 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForeground Focus: Enhancing Coherence and Fidelity in Camouflaged Image Generation
Apr 02, 2025Camouflaged image generation is emerging as a solution to data scarcity in camouflaged vision perception, offering a cost-effective alternative to data collection and labeling. Recently, the state-of-the-art approach successfully generates camouflaged images using only foreground objects. However, it faces two critical weaknesses: 1) the background knowledge does not integrate effectively with foreground features, resulting in a lack of foreground-background coherence (e.g., color discrepancy); 2) the generation process does not prioritize the fidelity of foreground objects, which leads to distortion, particularly for small objects. To address these issues, we propose a Foreground-Aware Camouflaged Image Generation (FACIG) model. Specifically, we introduce a Foreground-Aware Feature Integration Module (FAFIM) to strengthen the integration between foreground features and background knowledge. In addition, a Foreground-Aware Denoising Loss is designed to enhance foreground reconstruction supervision. Experiments on various datasets show our method outperforms previous methods in overall camouflaged image quality and foreground fidelity.
EmoVIT: Revolutionizing Emotion Insights with Visual Instruction Tuning
Apr 25, 2024Visual Instruction Tuning represents a novel learning paradigm involving the fine-tuning of pre-trained language models using task-specific instructions. This paradigm shows promising zero-shot results in various natural language processing tasks but is still unexplored in vision emotion understanding. In this work, we focus on enhancing the model's proficiency in understanding and adhering to instructions related to emotional contexts. Initially, we identify key visual clues critical to visual emotion recognition. Subsequently, we introduce a novel GPT-assisted pipeline for generating emotion visual instruction data, effectively addressing the scarcity of annotated instruction data in this domain. Expanding on the groundwork established by InstructBLIP, our proposed EmoVIT architecture incorporates emotion-specific instruction data, leveraging the powerful capabilities of Large Language Models to enhance performance. Through extensive experiments, our model showcases its proficiency in emotion classification, adeptness in affective reasoning, and competence in comprehending humor. The comparative analysis provides a robust benchmark for Emotion Visual Instruction Tuning in the era of LLMs, providing valuable insights and opening avenues for future exploration in this domain. Our code is available at \url{https://github.com/aimmemotion/EmoVIT}.
Dual-branch Cross-Patch Attention Learning for Group Affect Recognition
Dec 14, 2022
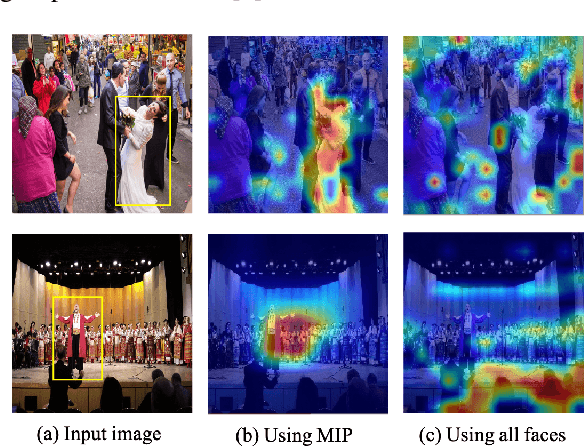
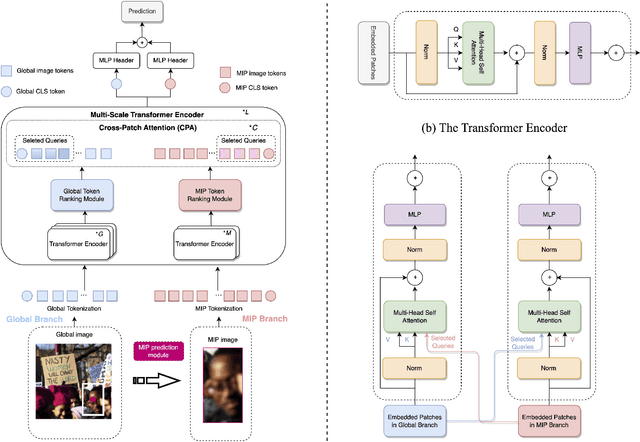

Group affect refers to the subjective emotion that is evoked by an external stimulus in a group, which is an important factor that shapes group behavior and outcomes. Recognizing group affect involves identifying important individuals and salient objects among a crowd that can evoke emotions. Most of the existing methods are proposed to detect faces and objects using pre-trained detectors and summarize the results into group emotions by specific rules. However, such affective region selection mechanisms are heuristic and susceptible to imperfect faces and objects from the pre-trained detectors. Moreover, faces and objects on group-level images are often contextually relevant. There is still an open question about how important faces and objects can be interacted with. In this work, we incorporate the psychological concept called Most Important Person (MIP). It represents the most noteworthy face in the crowd and has an affective semantic meaning. We propose the Dual-branch Cross-Patch Attention Transformer (DCAT) which uses global image and MIP together as inputs. Specifically, we first learn the informative facial regions produced by the MIP and the global context separately. Then, the Cross-Patch Attention module is proposed to fuse the features of MIP and global context together to complement each other. With parameters less than 10x, the proposed DCAT outperforms state-of-the-art methods on two datasets of group valence prediction, GAF 3.0 and GroupEmoW datasets. Moreover, our proposed model can be transferred to another group affect task, group cohesion, and shows comparable results.
