 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEMPURA: Temporal Event Masked Prediction and Understanding for Reasoning in Action
May 02, 2025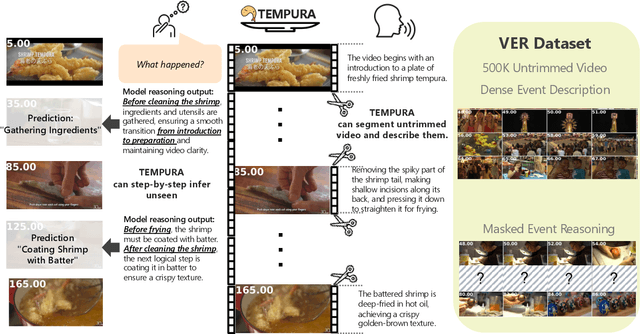

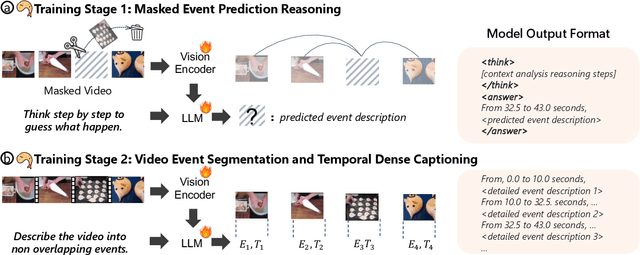
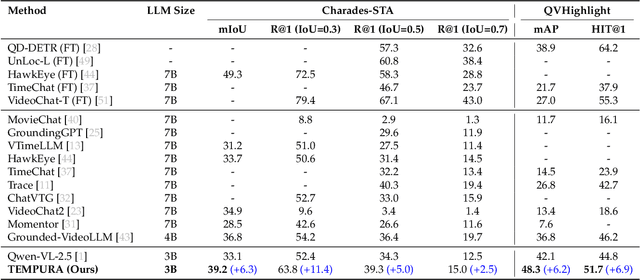
Understanding causal event relationships and achieving fine-grained temporal grounding in videos remain challenging for vision-language models. Existing methods either compress video tokens to reduce temporal resolution, or treat videos as unsegmented streams, which obscures fine-grained event boundaries and limits the modeling of causal dependencies. We propose TEMPURA (Temporal Event Masked Prediction and Understanding for Reasoning in Action), a two-stage training framework that enhances video temporal understanding. TEMPURA first applies masked event prediction reasoning to reconstruct missing events and generate step-by-step causal explanations from dense event annotations, drawing inspiration from effective infilling techniques. TEMPURA then learns to perform video segmentation and dense captioning to decompose videos into non-overlapping events with detailed, timestamp-aligned descriptions. We train TEMPURA on VER, a large-scale dataset curated by us that comprises 1M training instances and 500K videos with temporally aligned event descriptions and structured reasoning steps. Experiments on temporal grounding and highlight detection benchmarks demonstrate that TEMPURA outperforms strong baseline models, confirming that integrating causal reasoning with fine-grained temporal segmentation leads to improved video understanding.
A DeNoising FPN With Transformer R-CNN for Tiny Object Detection
Jun 11, 2024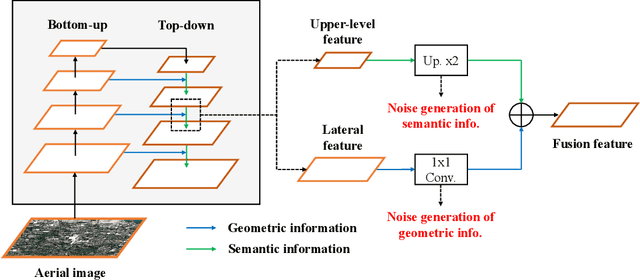


