 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARD: Defending Harmful Fine-Tuning Attack via Safety Projection with Relevance-Diversity Data Selection
May 27, 2026Fine-tuning large language models often undermines their safety alignment, a problem further amplified by harmful fine-tuning attacks in which adversarial data removes safeguards and induces unsafe behaviors. We propose SPARD, a defense framework that integrates Safety-Projected Alternating optimization with Relevance-Diversity aware data selection. SPARD employs SPAG, which optimizes alternatively between utility updates and explicit safety projections with a set of safe data to enforce safety constraints. To curate safe data, we introduce a Relevance-Diversity Determinantal Point Process to select compact safe data, balancing task relevance and safety coverage. Experiments on GSM8K and OpenBookQA under four harmful fine-tuning attacks demonstrate that SPARD consistently achieves the lowest average attack success rates, substantially outperforming state-of-the-art defense methods, while maintaining high task accuracy. Code is available at https://github.com/shuhao02/SPARD.
RxEval: A Prescription-Level Benchmark for Evaluating LLM Medication Recommendation
May 14, 2026Inpatient medication recommendation requires clinicians to repeatedly select specific medications, doses, and routes as a patient's condition evolves. Existing benchmarks formulate this task as admission-level prediction over coarse drug codes with multi-hot diagnostic and procedure code inputs, failing to capture the per-timepoint, information-rich nature of real prescribing. We propose RxEval, a prescription-level benchmark that evaluates LLM prescribing capability by multiple-choice questions: each question presents a detailed patient profile and time-ordered clinical trajectory, requiring selection of specific medication-dose-route triples from real prescriptions and patient-specific distractors generated via reasoning-chain perturbation. RxEval comprises 1,547 questions spanning 584 patients, 18 diagnostic categories, and 969 unique medications. Evaluation of 16 LLMs shows that RxEval is both challenging and discriminative: F1 ranges from 45.18 to 77.10 across models, and the best Exact Match is only 46.10%. Error analysis reveals that even frontier models may overlook stated patient information and fail to derive clinical conclusions.
Harnessing Adaptive Topology Representations for Zero-Shot Graph Question Answering
Aug 08, 2025



Large Multimodal Models (LMMs) have shown generalized zero-shot capabilities in diverse domain question-answering (QA) tasks, including graph QA that involves complex graph topologies. However, most current approaches use only a single type of graph representation, namely Topology Representation Form (TRF), such as prompt-unified text descriptions or style-fixed visual styles. Those "one-size-fits-all" approaches fail to consider the specific preferences of different models or tasks, often leading to incorrect or overly long responses. To address this, we first analyze the characteristics and weaknesses of existing TRFs, and then design a set of TRFs, denoted by $F_{ZS}$, tailored to zero-shot graph QA. We then introduce a new metric, Graph Response Efficiency (GRE), which measures the balance between the performance and the brevity in graph QA. Built on these, we develop the DynamicTRF framework, which aims to improve both the accuracy and conciseness of graph QA. To be specific, DynamicTRF first creates a TRF Preference (TRFP) dataset that ranks TRFs based on their GRE scores, to probe the question-specific TRF preferences. Then it trains a TRF router on the TRFP dataset, to adaptively assign the best TRF from $F_{ZS}$ for each question during the inference. Extensive experiments across 7 in-domain algorithmic graph QA tasks and 2 out-of-domain downstream tasks show that DynamicTRF significantly enhances the zero-shot graph QA of LMMs in terms of accuracy
DynamicMind: A Tri-Mode Thinking System for Large Language Models
Jun 06, 2025


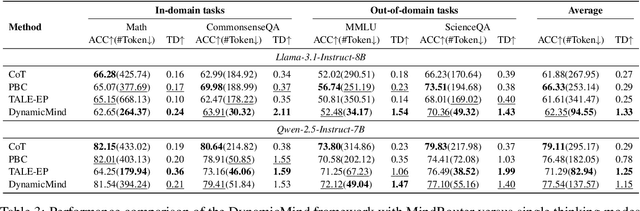
Modern large language models (LLMs) often struggle to dynamically adapt their reasoning depth to varying task complexities, leading to suboptimal performance or inefficient resource utilization. To address this, we introduce DynamicMind, a novel tri-mode thinking system. DynamicMind empowers LLMs to autonomously select between Fast, Normal, and Slow thinking modes for zero-shot question answering (ZSQA) tasks through cognitive-inspired prompt engineering. Our framework's core innovations include: (1) expanding the established dual-process framework of fast and slow thinking into a tri-mode thinking system involving a normal thinking mode to preserve the intrinsic capabilities of LLM; (2) proposing the Thinking Density metric, which aligns computational resource allocation with problem complexity; and (3) developing the Thinking Mode Capacity (TMC) dataset and a lightweight Mind Router to predict the optimal thinking mode. Extensive experiments across diverse mathematical, commonsense, and scientific QA benchmarks demonstrate that DynamicMind achieves superior ZSQA capabilities while establishing an effective trade-off between performance and computational efficiency.
