 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindClaw: Closed-Loop Embodied Mental-State Reasoning for Precision Intervention
May 31, 2026Theory of Mind (ToM) enables an agent to reason about another actor's beliefs, goals, and intentions, which is essential for human-centered embodied assistance. Existing ToM benchmarks have advanced text and multimodal mental-state recognition, but they mostly evaluate offline question answering or final action prediction. They do not fully test whether an embodied agent can stay connected to a changing environment, update actor-specific beliefs, decide when reasoning is needed, and intervene only when help is useful. Building on MindPower, we extend robot-centric ToM reasoning to a real-time closed-loop setting and introduce MindClaw, a framework for embodied mental-state reasoning with precision intervention. MindClaw connects multi-source inputs, belief memory, an embodied cognitive trigger skill, mental reasoning, and action generation, allowing the agent to output helpful actions at the right time while remaining silent when intervention is unnecessary. Experiments show that direct VLM baselines struggle with task awareness and intervention calibration, while MindClaw achieves the best overall performance, demonstrating the importance of trigger-skill optimization for closed-loop embodied ToM assistance.
PinpointQA: A Dataset and Benchmark for Small Object-Centric Spatial Understanding in Indoor Videos
Apr 10, 2026Small object-centric spatial understanding in indoor videos remains a significant challenge for multimodal large language models (MLLMs), despite its practical value for object search and assistive applications. Although existing benchmarks have advanced video spatial intelligence, embodied reasoning, and diagnostic perception, no existing benchmark directly evaluates whether a model can localize a target object in video and express its position with sufficient precision for downstream use. In this work, we introduce PinpointQA, the first dataset and benchmark for small object-centric spatial understanding in indoor videos. Built from ScanNet++ and ScanNet200, PinpointQA comprises 1,024 scenes and 10,094 QA pairs organized into four progressively challenging tasks: Target Presence Verification (TPV), Nearest Reference Identification (NRI), Fine-Grained Spatial Description (FSD), and Structured Spatial Prediction (SSP). The dataset is built from intermediate spatial representations, with QA pairs generated automatically and further refined through quality control. Experiments on representative MLLMs reveal a consistent capability gap along the progressive chain, with SSP remaining particularly difficult. Supervised fine-tuning on PinpointQA yields substantial gains, especially on the harder tasks, demonstrating that PinpointQA serves as both a diagnostic benchmark and an effective training dataset. The dataset and project page are available at https://rainchowz.github.io/PinpointQA.
Aligning Progress and Feasibility: A Neuro-Symbolic Dual Memory Framework for Long-Horizon LLM Agents
Apr 03, 2026Large language models (LLMs) have demonstrated strong potential in long-horizon decision-making tasks, such as embodied manipulation and web interaction. However, agents frequently struggle with endless trial-and-error loops or deviate from the main objective in complex environments. We attribute these failures to two fundamental errors: global Progress Drift and local Feasibility Violation. Existing methods typically attempt to address both issues simultaneously using a single paradigm. However, these two challenges are fundamentally distinct: the former relies on fuzzy semantic planning, while the latter demands strict logical constraints and state validation. The inherent limitations of such a single-paradigm approach pose a fundamental challenge for existing models in handling long-horizon tasks. Motivated by this insight, we propose a Neuro-Symbolic Dual Memory Framework that explicitly decouples semantic progress guidance from logical feasibility verification. Specifically, during the inference phase, the framework invokes both memory mechanisms synchronously: on one hand, a neural-network-based Progress Memory extracts semantic blueprints from successful trajectories to guide global task advancement; on the other hand, a symbolic-logic-based Feasibility Memory utilizes executable Python verification functions synthesized from failed transitions to perform strict logical validation. Experiments demonstrate that this method significantly outperforms existing competitive baselines on ALFWorld, WebShop, and TextCraft, while drastically reducing the invalid action rate and average trajectory length.
TriDF: Evaluating Perception, Detection, and Hallucination for Interpretable DeepFake Detection
Dec 23, 2025Advances in generative modeling have made it increasingly easy to fabricate realistic portrayals of individuals, creating serious risks for security, communication, and public trust. Detecting such person-driven manipulations requires systems that not only distinguish altered content from authentic media but also provide clear and reliable reasoning. In this paper, we introduce TriDF, a comprehensive benchmark for interpretable DeepFake detection. TriDF contains high-quality forgeries from advanced synthesis models, covering 16 DeepFake types across image, video, and audio modalities. The benchmark evaluates three key aspects: Perception, which measures the ability of a model to identify fine-grained manipulation artifacts using human-annotated evidence; Detection, which assesses classification performance across diverse forgery families and generators; and Hallucination, which quantifies the reliability of model-generated explanations. Experiments on state-of-the-art multimodal large language models show that accurate perception is essential for reliable detection, but hallucination can severely disrupt decision-making, revealing the interdependence of these three aspects. TriDF provides a unified framework for understanding the interaction between detection accuracy, evidence identification, and explanation reliability, offering a foundation for building trustworthy systems that address real-world synthetic media threats.
