 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperPatch: Sequential Knowledge Editing Under n-ary Structural Drift
Jun 02, 2026Large Language Models (LLMs) rely on Knowledge Editing (KE) to maintain temporal validity, yet real-world knowledge is inherently n-ary. We demonstrate that in non-stationary environments, sequential updates to complex relations induce N-ary Structural Drift, a phenomenon where the binary reification of n-ary events into triples fractures relational atomicity. This precipitates Structure-Conditioned Knowledge Transfer Failure, a systematic mis-grounding of the retriever frequently misdiagnosed as parametric hallucination. To tackle this, we propose HyperPatch, a parameter-preserving framework that reformulates sequential KE as a stability problem over hypergraph manifolds. HyperPatch preserves event integrity through three phases: (i) Structural Prior Initialization, establishing a topology-aware embedding space via contrastive learning on a Hypergraph Neural Network (HGNN) to capture high-order correlations; (ii) Sequential Topology Editing, utilizing a dual-stage mechanism that employs SimHash-based Topological Alignment for rapid conflict resolution and Topological LoRA Adaptation to track drift without backbone retraining; and (iii) Structure-Conditioned Reasoning, which integrates globally consistent evidence from fused linguistic and structural manifolds. On the MQuAKE-CF and MQuAKE-T benchmarks, HyperPatch achieves relative gains in Hop-wise Accuracy (H-Acc) of 96.24% and 21.06% over the strongest baseline, respectively. Further ablations demonstrate superior reliability under continuous n-ary update streams, whereas the standard KG-based variant suffers H-Acc collapses of up to 88.3% due to structural misalignment.
One Pool Is Not Enough: Multi-Cluster Memory for Practical Test-Time Adaptation
Mar 22, 2026Test-time adaptation (TTA) adapts pre-trained models to distribution shifts at inference using only unlabeled test data. Under the Practical TTA (PTTA) setting, where test streams are temporally correlated and non-i.i.d., memory has become an indispensable component for stable adaptation, yet existing methods universally store amples in a single unstructured pool. We show that this single-cluster design is fundamentally mismatched to PTTA: a stream clusterability analysis reveals that test streams are inherently multi-modal, with the optimal number of mixture components consistently far exceeding one. To close this structural gap, we propose Multi-Cluster Memory (MCM), a plug-and-play framework that organizes stored samples into multiple clusters using lightweight pixel-level statistical descriptors. MCM introduces three complementary mechanisms: descriptor-based cluster assignment to capture distinct distributional modes, Adjacent Cluster Consolidation (ACC) to bound memory usage by merging the most similar temporally adjacent clusters, and Uniform Cluster Retrieval (UCR) to ensure balanced supervision across all modes during adaptation. Integrated with three contemporary TTA methods on CIFAR-10-C, CIFAR-100-C, ImageNet-C, and DomainNet, MCM achieves consistent improvements across all 12 configurations, with gains up to 5.00% on ImageNet-C and 12.13% on DomainNet. Notably, these gains scale with distributional complexity: larger label spaces with greater multi-modality benefit most from multi-cluster organization. GMM-based memory diagnostics further confirm that MCM maintains near-optimal distributional balance, entropy, and mode coverage, whereas single-cluster memory exhibits persistent imbalance and progressive mode loss. These results establish memory organization as a key design axis for practical test-time adaptation.
