 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamicMind: A Tri-Mode Thinking System for Large Language Models
Jun 06, 2025


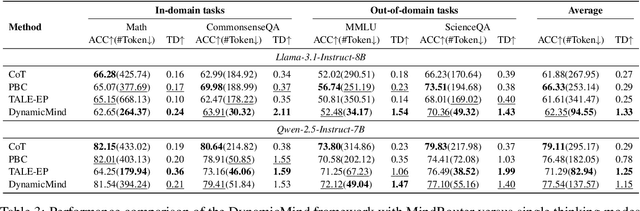
Modern large language models (LLMs) often struggle to dynamically adapt their reasoning depth to varying task complexities, leading to suboptimal performance or inefficient resource utilization. To address this, we introduce DynamicMind, a novel tri-mode thinking system. DynamicMind empowers LLMs to autonomously select between Fast, Normal, and Slow thinking modes for zero-shot question answering (ZSQA) tasks through cognitive-inspired prompt engineering. Our framework's core innovations include: (1) expanding the established dual-process framework of fast and slow thinking into a tri-mode thinking system involving a normal thinking mode to preserve the intrinsic capabilities of LLM; (2) proposing the Thinking Density metric, which aligns computational resource allocation with problem complexity; and (3) developing the Thinking Mode Capacity (TMC) dataset and a lightweight Mind Router to predict the optimal thinking mode. Extensive experiments across diverse mathematical, commonsense, and scientific QA benchmarks demonstrate that DynamicMind achieves superior ZSQA capabilities while establishing an effective trade-off between performance and computational efficiency.
Come Together, But Not Right Now: A Progressive Strategy to Boost Low-Rank Adaptation
Jun 06, 2025Low-rank adaptation (LoRA) has emerged as a leading parameter-efficient fine-tuning technique for adapting large foundation models, yet it often locks adapters into suboptimal minima near their initialization. This hampers model generalization and limits downstream operators such as adapter merging and pruning. Here, we propose CoTo, a progressive training strategy that gradually increases adapters' activation probability over the course of fine-tuning. By stochastically deactivating adapters, CoTo encourages more balanced optimization and broader exploration of the loss landscape. We provide a theoretical analysis showing that CoTo promotes layer-wise dropout stability and linear mode connectivity, and we adopt a cooperative-game approach to quantify each adapter's marginal contribution. Extensive experiments demonstrate that CoTo consistently boosts single-task performance, enhances multi-task merging accuracy, improves pruning robustness, and reduces training overhead, all while remaining compatible with diverse LoRA variants. Code is available at https://github.com/zwebzone/coto.
Nemesis: Normalizing the Soft-prompt Vectors of Vision-Language Models
Aug 26, 2024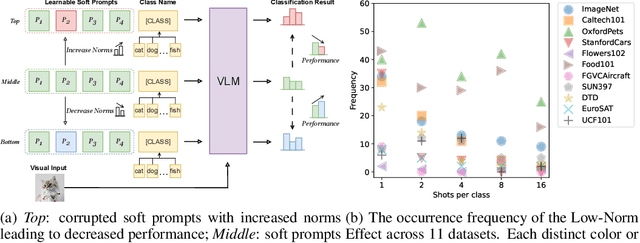
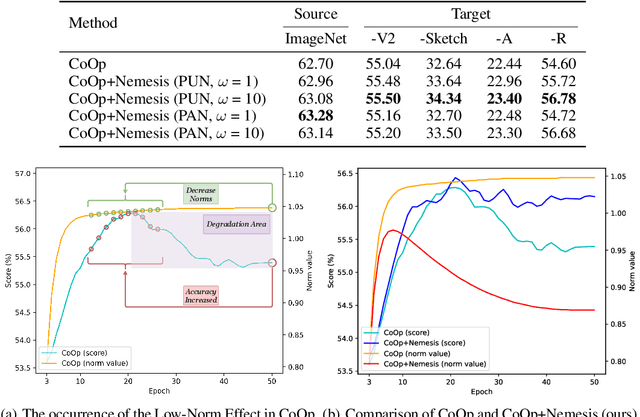
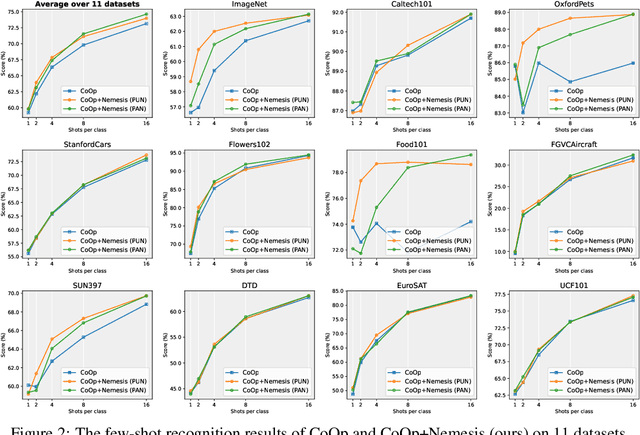
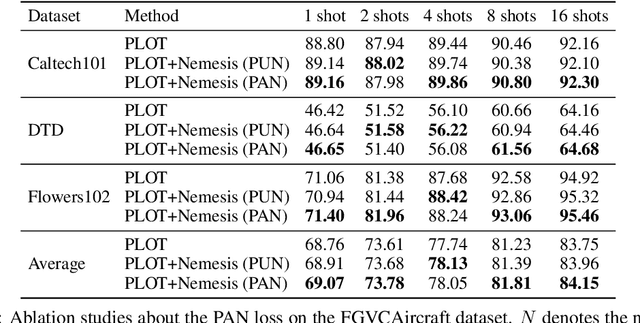
With the prevalence of large-scale pretrained vision-language models (VLMs), such as CLIP, soft-prompt tuning has become a popular method for adapting these models to various downstream tasks. However, few works delve into the inherent properties of learnable soft-prompt vectors, specifically the impact of their norms to the performance of VLMs. This motivates us to pose an unexplored research question: ``Do we need to normalize the soft prompts in VLMs?'' To fill this research gap, we first uncover a phenomenon, called the \textbf{Low-Norm Effect} by performing extensive corruption experiments, suggesting that reducing the norms of certain learned prompts occasionally enhances the performance of VLMs, while increasing them often degrades it. To harness this effect, we propose a novel method named \textbf{N}ormalizing th\textbf{e} soft-pro\textbf{m}pt v\textbf{e}ctors of vi\textbf{si}on-language model\textbf{s} (\textbf{Nemesis}) to normalize soft-prompt vectors in VLMs. To the best of our knowledge, our work is the first to systematically investigate the role of norms of soft-prompt vector in VLMs, offering valuable insights for future research in soft-prompt tuning. The code is available at \texttt{\href{https://github.com/ShyFoo/Nemesis}{https://github.com/ShyFoo/Nemesis}}.