KPLM-STA: Physically-Accurate Shadow Synthesis for Human Relighting via Keypoint-Based Light Modeling
Nov 11, 2025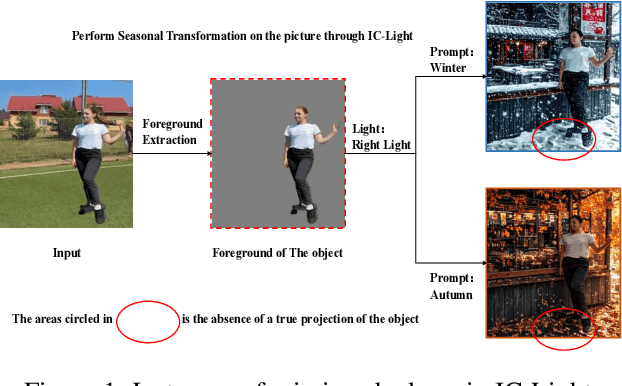


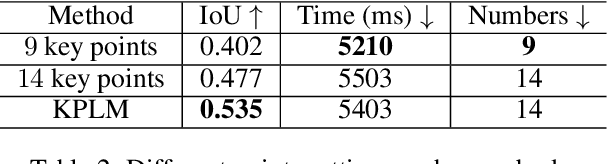
Image composition aims to seamlessly integrate a foreground object into a background, where generating realistic and geometrically accurate shadows remains a persistent challenge. While recent diffusion-based methods have outperformed GAN-based approaches, existing techniques, such as the diffusion-based relighting framework IC-Light, still fall short in producing shadows with both high appearance realism and geometric precision, especially in composite images. To address these limitations, we propose a novel shadow generation framework based on a Keypoints Linear Model (KPLM) and a Shadow Triangle Algorithm (STA). KPLM models articulated human bodies using nine keypoints and one bounding block, enabling physically plausible shadow projection and dynamic shading across joints, thereby enhancing visual realism. STA further improves geometric accuracy by computing shadow angles, lengths, and spatial positions through explicit geometric formulations. Extensive experiments demonstrate that our method achieves state-of-the-art performance on shadow realism benchmarks, particularly under complex human poses, and generalizes effectively to multi-directional relighting scenarios such as those supported by IC-Light.
RecipeGen: A Step-Aligned Multimodal Benchmark for Real-World Recipe Generation
Jun 07, 2025



Creating recipe images is a key challenge in food computing, with applications in culinary education and multimodal recipe assistants. However, existing datasets lack fine-grained alignment between recipe goals, step-wise instructions, and visual content. We present RecipeGen, the first large-scale, real-world benchmark for recipe-based Text-to-Image (T2I), Image-to-Video (I2V), and Text-to-Video (T2V) generation. RecipeGen contains 26,453 recipes, 196,724 images, and 4,491 videos, covering diverse ingredients, cooking procedures, styles, and dish types. We further propose domain-specific evaluation metrics to assess ingredient fidelity and interaction modeling, benchmark representative T2I, I2V, and T2V models, and provide insights for future recipe generation models. Project page is available now.
Single Document Image Highlight Removal via A Large-Scale Real-World Dataset and A Location-Aware Network
Apr 19, 2025


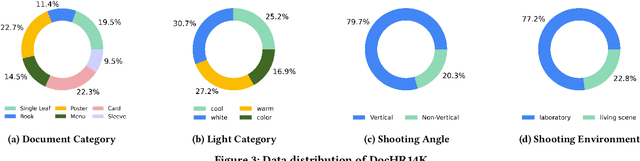
Reflective documents often suffer from specular highlights under ambient lighting, severely hindering text readability and degrading overall visual quality. Although recent deep learning methods show promise in highlight removal, they remain suboptimal for document images, primarily due to the lack of dedicated datasets and tailored architectural designs. To tackle these challenges, we present DocHR14K, a large-scale real-world dataset comprising 14,902 high-resolution image pairs across six document categories and various lighting conditions. To the best of our knowledge, this is the first high-resolution dataset for document highlight removal that captures a wide range of real-world lighting conditions. Additionally, motivated by the observation that the residual map between highlighted and clean images naturally reveals the spatial structure of highlight regions, we propose a simple yet effective Highlight Location Prior (HLP) to estimate highlight masks without human annotations. Building on this prior, we present the Location-Aware Laplacian Pyramid Highlight Removal Network (L2HRNet), which effectively removes highlights by leveraging estimated priors and incorporates diffusion module to restore details. Extensive experiments demonstrate that DocHR14K improves highlight removal under diverse lighting conditions. Our L2HRNet achieves state-of-the-art performance across three benchmark datasets, including a 5.01\% increase in PSNR and a 13.17\% reduction in RMSE on DocHR14K.