HyperRAG: Reasoning N-ary Facts over Hypergraphs for Retrieval Augmented Generation
Feb 16, 2026Graph-based retrieval-augmented generation (RAG) methods, typically built on knowledge graphs (KGs) with binary relational facts, have shown promise in multi-hop open-domain QA. However, their rigid retrieval schemes and dense similarity search often introduce irrelevant context, increase computational overhead, and limit relational expressiveness. In contrast, n-ary hypergraphs encode higher-order relational facts that capture richer inter-entity dependencies and enable shallower, more efficient reasoning paths. To address this limitation, we propose HyperRAG, a RAG framework tailored for n-ary hypergraphs with two complementary retrieval variants: (i) HyperRetriever learns structural-semantic reasoning over n-ary facts to construct query-conditioned relational chains. It enables accurate factual tracking, adaptive high-order traversal, and interpretable multi-hop reasoning under context constraints. (ii) HyperMemory leverages the LLM's parametric memory to guide beam search, dynamically scoring n-ary facts and entities for query-aware path expansion. Extensive evaluations on WikiTopics (11 closed-domain datasets) and three open-domain QA benchmarks (HotpotQA, MuSiQue, and 2WikiMultiHopQA) validate HyperRAG's effectiveness. HyperRetriever achieves the highest answer accuracy overall, with average gains of 2.95% in MRR and 1.23% in Hits@10 over the strongest baseline. Qualitative analysis further shows that HyperRetriever bridges reasoning gaps through adaptive and interpretable n-ary chain construction, benefiting both open and closed-domain QA.
VecSet-Edit: Unleashing Pre-trained LRM for Mesh Editing from Single Image
Feb 04, 20263D editing has emerged as a critical research area to provide users with flexible control over 3D assets. While current editing approaches predominantly focus on 3D Gaussian Splatting or multi-view images, the direct editing of 3D meshes remains underexplored. Prior attempts, such as VoxHammer, rely on voxel-based representations that suffer from limited resolution and necessitate labor-intensive 3D mask. To address these limitations, we propose \textbf{VecSet-Edit}, the first pipeline that leverages the high-fidelity VecSet Large Reconstruction Model (LRM) as a backbone for mesh editing. Our approach is grounded on a analysis of the spatial properties in VecSet tokens, revealing that token subsets govern distinct geometric regions. Based on this insight, we introduce Mask-guided Token Seeding and Attention-aligned Token Gating strategies to precisely localize target regions using only 2D image conditions. Also, considering the difference between VecSet diffusion process versus voxel we design a Drift-aware Token Pruning to reject geometric outliers during the denoising process. Finally, our Detail-preserving Texture Baking module ensures that we not only preserve the geometric details of original mesh but also the textural information. More details can be found in our project page: https://github.com/BlueDyee/VecSet-Edit/tree/main
TriDF: Evaluating Perception, Detection, and Hallucination for Interpretable DeepFake Detection
Dec 23, 2025Advances in generative modeling have made it increasingly easy to fabricate realistic portrayals of individuals, creating serious risks for security, communication, and public trust. Detecting such person-driven manipulations requires systems that not only distinguish altered content from authentic media but also provide clear and reliable reasoning. In this paper, we introduce TriDF, a comprehensive benchmark for interpretable DeepFake detection. TriDF contains high-quality forgeries from advanced synthesis models, covering 16 DeepFake types across image, video, and audio modalities. The benchmark evaluates three key aspects: Perception, which measures the ability of a model to identify fine-grained manipulation artifacts using human-annotated evidence; Detection, which assesses classification performance across diverse forgery families and generators; and Hallucination, which quantifies the reliability of model-generated explanations. Experiments on state-of-the-art multimodal large language models show that accurate perception is essential for reliable detection, but hallucination can severely disrupt decision-making, revealing the interdependence of these three aspects. TriDF provides a unified framework for understanding the interaction between detection accuracy, evidence identification, and explanation reliability, offering a foundation for building trustworthy systems that address real-world synthetic media threats.
Not All Thats Rare Is Lost: Causal Paths to Rare Concept Synthesis
May 27, 2025



Diffusion models have shown strong capabilities in high-fidelity image generation but often falter when synthesizing rare concepts, i.e., prompts that are infrequently observed in the training distribution. In this paper, we introduce RAP, a principled framework that treats rare concept generation as navigating a latent causal path: a progressive, model-aligned trajectory through the generative space from frequent concepts to rare targets. Rather than relying on heuristic prompt alternation, we theoretically justify that rare prompt guidance can be approximated by semantically related frequent prompts. We then formulate prompt switching as a dynamic process based on score similarity, enabling adaptive stage transitions. Furthermore, we reinterpret prompt alternation as a second-order denoising mechanism, promoting smooth semantic progression and coherent visual synthesis. Through this causal lens, we align input scheduling with the model's internal generative dynamics. Experiments across diverse diffusion backbones demonstrate that RAP consistently enhances rare concept generation, outperforming strong baselines in both automated evaluations and human studies.
