 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindClaw: Closed-Loop Embodied Mental-State Reasoning for Precision Intervention
May 31, 2026Theory of Mind (ToM) enables an agent to reason about another actor's beliefs, goals, and intentions, which is essential for human-centered embodied assistance. Existing ToM benchmarks have advanced text and multimodal mental-state recognition, but they mostly evaluate offline question answering or final action prediction. They do not fully test whether an embodied agent can stay connected to a changing environment, update actor-specific beliefs, decide when reasoning is needed, and intervene only when help is useful. Building on MindPower, we extend robot-centric ToM reasoning to a real-time closed-loop setting and introduce MindClaw, a framework for embodied mental-state reasoning with precision intervention. MindClaw connects multi-source inputs, belief memory, an embodied cognitive trigger skill, mental reasoning, and action generation, allowing the agent to output helpful actions at the right time while remaining silent when intervention is unnecessary. Experiments show that direct VLM baselines struggle with task awareness and intervention calibration, while MindClaw achieves the best overall performance, demonstrating the importance of trigger-skill optimization for closed-loop embodied ToM assistance.
PinpointQA: A Dataset and Benchmark for Small Object-Centric Spatial Understanding in Indoor Videos
Apr 10, 2026Small object-centric spatial understanding in indoor videos remains a significant challenge for multimodal large language models (MLLMs), despite its practical value for object search and assistive applications. Although existing benchmarks have advanced video spatial intelligence, embodied reasoning, and diagnostic perception, no existing benchmark directly evaluates whether a model can localize a target object in video and express its position with sufficient precision for downstream use. In this work, we introduce PinpointQA, the first dataset and benchmark for small object-centric spatial understanding in indoor videos. Built from ScanNet++ and ScanNet200, PinpointQA comprises 1,024 scenes and 10,094 QA pairs organized into four progressively challenging tasks: Target Presence Verification (TPV), Nearest Reference Identification (NRI), Fine-Grained Spatial Description (FSD), and Structured Spatial Prediction (SSP). The dataset is built from intermediate spatial representations, with QA pairs generated automatically and further refined through quality control. Experiments on representative MLLMs reveal a consistent capability gap along the progressive chain, with SSP remaining particularly difficult. Supervised fine-tuning on PinpointQA yields substantial gains, especially on the harder tasks, demonstrating that PinpointQA serves as both a diagnostic benchmark and an effective training dataset. The dataset and project page are available at https://rainchowz.github.io/PinpointQA.
One Pool Is Not Enough: Multi-Cluster Memory for Practical Test-Time Adaptation
Mar 22, 2026Test-time adaptation (TTA) adapts pre-trained models to distribution shifts at inference using only unlabeled test data. Under the Practical TTA (PTTA) setting, where test streams are temporally correlated and non-i.i.d., memory has become an indispensable component for stable adaptation, yet existing methods universally store amples in a single unstructured pool. We show that this single-cluster design is fundamentally mismatched to PTTA: a stream clusterability analysis reveals that test streams are inherently multi-modal, with the optimal number of mixture components consistently far exceeding one. To close this structural gap, we propose Multi-Cluster Memory (MCM), a plug-and-play framework that organizes stored samples into multiple clusters using lightweight pixel-level statistical descriptors. MCM introduces three complementary mechanisms: descriptor-based cluster assignment to capture distinct distributional modes, Adjacent Cluster Consolidation (ACC) to bound memory usage by merging the most similar temporally adjacent clusters, and Uniform Cluster Retrieval (UCR) to ensure balanced supervision across all modes during adaptation. Integrated with three contemporary TTA methods on CIFAR-10-C, CIFAR-100-C, ImageNet-C, and DomainNet, MCM achieves consistent improvements across all 12 configurations, with gains up to 5.00% on ImageNet-C and 12.13% on DomainNet. Notably, these gains scale with distributional complexity: larger label spaces with greater multi-modality benefit most from multi-cluster organization. GMM-based memory diagnostics further confirm that MCM maintains near-optimal distributional balance, entropy, and mode coverage, whereas single-cluster memory exhibits persistent imbalance and progressive mode loss. These results establish memory organization as a key design axis for practical test-time adaptation.