RecipeGen: A Benchmark for Real-World Recipe Image Generation
Mar 07, 2025



Recipe image generation is an important challenge in food computing, with applications from culinary education to interactive recipe platforms. However, there is currently no real-world dataset that comprehensively connects recipe goals, sequential steps, and corresponding images. To address this, we introduce RecipeGen, the first real-world goal-step-image benchmark for recipe generation, featuring diverse ingredients, varied recipe steps, multiple cooking styles, and a broad collection of food categories. Data is in https://github.com/zhangdaxia22/RecipeGen.
Feature-based One-For-All: A Universal Framework for Heterogeneous Knowledge Distillation
Jan 15, 2025Knowledge distillation (KD) involves transferring knowledge from a pre-trained heavy teacher model to a lighter student model, thereby reducing the inference cost while maintaining comparable effectiveness. Prior KD techniques typically assume homogeneity between the teacher and student models. However, as technology advances, a wide variety of architectures have emerged, ranging from initial Convolutional Neural Networks (CNNs) to Vision Transformers (ViTs), and Multi-Level Perceptrons (MLPs). Consequently, developing a universal KD framework compatible with any architecture has become an important research topic. In this paper, we introduce a feature-based one-for-all (FOFA) KD framework to enable feature distillation across diverse architecture. Our framework comprises two key components. First, we design prompt tuning blocks that incorporate student feedback, allowing teacher features to adapt to the student model's learning process. Second, we propose region-aware attention to mitigate the view mismatch problem between heterogeneous architecture. By leveraging these two modules, effective distillation of intermediate features can be achieved across heterogeneous architectures. Extensive experiments on CIFAR, ImageNet, and COCO demonstrate the superiority of the proposed method.
Future Sight and Tough Fights: Revolutionizing Sequential Recommendation with FENRec
Dec 16, 2024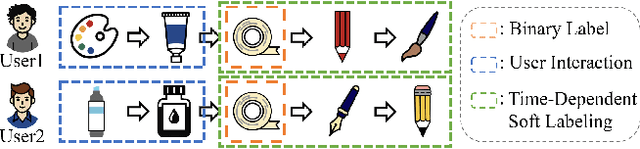
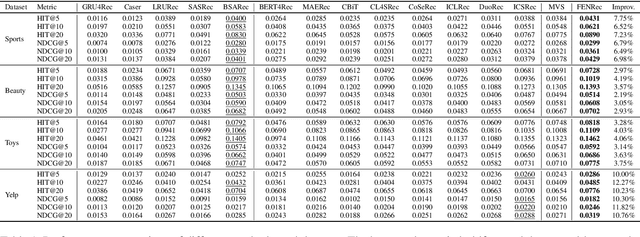
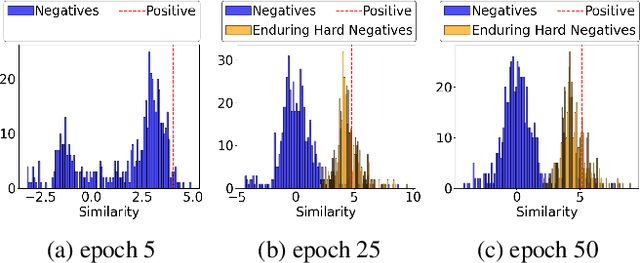
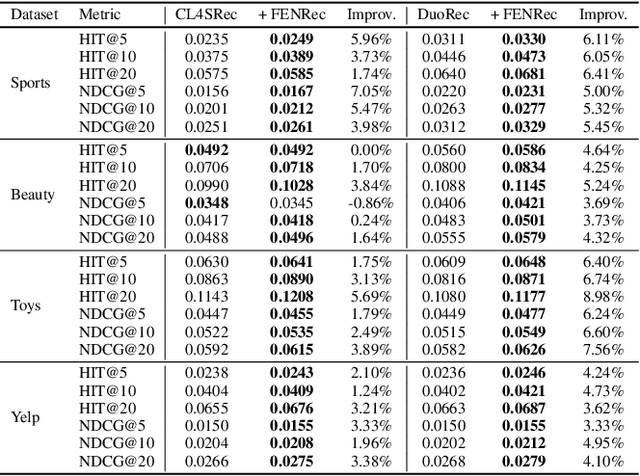
Sequential recommendation (SR) systems predict user preferences by analyzing time-ordered interaction sequences. A common challenge for SR is data sparsity, as users typically interact with only a limited number of items. While contrastive learning has been employed in previous approaches to address the challenges, these methods often adopt binary labels, missing finer patterns and overlooking detailed information in subsequent behaviors of users. Additionally, they rely on random sampling to select negatives in contrastive learning, which may not yield sufficiently hard negatives during later training stages. In this paper, we propose Future data utilization with Enduring Negatives for contrastive learning in sequential Recommendation (FENRec). Our approach aims to leverage future data with time-dependent soft labels and generate enduring hard negatives from existing data, thereby enhancing the effectiveness in tackling data sparsity. Experiment results demonstrate our state-of-the-art performance across four benchmark datasets, with an average improvement of 6.16\% across all metrics.