Despite notable advancements in the field of computer vision, the precise detection of tiny objects continues to pose a significant challenge, largely owing to the minuscule pixel representation allocated to these objects in imagery data. This challenge resonates profoundly in the domain of geoscience and remote sensing, where high-fidelity detection of tiny objects can facilitate a myriad of applications ranging from urban planning to environmental monitoring. In this paper, we propose a new framework, namely, DeNoising FPN with Trans R-CNN (DNTR), to improve the performance of tiny object detection. DNTR consists of an easy plug-in design, DeNoising FPN (DN-FPN), and an effective Transformer-based detector, Trans R-CNN. Specifically, feature fusion in the feature pyramid network is important for detecting multiscale objects. However, noisy features may be produced during the fusion process since there is no regularization between the features of different scales. Therefore, we introduce a DN-FPN module that utilizes contrastive learning to suppress noise in each level's features in the top-down path of FPN. Second, based on the two-stage framework, we replace the obsolete R-CNN detector with a novel Trans R-CNN detector to focus on the representation of tiny objects with self-attention. Experimental results manifest that our DNTR outperforms the baselines by at least 17.4% in terms of APvt on the AI-TOD dataset and 9.6% in terms of AP on the VisDrone dataset, respectively. Our code will be available at https://github.com/hoiliu-0801/DNTR.
Lightweight Deep Learning for Resource-Constrained Environments: A Survey
Apr 12, 2024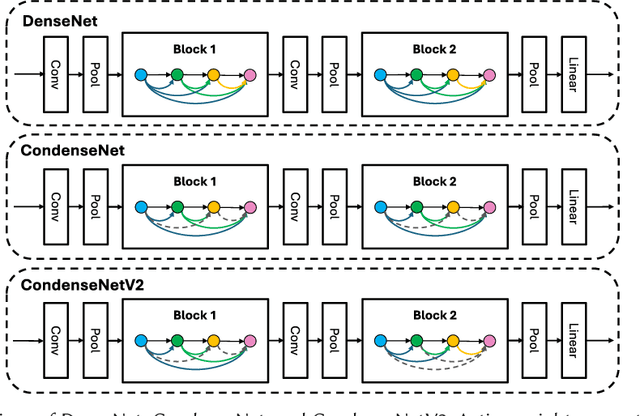


Over the past decade, the dominance of deep learning has prevailed across various domains of artificial intelligence, including natural language processing, computer vision, and biomedical signal processing. While there have been remarkable improvements in model accuracy, deploying these models on lightweight devices, such as mobile phones and microcontrollers, is constrained by limited resources. In this survey, we provide comprehensive design guidance tailored for these devices, detailing the meticulous design of lightweight models, compression methods, and hardware acceleration strategies. The principal goal of this work is to explore methods and concepts for getting around hardware constraints without compromising the model's accuracy. Additionally, we explore two notable paths for lightweight deep learning in the future: deployment techniques for TinyML and Large Language Models. Although these paths undoubtedly have potential, they also present significant challenges, encouraging research into unexplored areas.
DQ-DETR: DETR with Dynamic Query for Tiny Object Detection
Apr 11, 2024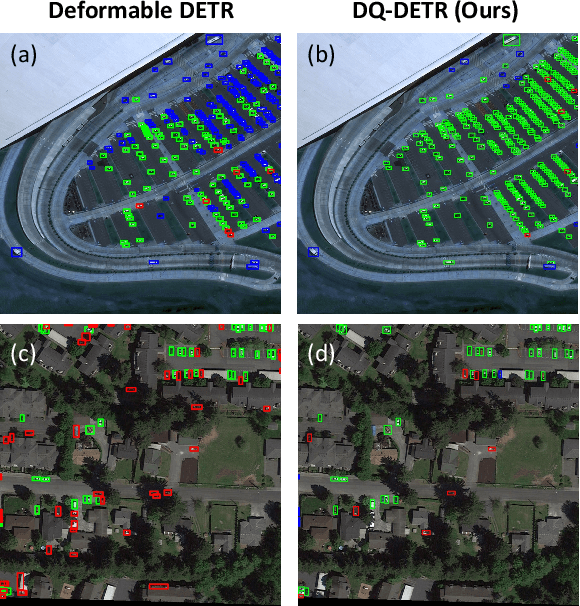
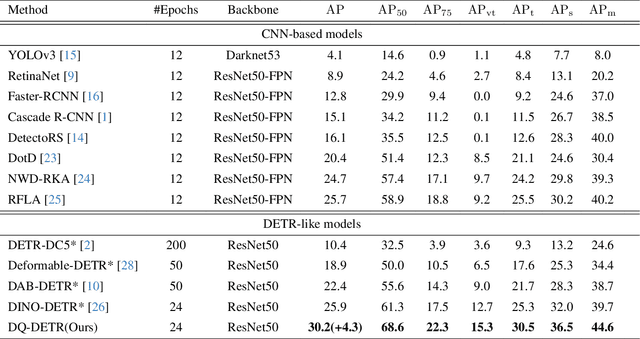
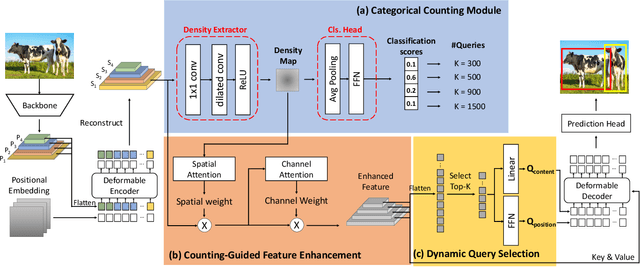