Self-Supervised Robustifying Guidance for Monocular 3D Face Reconstruction
Dec 29, 2021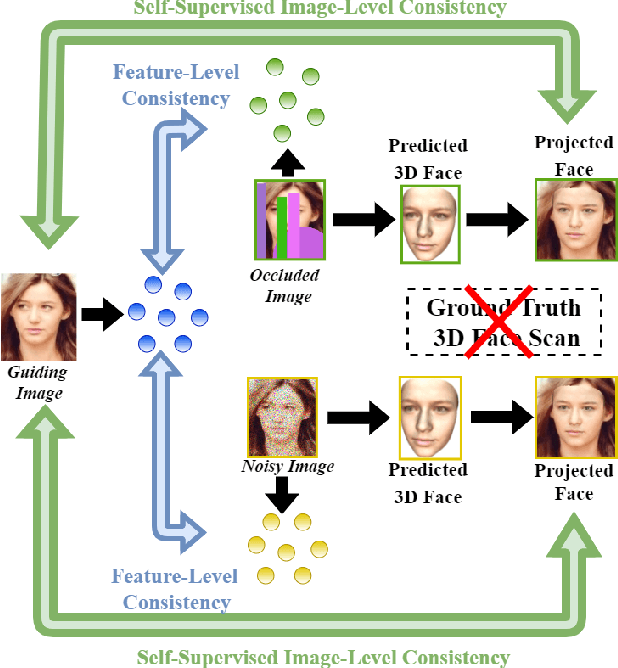
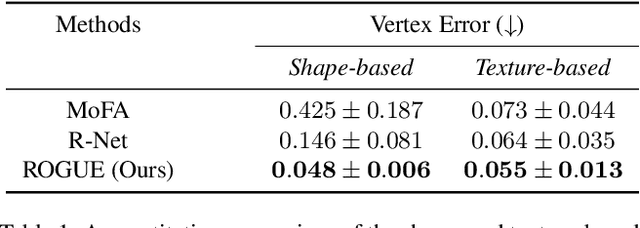
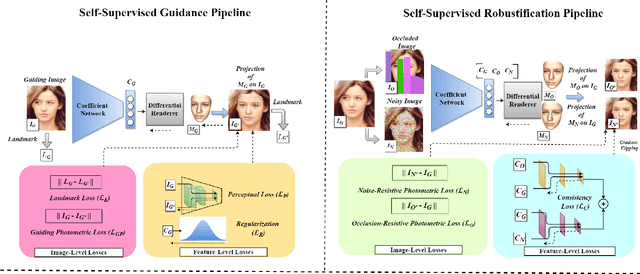
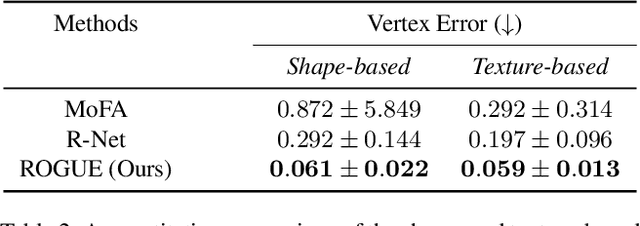
Despite the recent developments in 3D Face Reconstruction from occluded and noisy face images, the performance is still unsatisfactory. One of the main challenges is to handle moderate to heavy occlusions in the face images. In addition, the noise in the face images inhibits the correct capture of facial attributes, thus needing to be reliably addressed. Moreover, most existing methods rely on additional dependencies, posing numerous constraints over the training procedure. Therefore, we propose a Self-Supervised RObustifying GUidancE (ROGUE) framework to obtain robustness against occlusions and noise in the face images. The proposed network contains 1) the Guidance Pipeline to obtain the 3D face coefficients for the clean faces, and 2) the Robustification Pipeline to acquire the consistency between the estimated coefficients for occluded or noisy images and the clean counterpart. The proposed image- and feature-level loss functions aid the ROGUE learning process without posing additional dependencies. On the three variations of the test dataset of CelebA: rational occlusions, delusional occlusions, and noisy face images, our method outperforms the current state-of-the-art method by large margins (e.g., for the shape-based 3D vertex errors, a reduction from 0.146 to 0.048 for rational occlusions, from 0.292 to 0.061 for delusional occlusions and from 0.269 to 0.053 for the noise in the face images), demonstrating the effectiveness of the proposed approach.