TriDF: Evaluating Perception, Detection, and Hallucination for Interpretable DeepFake Detection
Dec 23, 2025Advances in generative modeling have made it increasingly easy to fabricate realistic portrayals of individuals, creating serious risks for security, communication, and public trust. Detecting such person-driven manipulations requires systems that not only distinguish altered content from authentic media but also provide clear and reliable reasoning. In this paper, we introduce TriDF, a comprehensive benchmark for interpretable DeepFake detection. TriDF contains high-quality forgeries from advanced synthesis models, covering 16 DeepFake types across image, video, and audio modalities. The benchmark evaluates three key aspects: Perception, which measures the ability of a model to identify fine-grained manipulation artifacts using human-annotated evidence; Detection, which assesses classification performance across diverse forgery families and generators; and Hallucination, which quantifies the reliability of model-generated explanations. Experiments on state-of-the-art multimodal large language models show that accurate perception is essential for reliable detection, but hallucination can severely disrupt decision-making, revealing the interdependence of these three aspects. TriDF provides a unified framework for understanding the interaction between detection accuracy, evidence identification, and explanation reliability, offering a foundation for building trustworthy systems that address real-world synthetic media threats.
Relightable and Dynamic Gaussian Avatar Reconstruction from Monocular Video
Dec 11, 2025Modeling relightable and animatable human avatars from monocular video is a long-standing and challenging task. Recently, Neural Radiance Field (NeRF) and 3D Gaussian Splatting (3DGS) methods have been employed to reconstruct the avatars. However, they often produce unsatisfactory photo-realistic results because of insufficient geometrical details related to body motion, such as clothing wrinkles. In this paper, we propose a 3DGS-based human avatar modeling framework, termed as Relightable and Dynamic Gaussian Avatar (RnD-Avatar), that presents accurate pose-variant deformation for high-fidelity geometrical details. To achieve this, we introduce dynamic skinning weights that define the human avatar's articulation based on pose while also learning additional deformations induced by body motion. We also introduce a novel regularization to capture fine geometric details under sparse visual cues. Furthermore, we present a new multi-view dataset with varied lighting conditions to evaluate relight. Our framework enables realistic rendering of novel poses and views while supporting photo-realistic lighting effects under arbitrary lighting conditions. Our method achieves state-of-the-art performance in novel view synthesis, novel pose rendering, and relighting.
* 8 pages, 9 figures, published in ACM MM 2025
InstructFLIP: Exploring Unified Vision-Language Model for Face Anti-spoofing
Jul 16, 2025Face anti-spoofing (FAS) aims to construct a robust system that can withstand diverse attacks. While recent efforts have concentrated mainly on cross-domain generalization, two significant challenges persist: limited semantic understanding of attack types and training redundancy across domains. We address the first by integrating vision-language models (VLMs) to enhance the perception of visual input. For the second challenge, we employ a meta-domain strategy to learn a unified model that generalizes well across multiple domains. Our proposed InstructFLIP is a novel instruction-tuned framework that leverages VLMs to enhance generalization via textual guidance trained solely on a single domain. At its core, InstructFLIP explicitly decouples instructions into content and style components, where content-based instructions focus on the essential semantics of spoofing, and style-based instructions consider variations related to the environment and camera characteristics. Extensive experiments demonstrate the effectiveness of InstructFLIP by outperforming SOTA models in accuracy and substantially reducing training redundancy across diverse domains in FAS. Project website is available at https://kunkunlin1221.github.io/InstructFLIP.
MEGC2025: Micro-Expression Grand Challenge on Spot Then Recognize and Visual Question Answering
Jun 18, 2025
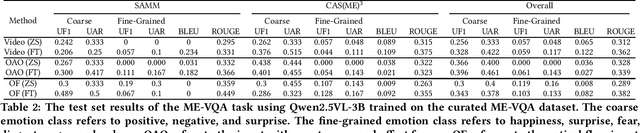
Facial micro-expressions (MEs) are involuntary movements of the face that occur spontaneously when a person experiences an emotion but attempts to suppress or repress the facial expression, typically found in a high-stakes environment. In recent years, substantial advancements have been made in the areas of ME recognition, spotting, and generation. However, conventional approaches that treat spotting and recognition as separate tasks are suboptimal, particularly for analyzing long-duration videos in realistic settings. Concurrently, the emergence of multimodal large language models (MLLMs) and large vision-language models (LVLMs) offers promising new avenues for enhancing ME analysis through their powerful multimodal reasoning capabilities. The ME grand challenge (MEGC) 2025 introduces two tasks that reflect these evolving research directions: (1) ME spot-then-recognize (ME-STR), which integrates ME spotting and subsequent recognition in a unified sequential pipeline; and (2) ME visual question answering (ME-VQA), which explores ME understanding through visual question answering, leveraging MLLMs or LVLMs to address diverse question types related to MEs. All participating algorithms are required to run on this test set and submit their results on a leaderboard. More details are available at https://megc2025.github.io.