Despite previous DETR-like methods having performed successfully in generic object detection, tiny object detection is still a challenging task for them since the positional information of object queries is not customized for detecting tiny objects, whose scale is extraordinarily smaller than general objects. Also, DETR-like methods using a fixed number of queries make them unsuitable for aerial datasets, which only contain tiny objects, and the numbers of instances are imbalanced between different images. Thus, we present a simple yet effective model, named DQ-DETR, which consists of three different components: categorical counting module, counting-guided feature enhancement, and dynamic query selection to solve the above-mentioned problems. DQ-DETR uses the prediction and density maps from the categorical counting module to dynamically adjust the number of object queries and improve the positional information of queries. Our model DQ-DETR outperforms previous CNN-based and DETR-like methods, achieving state-of-the-art mAP 30.2% on the AI-TOD-V2 dataset, which mostly consists of tiny objects.
MonoTAKD: Teaching Assistant Knowledge Distillation for Monocular 3D Object Detection
Apr 07, 2024



Monocular 3D object detection (Mono3D) is an indispensable research topic in autonomous driving, thanks to the cost-effective monocular camera sensors and its wide range of applications. Since the image perspective has depth ambiguity, the challenges of Mono3D lie in understanding 3D scene geometry and reconstructing 3D object information from a single image. Previous methods attempted to transfer 3D information directly from the LiDAR-based teacher to the camera-based student. However, a considerable gap in feature representation makes direct cross-modal distillation inefficient, resulting in a significant performance deterioration between the LiDAR-based teacher and the camera-based student. To address this issue, we propose the Teaching Assistant Knowledge Distillation (MonoTAKD) to break down the learning objective by integrating intra-modal distillation with cross-modal residual distillation. In particular, we employ a strong camera-based teaching assistant model to distill powerful visual knowledge effectively through intra-modal distillation. Subsequently, we introduce the cross-modal residual distillation to transfer the 3D spatial cues. By acquiring both visual knowledge and 3D spatial cues, the predictions of our approach are rigorously evaluated on the KITTI 3D object detection benchmark and achieve state-of-the-art performance in Mono3D.
Dual-branch Cross-Patch Attention Learning for Group Affect Recognition
Dec 14, 2022
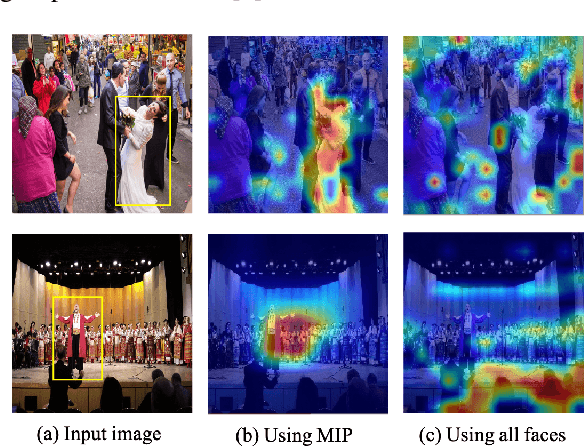
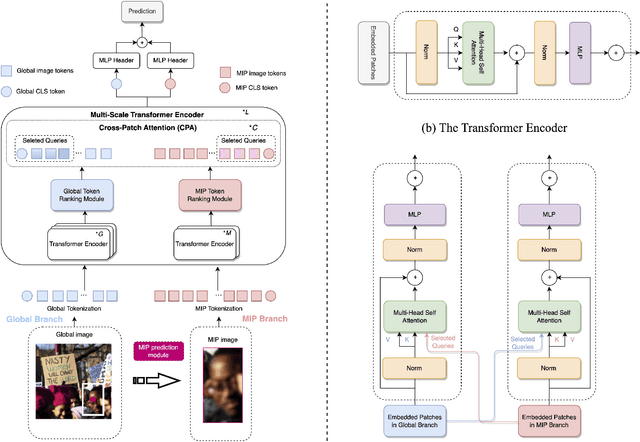

Group affect refers to the subjective emotion that is evoked by an external stimulus in a group, which is an important factor that shapes group behavior and outcomes. Recognizing group affect involves identifying important individuals and salient objects among a crowd that can evoke emotions. Most of the existing methods are proposed to detect faces and objects using pre-trained detectors and summarize the results into group emotions by specific rules. However, such affective region selection mechanisms are heuristic and susceptible to imperfect faces and objects from the pre-trained detectors. Moreover, faces and objects on group-level images are often contextually relevant. There is still an open question about how important faces and objects can be interacted with. In this work, we incorporate the psychological concept called Most Important Person (MIP). It represents the most noteworthy face in the crowd and has an affective semantic meaning. We propose the Dual-branch Cross-Patch Attention Transformer (DCAT) which uses global image and MIP together as inputs. Specifically, we first learn the informative facial regions produced by the MIP and the global context separately. Then, the Cross-Patch Attention module is proposed to fuse the features of MIP and global context together to complement each other. With parameters less than 10x, the proposed DCAT outperforms state-of-the-art methods on two datasets of group valence prediction, GAF 3.0 and GroupEmoW datasets. Moreover, our proposed model can be transferred to another group affect task, group cohesion, and shows comparable results.