Learning Retrieval Augmentation for Personalized Dialogue Generation
Jun 27, 2024Personalized dialogue generation, focusing on generating highly tailored responses by leveraging persona profiles and dialogue context, has gained significant attention in conversational AI applications. However, persona profiles, a prevalent setting in current personalized dialogue datasets, typically composed of merely four to five sentences, may not offer comprehensive descriptions of the persona about the agent, posing a challenge to generate truly personalized dialogues. To handle this problem, we propose $\textbf{L}$earning Retrieval $\textbf{A}$ugmentation for $\textbf{P}$ersonalized $\textbf{D}$ial$\textbf{O}$gue $\textbf{G}$eneration ($\textbf{LAPDOG}$), which studies the potential of leveraging external knowledge for persona dialogue generation. Specifically, the proposed LAPDOG model consists of a story retriever and a dialogue generator. The story retriever uses a given persona profile as queries to retrieve relevant information from the story document, which serves as a supplementary context to augment the persona profile. The dialogue generator utilizes both the dialogue history and the augmented persona profile to generate personalized responses. For optimization, we adopt a joint training framework that collaboratively learns the story retriever and dialogue generator, where the story retriever is optimized towards desired ultimate metrics (e.g., BLEU) to retrieve content for the dialogue generator to generate personalized responses. Experiments conducted on the CONVAI2 dataset with ROCStory as a supplementary data source show that the proposed LAPDOG method substantially outperforms the baselines, indicating the effectiveness of the proposed method. The LAPDOG model code is publicly available for further exploration. https://github.com/hqsiswiliam/LAPDOG
Selective Prompting Tuning for Personalized Conversations with LLMs
Jun 26, 2024In conversational AI, personalizing dialogues with persona profiles and contextual understanding is essential. Despite large language models' (LLMs) improved response coherence, effective persona integration remains a challenge. In this work, we first study two common approaches for personalizing LLMs: textual prompting and direct fine-tuning. We observed that textual prompting often struggles to yield responses that are similar to the ground truths in datasets, while direct fine-tuning tends to produce repetitive or overly generic replies. To alleviate those issues, we propose \textbf{S}elective \textbf{P}rompt \textbf{T}uning (SPT), which softly prompts LLMs for personalized conversations in a selective way. Concretely, SPT initializes a set of soft prompts and uses a trainable dense retriever to adaptively select suitable soft prompts for LLMs according to different input contexts, where the prompt retriever is dynamically updated through feedback from the LLMs. Additionally, we propose context-prompt contrastive learning and prompt fusion learning to encourage the SPT to enhance the diversity of personalized conversations. Experiments on the CONVAI2 dataset demonstrate that SPT significantly enhances response diversity by up to 90\%, along with improvements in other critical performance indicators. Those results highlight the efficacy of SPT in fostering engaging and personalized dialogue generation. The SPT model code (https://github.com/hqsiswiliam/SPT) is publicly available for further exploration.