RecipeGen: A Step-Aligned Multimodal Benchmark for Real-World Recipe Generation
Jun 07, 2025



Creating recipe images is a key challenge in food computing, with applications in culinary education and multimodal recipe assistants. However, existing datasets lack fine-grained alignment between recipe goals, step-wise instructions, and visual content. We present RecipeGen, the first large-scale, real-world benchmark for recipe-based Text-to-Image (T2I), Image-to-Video (I2V), and Text-to-Video (T2V) generation. RecipeGen contains 26,453 recipes, 196,724 images, and 4,491 videos, covering diverse ingredients, cooking procedures, styles, and dish types. We further propose domain-specific evaluation metrics to assess ingredient fidelity and interaction modeling, benchmark representative T2I, I2V, and T2V models, and provide insights for future recipe generation models. Project page is available now.
Swapped Logit Distillation via Bi-level Teacher Alignment
Apr 27, 2025Knowledge distillation (KD) compresses the network capacity by transferring knowledge from a large (teacher) network to a smaller one (student). It has been mainstream that the teacher directly transfers knowledge to the student with its original distribution, which can possibly lead to incorrect predictions. In this article, we propose a logit-based distillation via swapped logit processing, namely Swapped Logit Distillation (SLD). SLD is proposed under two assumptions: (1) the wrong prediction occurs when the prediction label confidence is not the maximum; (2) the "natural" limit of probability remains uncertain as the best value addition to the target cannot be determined. To address these issues, we propose a swapped logit processing scheme. Through this approach, we find that the swap method can be effectively extended to teacher and student outputs, transforming into two teachers. We further introduce loss scheduling to boost the performance of two teachers' alignment. Extensive experiments on image classification tasks demonstrate that SLD consistently performs best among previous state-of-the-art methods.
Single Document Image Highlight Removal via A Large-Scale Real-World Dataset and A Location-Aware Network
Apr 19, 2025


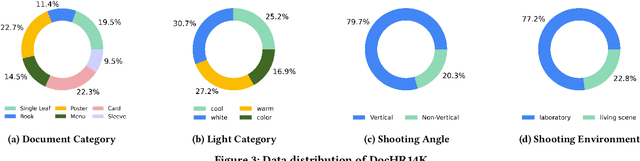
Reflective documents often suffer from specular highlights under ambient lighting, severely hindering text readability and degrading overall visual quality. Although recent deep learning methods show promise in highlight removal, they remain suboptimal for document images, primarily due to the lack of dedicated datasets and tailored architectural designs. To tackle these challenges, we present DocHR14K, a large-scale real-world dataset comprising 14,902 high-resolution image pairs across six document categories and various lighting conditions. To the best of our knowledge, this is the first high-resolution dataset for document highlight removal that captures a wide range of real-world lighting conditions. Additionally, motivated by the observation that the residual map between highlighted and clean images naturally reveals the spatial structure of highlight regions, we propose a simple yet effective Highlight Location Prior (HLP) to estimate highlight masks without human annotations. Building on this prior, we present the Location-Aware Laplacian Pyramid Highlight Removal Network (L2HRNet), which effectively removes highlights by leveraging estimated priors and incorporates diffusion module to restore details. Extensive experiments demonstrate that DocHR14K improves highlight removal under diverse lighting conditions. Our L2HRNet achieves state-of-the-art performance across three benchmark datasets, including a 5.01\% increase in PSNR and a 13.17\% reduction in RMSE on DocHR14K.