Perceptual Decoupling for Scalable Multi-modal Reasoning via Reward-Optimized Captioning
Jun 05, 2025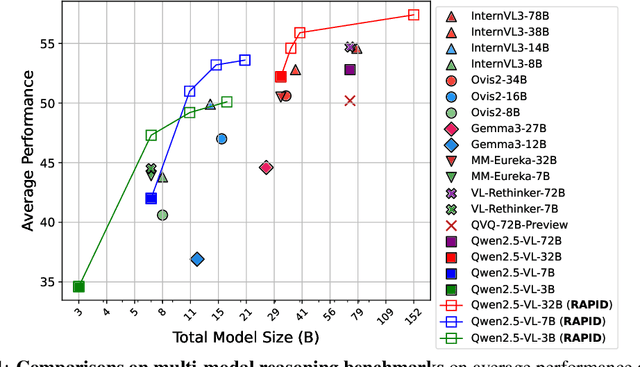
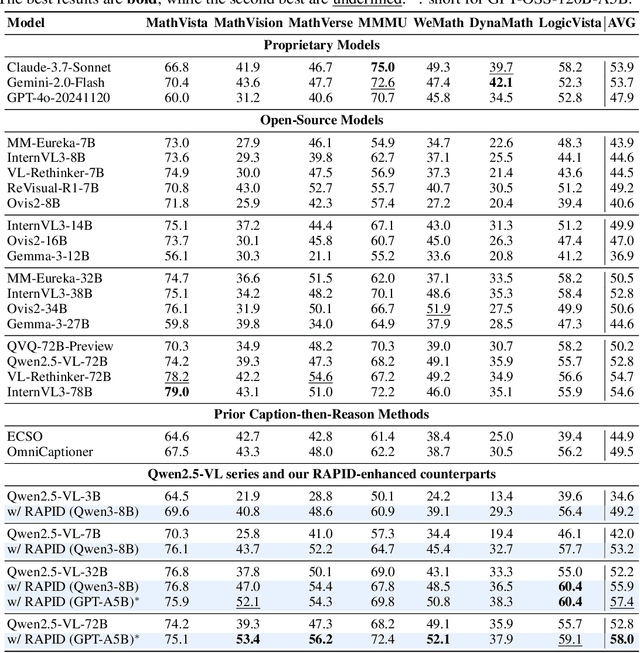
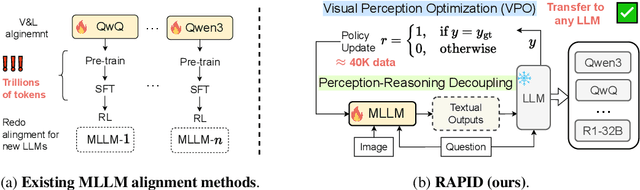
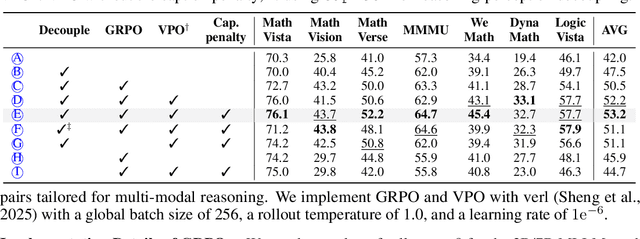
Recent advances in slow-thinking language models (e.g., OpenAI-o1 and DeepSeek-R1) have demonstrated remarkable abilities in complex reasoning tasks by emulating human-like reflective cognition. However, extending such capabilities to multi-modal large language models (MLLMs) remains challenging due to the high cost of retraining vision-language alignments when upgrading the underlying reasoner LLMs. A straightforward solution is to decouple perception from reasoning, i.e., converting visual inputs into language representations (e.g., captions) that are then passed to a powerful text-only reasoner. However, this decoupling introduces a critical challenge: the visual extractor must generate descriptions that are both faithful to the image and informative enough to support accurate downstream reasoning. To address this, we propose Reasoning-Aligned Perceptual Decoupling via Caption Reward Optimization (RACRO) - a reasoning-guided reinforcement learning strategy that aligns the extractor's captioning behavior with the reasoning objective. By closing the perception-reasoning loop via reward-based optimization, RACRO significantly enhances visual grounding and extracts reasoning-optimized representations. Experiments on multi-modal math and science benchmarks show that the proposed RACRO method achieves state-of-the-art average performance while enabling superior scalability and plug-and-play adaptation to more advanced reasoning LLMs without the necessity for costly multi-modal re-alignment.