SMP Challenge: An Overview and Analysis of Social Media Prediction Challenge
May 17, 2024



Social Media Popularity Prediction (SMPP) is a crucial task that involves automatically predicting future popularity values of online posts, leveraging vast amounts of multimodal data available on social media platforms. Studying and investigating social media popularity becomes central to various online applications and requires novel methods of comprehensive analysis, multimodal comprehension, and accurate prediction. SMP Challenge is an annual research activity that has spurred academic exploration in this area. This paper summarizes the challenging task, data, and research progress. As a critical resource for evaluating and benchmarking predictive models, we have released a large-scale SMPD benchmark encompassing approximately half a million posts authored by around 70K users. The research progress analysis provides an overall analysis of the solutions and trends in recent years. The SMP Challenge website (www.smp-challenge.com) provides the latest information and news.
KICGPT: Large Language Model with Knowledge in Context for Knowledge Graph Completion
Feb 04, 2024



Knowledge Graph Completion (KGC) is crucial for addressing knowledge graph incompleteness and supporting downstream applications. Many models have been proposed for KGC. They can be categorized into two main classes: triple-based and text-based approaches. Triple-based methods struggle with long-tail entities due to limited structural information and imbalanced entity distributions. Text-based methods alleviate this issue but require costly training for language models and specific finetuning for knowledge graphs, which limits their efficiency. To alleviate these limitations, in this paper, we propose KICGPT, a framework that integrates a large language model (LLM) and a triple-based KGC retriever. It alleviates the long-tail problem without incurring additional training overhead. KICGPT uses an in-context learning strategy called Knowledge Prompt, which encodes structural knowledge into demonstrations to guide the LLM. Empirical results on benchmark datasets demonstrate the effectiveness of KICGPT with smaller training overhead and no finetuning.
Retrieval-Augmented Text-to-Audio Generation
Sep 14, 2023Despite recent progress in text-to-audio (TTA) generation, we show that the state-of-the-art models, such as AudioLDM, trained on datasets with an imbalanced class distribution, such as AudioCaps, are biased in their generation performance. Specifically, they excel in generating common audio classes while underperforming in the rare ones, thus degrading the overall generation performance. We refer to this problem as long-tailed text-to-audio generation. To address this issue, we propose a simple retrieval-augmented approach for TTA models. Specifically, given an input text prompt, we first leverage a Contrastive Language Audio Pretraining (CLAP) model to retrieve relevant text-audio pairs. The features of the retrieved audio-text data are then used as additional conditions to guide the learning of TTA models. We enhance AudioLDM with our proposed approach and denote the resulting augmented system as Re-AudioLDM. On the AudioCaps dataset, Re-AudioLDM achieves a state-of-the-art Frechet Audio Distance (FAD) of 1.37, outperforming the existing approaches by a large margin. Furthermore, we show that Re-AudioLDM can generate realistic audio for complex scenes, rare audio classes, and even unseen audio types, indicating its potential in TTA tasks.
WavJourney: Compositional Audio Creation with Large Language Models
Jul 26, 2023Large Language Models (LLMs) have shown great promise in integrating diverse expert models to tackle intricate language and vision tasks. Despite their significance in advancing the field of Artificial Intelligence Generated Content (AIGC), their potential in intelligent audio content creation remains unexplored. In this work, we tackle the problem of creating audio content with storylines encompassing speech, music, and sound effects, guided by text instructions. We present WavJourney, a system that leverages LLMs to connect various audio models for audio content generation. Given a text description of an auditory scene, WavJourney first prompts LLMs to generate a structured script dedicated to audio storytelling. The audio script incorporates diverse audio elements, organized based on their spatio-temporal relationships. As a conceptual representation of audio, the audio script provides an interactive and interpretable rationale for human engagement. Afterward, the audio script is fed into a script compiler, converting it into a computer program. Each line of the program calls a task-specific audio generation model or computational operation function (e.g., concatenate, mix). The computer program is then executed to obtain an explainable solution for audio generation. We demonstrate the practicality of WavJourney across diverse real-world scenarios, including science fiction, education, and radio play. The explainable and interactive design of WavJourney fosters human-machine co-creation in multi-round dialogues, enhancing creative control and adaptability in audio production. WavJourney audiolizes the human imagination, opening up new avenues for creativity in multimedia content creation.
Visually-Aware Audio Captioning With Adaptive Audio-Visual Attention
Oct 28, 2022Audio captioning is the task of generating captions that describe the content of audio clips. In the real world, many objects produce similar sounds. It is difficult to identify these auditory ambiguous sound events with access to audio information only. How to accurately recognize ambiguous sounds is a major challenge for audio captioning systems. In this work, inspired by the audio-visual multi-modal perception of human beings, we propose visually-aware audio captioning, which makes use of visual information to help the recognition of ambiguous sounding objects. Specifically, we introduce an off-the-shelf visual encoder to process the video inputs, and incorporate the extracted visual features into an audio captioning system. Furthermore, to better exploit complementary contexts from redundant audio-visual streams, we propose an audio-visual attention mechanism that integrates audio and visual information adaptively according to their confidence levels. Experimental results on AudioCaps, the largest publicly available audio captioning dataset, show that the proposed method achieves significant improvement over a strong baseline audio captioning system and is on par with the state-of-the-art result.