 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Pool Is Not Enough: Multi-Cluster Memory for Practical Test-Time Adaptation
Mar 22, 2026Test-time adaptation (TTA) adapts pre-trained models to distribution shifts at inference using only unlabeled test data. Under the Practical TTA (PTTA) setting, where test streams are temporally correlated and non-i.i.d., memory has become an indispensable component for stable adaptation, yet existing methods universally store amples in a single unstructured pool. We show that this single-cluster design is fundamentally mismatched to PTTA: a stream clusterability analysis reveals that test streams are inherently multi-modal, with the optimal number of mixture components consistently far exceeding one. To close this structural gap, we propose Multi-Cluster Memory (MCM), a plug-and-play framework that organizes stored samples into multiple clusters using lightweight pixel-level statistical descriptors. MCM introduces three complementary mechanisms: descriptor-based cluster assignment to capture distinct distributional modes, Adjacent Cluster Consolidation (ACC) to bound memory usage by merging the most similar temporally adjacent clusters, and Uniform Cluster Retrieval (UCR) to ensure balanced supervision across all modes during adaptation. Integrated with three contemporary TTA methods on CIFAR-10-C, CIFAR-100-C, ImageNet-C, and DomainNet, MCM achieves consistent improvements across all 12 configurations, with gains up to 5.00% on ImageNet-C and 12.13% on DomainNet. Notably, these gains scale with distributional complexity: larger label spaces with greater multi-modality benefit most from multi-cluster organization. GMM-based memory diagnostics further confirm that MCM maintains near-optimal distributional balance, entropy, and mode coverage, whereas single-cluster memory exhibits persistent imbalance and progressive mode loss. These results establish memory organization as a key design axis for practical test-time adaptation.
TriDF: Evaluating Perception, Detection, and Hallucination for Interpretable DeepFake Detection
Dec 23, 2025Advances in generative modeling have made it increasingly easy to fabricate realistic portrayals of individuals, creating serious risks for security, communication, and public trust. Detecting such person-driven manipulations requires systems that not only distinguish altered content from authentic media but also provide clear and reliable reasoning. In this paper, we introduce TriDF, a comprehensive benchmark for interpretable DeepFake detection. TriDF contains high-quality forgeries from advanced synthesis models, covering 16 DeepFake types across image, video, and audio modalities. The benchmark evaluates three key aspects: Perception, which measures the ability of a model to identify fine-grained manipulation artifacts using human-annotated evidence; Detection, which assesses classification performance across diverse forgery families and generators; and Hallucination, which quantifies the reliability of model-generated explanations. Experiments on state-of-the-art multimodal large language models show that accurate perception is essential for reliable detection, but hallucination can severely disrupt decision-making, revealing the interdependence of these three aspects. TriDF provides a unified framework for understanding the interaction between detection accuracy, evidence identification, and explanation reliability, offering a foundation for building trustworthy systems that address real-world synthetic media threats.
InstructFLIP: Exploring Unified Vision-Language Model for Face Anti-spoofing
Jul 16, 2025Face anti-spoofing (FAS) aims to construct a robust system that can withstand diverse attacks. While recent efforts have concentrated mainly on cross-domain generalization, two significant challenges persist: limited semantic understanding of attack types and training redundancy across domains. We address the first by integrating vision-language models (VLMs) to enhance the perception of visual input. For the second challenge, we employ a meta-domain strategy to learn a unified model that generalizes well across multiple domains. Our proposed InstructFLIP is a novel instruction-tuned framework that leverages VLMs to enhance generalization via textual guidance trained solely on a single domain. At its core, InstructFLIP explicitly decouples instructions into content and style components, where content-based instructions focus on the essential semantics of spoofing, and style-based instructions consider variations related to the environment and camera characteristics. Extensive experiments demonstrate the effectiveness of InstructFLIP by outperforming SOTA models in accuracy and substantially reducing training redundancy across diverse domains in FAS. Project website is available at https://kunkunlin1221.github.io/InstructFLIP.
A DeNoising FPN With Transformer R-CNN for Tiny Object Detection
Jun 11, 2024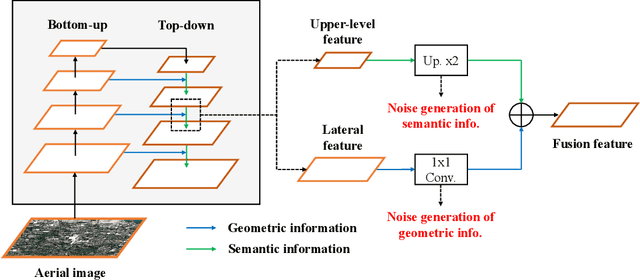


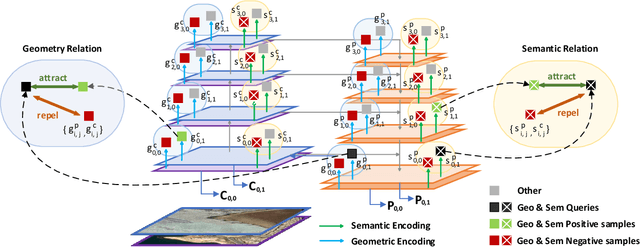
Despite notable advancements in the field of computer vision, the precise detection of tiny objects continues to pose a significant challenge, largely owing to the minuscule pixel representation allocated to these objects in imagery data. This challenge resonates profoundly in the domain of geoscience and remote sensing, where high-fidelity detection of tiny objects can facilitate a myriad of applications ranging from urban planning to environmental monitoring. In this paper, we propose a new framework, namely, DeNoising FPN with Trans R-CNN (DNTR), to improve the performance of tiny object detection. DNTR consists of an easy plug-in design, DeNoising FPN (DN-FPN), and an effective Transformer-based detector, Trans R-CNN. Specifically, feature fusion in the feature pyramid network is important for detecting multiscale objects. However, noisy features may be produced during the fusion process since there is no regularization between the features of different scales. Therefore, we introduce a DN-FPN module that utilizes contrastive learning to suppress noise in each level's features in the top-down path of FPN. Second, based on the two-stage framework, we replace the obsolete R-CNN detector with a novel Trans R-CNN detector to focus on the representation of tiny objects with self-attention. Experimental results manifest that our DNTR outperforms the baselines by at least 17.4% in terms of APvt on the AI-TOD dataset and 9.6% in terms of AP on the VisDrone dataset, respectively. Our code will be available at https://github.com/hoiliu-0801/DNTR.
EmoVIT: Revolutionizing Emotion Insights with Visual Instruction Tuning
Apr 25, 2024Visual Instruction Tuning represents a novel learning paradigm involving the fine-tuning of pre-trained language models using task-specific instructions. This paradigm shows promising zero-shot results in various natural language processing tasks but is still unexplored in vision emotion understanding. In this work, we focus on enhancing the model's proficiency in understanding and adhering to instructions related to emotional contexts. Initially, we identify key visual clues critical to visual emotion recognition. Subsequently, we introduce a novel GPT-assisted pipeline for generating emotion visual instruction data, effectively addressing the scarcity of annotated instruction data in this domain. Expanding on the groundwork established by InstructBLIP, our proposed EmoVIT architecture incorporates emotion-specific instruction data, leveraging the powerful capabilities of Large Language Models to enhance performance. Through extensive experiments, our model showcases its proficiency in emotion classification, adeptness in affective reasoning, and competence in comprehending humor. The comparative analysis provides a robust benchmark for Emotion Visual Instruction Tuning in the era of LLMs, providing valuable insights and opening avenues for future exploration in this domain. Our code is available at \url{https://github.com/aimmemotion/EmoVIT}.