Network Space Search for Pareto-Efficient Spaces
Apr 22, 2021
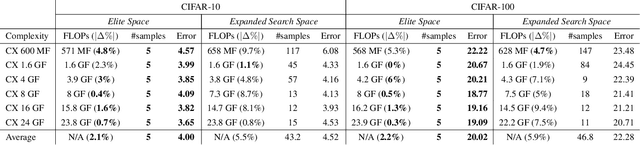


Network spaces have been known as a critical factor in both handcrafted network designs or defining search spaces for Neural Architecture Search (NAS). However, an effective space involves tremendous prior knowledge and/or manual effort, and additional constraints are required to discover efficiency-aware architectures. In this paper, we define a new problem, Network Space Search (NSS), as searching for favorable network spaces instead of a single architecture. We propose an NSS method to directly search for efficient-aware network spaces automatically, reducing the manual effort and immense cost in discovering satisfactory ones. The resultant network spaces, named Elite Spaces, are discovered from Expanded Search Space with minimal human expertise imposed. The Pareto-efficient Elite Spaces are aligned with the Pareto front under various complexity constraints and can be further served as NAS search spaces, benefiting differentiable NAS approaches (e.g. In CIFAR-100, an averagely 2.3% lower error rate and 3.7% closer to target constraint than the baseline with around 90% fewer samples required to find satisfactory networks). Moreover, our NSS approach is capable of searching for superior spaces in future unexplored spaces, revealing great potential in searching for network spaces automatically.
Deploying Image Deblurring across Mobile Devices: A Perspective of Quality and Latency
Apr 27, 2020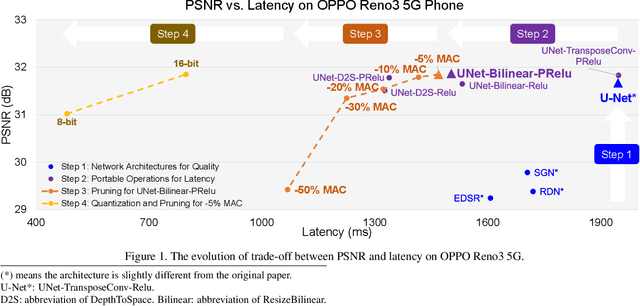
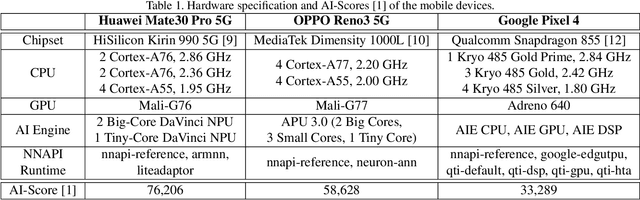
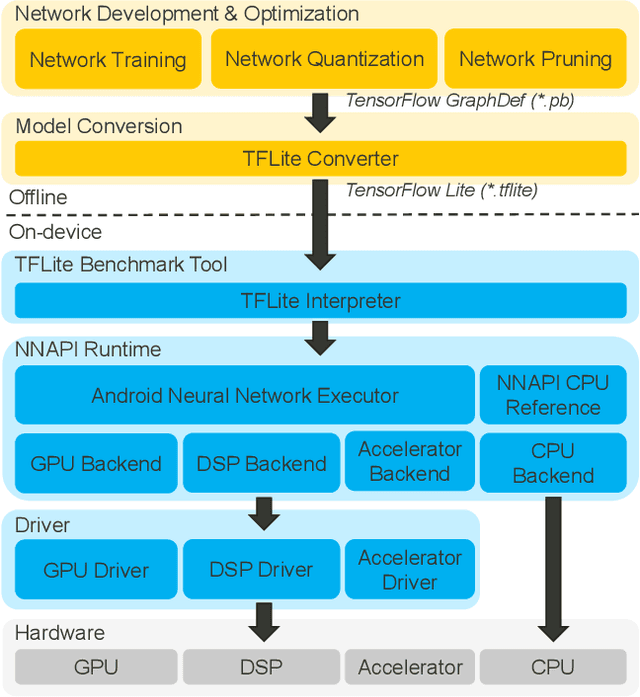
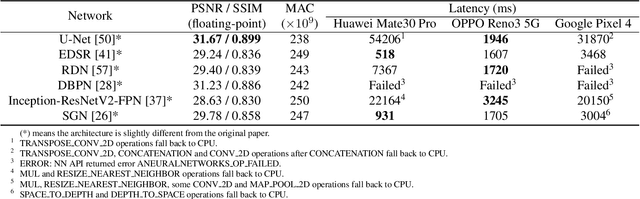
Recently, image enhancement and restoration have become important applications on mobile devices, such as super-resolution and image deblurring. However, most state-of-the-art networks present extremely high computational complexity. This makes them difficult to be deployed on mobile devices with acceptable latency. Moreover, when deploying to different mobile devices, there is a large latency variation due to the difference and limitation of deep learning accelerators on mobile devices. In this paper, we conduct a search of portable network architectures for better quality-latency trade-off across mobile devices. We further present the effectiveness of widely used network optimizations for image deblurring task. This paper provides comprehensive experiments and comparisons to uncover the in-depth analysis for both latency and image quality. Through all the above works, we demonstrate the successful deployment of image deblurring application on mobile devices with the acceleration of deep learning accelerators. To the best of our knowledge, this is the first paper that addresses all the deployment issues of image deblurring task across mobile devices. This paper provides practical deployment-guidelines, and is adopted by the championship-winning team in NTIRE 2020 Image Deblurring Challenge on Smartphone Track.