Multi-Order Wavelet Derivative Transform for Deep Time Series Forecasting
May 17, 2025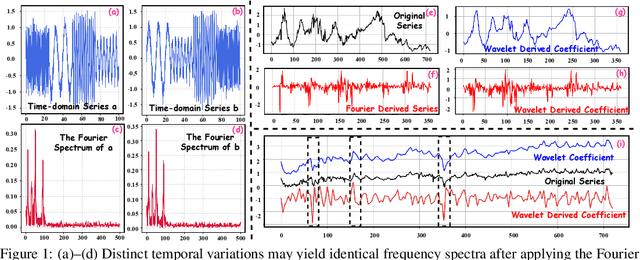
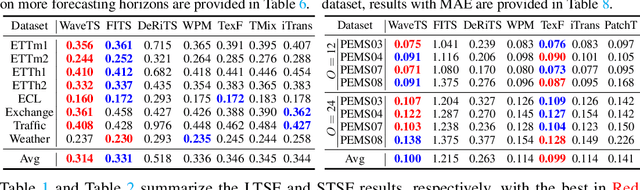
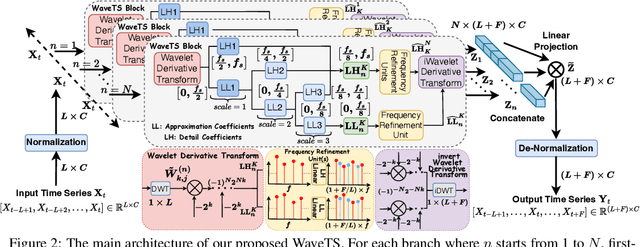
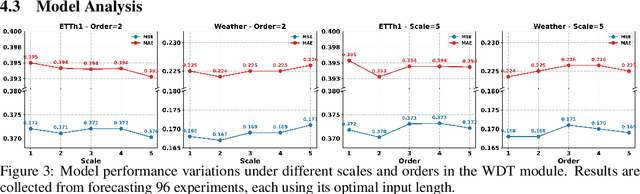
In deep time series forecasting, the Fourier Transform (FT) is extensively employed for frequency representation learning. However, it often struggles in capturing multi-scale, time-sensitive patterns. Although the Wavelet Transform (WT) can capture these patterns through frequency decomposition, its coefficients are insensitive to change points in time series, leading to suboptimal modeling. To mitigate these limitations, we introduce the multi-order Wavelet Derivative Transform (WDT) grounded in the WT, enabling the extraction of time-aware patterns spanning both the overall trend and subtle fluctuations. Compared with the standard FT and WT, which model the raw series, the WDT operates on the derivative of the series, selectively magnifying rate-of-change cues and exposing abrupt regime shifts that are particularly informative for time series modeling. Practically, we embed the WDT into a multi-branch framework named WaveTS, which decomposes the input series into multi-scale time-frequency coefficients, refines them via linear layers, and reconstructs them into the time domain via the inverse WDT. Extensive experiments on ten benchmark datasets demonstrate that WaveTS achieves state-of-the-art forecasting accuracy while retaining high computational efficiency.
Corrupted but Not Broken: Rethinking the Impact of Corrupted Data in Visual Instruction Tuning
Feb 18, 2025Visual Instruction Tuning (VIT) enhances Multimodal Large Language Models (MLLMs) but it is hindered by corrupted datasets containing hallucinated content, incorrect responses, and poor OCR quality. While prior works focus on dataset refinement through high-quality data collection or rule-based filtering, they are costly or limited to specific types of corruption. To deeply understand how corrupted data affects MLLMs, in this paper, we systematically investigate this issue and find that while corrupted data degrades the performance of MLLMs, its effects are largely superficial in that the performance of MLLMs can be largely restored by either disabling a small subset of parameters or post-training with a small amount of clean data. Additionally, corrupted MLLMs exhibit improved ability to distinguish clean samples from corrupted ones, enabling the dataset cleaning without external help. Based on those insights, we propose a corruption-robust training paradigm combining self-validation and post-training, which significantly outperforms existing corruption mitigation strategies.
