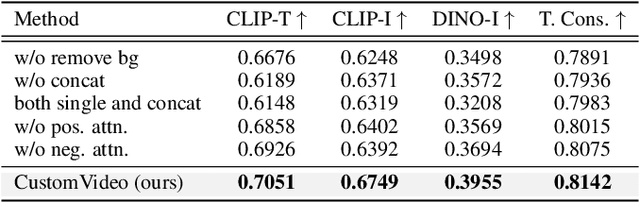

Customized text-to-video generation aims to generate high-quality videos guided by text prompts and subject references. Current approaches designed for single subjects suffer from tackling multiple subjects, which is a more challenging and practical scenario. In this work, we aim to promote multi-subject guided text-to-video customization. We propose CustomVideo, a novel framework that can generate identity-preserving videos with the guidance of multiple subjects. To be specific, firstly, we encourage the co-occurrence of multiple subjects via composing them in a single image. Further, upon a basic text-to-video diffusion model, we design a simple yet effective attention control strategy to disentangle different subjects in the latent space of diffusion model. Moreover, to help the model focus on the specific object area, we segment the object from given reference images and provide a corresponding object mask for attention learning. Also, we collect a multi-subject text-to-video generation dataset as a comprehensive benchmark, with 69 individual subjects and 57 meaningful pairs. Extensive qualitative, quantitative, and user study results demonstrate the superiority of our method, compared with the previous state-of-the-art approaches.