 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoVIT: Revolutionizing Emotion Insights with Visual Instruction Tuning
Apr 25, 2024Visual Instruction Tuning represents a novel learning paradigm involving the fine-tuning of pre-trained language models using task-specific instructions. This paradigm shows promising zero-shot results in various natural language processing tasks but is still unexplored in vision emotion understanding. In this work, we focus on enhancing the model's proficiency in understanding and adhering to instructions related to emotional contexts. Initially, we identify key visual clues critical to visual emotion recognition. Subsequently, we introduce a novel GPT-assisted pipeline for generating emotion visual instruction data, effectively addressing the scarcity of annotated instruction data in this domain. Expanding on the groundwork established by InstructBLIP, our proposed EmoVIT architecture incorporates emotion-specific instruction data, leveraging the powerful capabilities of Large Language Models to enhance performance. Through extensive experiments, our model showcases its proficiency in emotion classification, adeptness in affective reasoning, and competence in comprehending humor. The comparative analysis provides a robust benchmark for Emotion Visual Instruction Tuning in the era of LLMs, providing valuable insights and opening avenues for future exploration in this domain. Our code is available at \url{https://github.com/aimmemotion/EmoVIT}.
ZYELL-NCTU NetTraffic-1.0: A Large-Scale Dataset for Real-World Network Anomaly Detection
Mar 08, 2021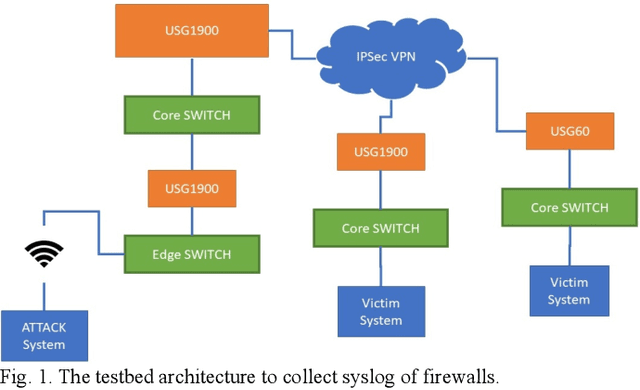
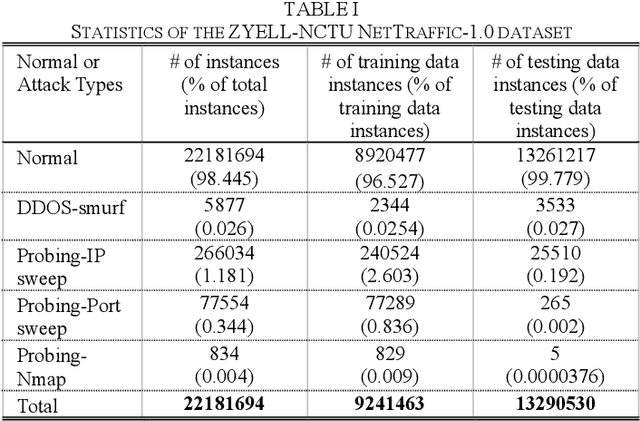


Network security has been an active research topic for long. One critical issue is improving the anomaly detection capability of intrusion detection systems (IDSs), such as firewalls. However, existing network anomaly datasets are out of date (i.e., being collected many years ago) or IP-anonymized, making the data characteristics differ from today's network. Therefore, this work introduces a new, large-scale, and real-world dataset, ZYELL-NCTU NetTraffic-1.0, which is collected from the raw output of firewalls in a real network, with the objective to advance the development of network security researches.