Gradient-Based Multi-Objective Deep Learning: Algorithms, Theories, Applications, and Beyond
Jan 19, 2025



Multi-objective optimization (MOO) in deep learning aims to simultaneously optimize multiple conflicting objectives, a challenge frequently encountered in areas like multi-task learning and multi-criteria learning. Recent advancements in gradient-based MOO methods have enabled the discovery of diverse types of solutions, ranging from a single balanced solution to finite or even infinite Pareto sets, tailored to user needs. These developments have broad applications across domains such as reinforcement learning, computer vision, recommendation systems, and large language models. This survey provides the first comprehensive review of gradient-based MOO in deep learning, covering algorithms, theories, and practical applications. By unifying various approaches and identifying critical challenges, it serves as a foundational resource for driving innovation in this evolving field. A comprehensive list of MOO algorithms in deep learning is available at \url{https://github.com/Baijiong-Lin/Awesome-Multi-Objective-Deep-Learning}.
RouterDC: Query-Based Router by Dual Contrastive Learning for Assembling Large Language Models
Sep 30, 2024



Recent works show that assembling multiple off-the-shelf large language models (LLMs) can harness their complementary abilities. To achieve this, routing is a promising method, which learns a router to select the most suitable LLM for each query. However, existing routing models are ineffective when multiple LLMs perform well for a query. To address this problem, in this paper, we propose a method called query-based Router by Dual Contrastive learning (RouterDC). The RouterDC model consists of an encoder and LLM embeddings, and we propose two contrastive learning losses to train the RouterDC model. Experimental results show that RouterDC is effective in assembling LLMs and largely outperforms individual top-performing LLMs as well as existing routing methods on both in-distribution (+2.76\%) and out-of-distribution (+1.90\%) tasks. Source code is available at https://github.com/shuhao02/RouterDC.
EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions
Sep 26, 2024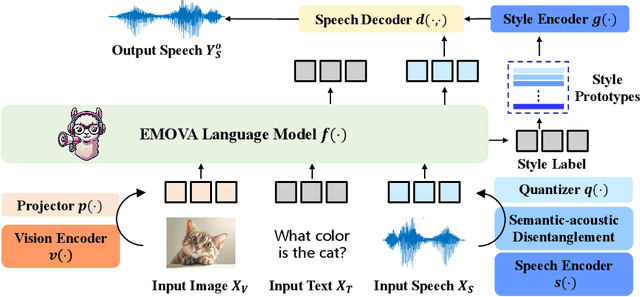
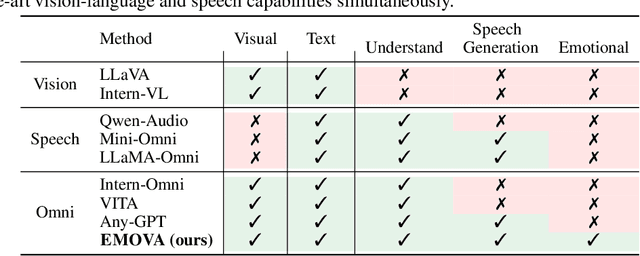
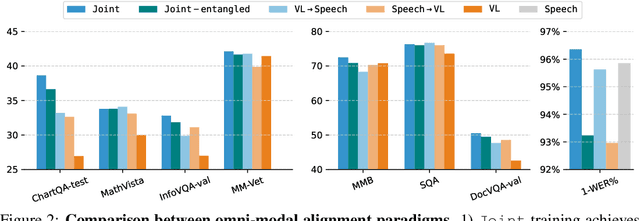

GPT-4o, an omni-modal model that enables vocal conversations with diverse emotions and tones, marks a milestone for omni-modal foundation models. However, empowering Large Language Models to perceive and generate images, texts, and speeches end-to-end with publicly available data remains challenging in the open-source community. Existing vision-language models rely on external tools for the speech processing, while speech-language models still suffer from limited or even without vision-understanding abilities. To address this gap, we propose EMOVA (EMotionally Omni-present Voice Assistant), to enable Large Language Models with end-to-end speech capabilities while maintaining the leading vision-language performance. With a semantic-acoustic disentangled speech tokenizer, we notice surprisingly that omni-modal alignment can further enhance vision-language and speech abilities compared with the corresponding bi-modal aligned counterparts. Moreover, a lightweight style module is proposed for flexible speech style controls (e.g., emotions and pitches). For the first time, EMOVA achieves state-of-the-art performance on both the vision-language and speech benchmarks, and meanwhile, supporting omni-modal spoken dialogue with vivid emotions.