Swapped Logit Distillation via Bi-level Teacher Alignment
Apr 27, 2025Knowledge distillation (KD) compresses the network capacity by transferring knowledge from a large (teacher) network to a smaller one (student). It has been mainstream that the teacher directly transfers knowledge to the student with its original distribution, which can possibly lead to incorrect predictions. In this article, we propose a logit-based distillation via swapped logit processing, namely Swapped Logit Distillation (SLD). SLD is proposed under two assumptions: (1) the wrong prediction occurs when the prediction label confidence is not the maximum; (2) the "natural" limit of probability remains uncertain as the best value addition to the target cannot be determined. To address these issues, we propose a swapped logit processing scheme. Through this approach, we find that the swap method can be effectively extended to teacher and student outputs, transforming into two teachers. We further introduce loss scheduling to boost the performance of two teachers' alignment. Extensive experiments on image classification tasks demonstrate that SLD consistently performs best among previous state-of-the-art methods.
Single Document Image Highlight Removal via A Large-Scale Real-World Dataset and A Location-Aware Network
Apr 19, 2025


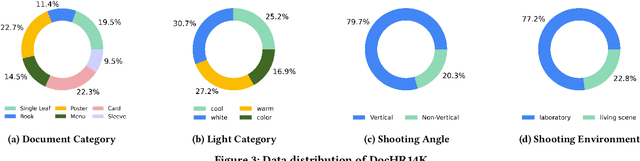
Reflective documents often suffer from specular highlights under ambient lighting, severely hindering text readability and degrading overall visual quality. Although recent deep learning methods show promise in highlight removal, they remain suboptimal for document images, primarily due to the lack of dedicated datasets and tailored architectural designs. To tackle these challenges, we present DocHR14K, a large-scale real-world dataset comprising 14,902 high-resolution image pairs across six document categories and various lighting conditions. To the best of our knowledge, this is the first high-resolution dataset for document highlight removal that captures a wide range of real-world lighting conditions. Additionally, motivated by the observation that the residual map between highlighted and clean images naturally reveals the spatial structure of highlight regions, we propose a simple yet effective Highlight Location Prior (HLP) to estimate highlight masks without human annotations. Building on this prior, we present the Location-Aware Laplacian Pyramid Highlight Removal Network (L2HRNet), which effectively removes highlights by leveraging estimated priors and incorporates diffusion module to restore details. Extensive experiments demonstrate that DocHR14K improves highlight removal under diverse lighting conditions. Our L2HRNet achieves state-of-the-art performance across three benchmark datasets, including a 5.01\% increase in PSNR and a 13.17\% reduction in RMSE on DocHR14K.
MAD: Makeup All-in-One with Cross-Domain Diffusion Model
Apr 03, 2025

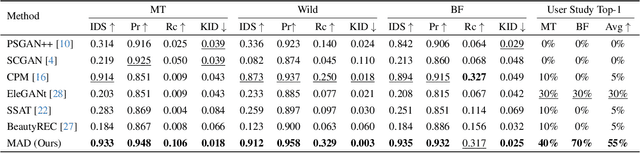

Existing makeup techniques often require designing multiple models to handle different inputs and align features across domains for different makeup tasks, e.g., beauty filter, makeup transfer, and makeup removal, leading to increased complexity. Another limitation is the absence of text-guided makeup try-on, which is more user-friendly without needing reference images. In this study, we make the first attempt to use a single model for various makeup tasks. Specifically, we formulate different makeup tasks as cross-domain translations and leverage a cross-domain diffusion model to accomplish all tasks. Unlike existing methods that rely on separate encoder-decoder configurations or cycle-based mechanisms, we propose using different domain embeddings to facilitate domain control. This allows for seamless domain switching by merely changing embeddings with a single model, thereby reducing the reliance on additional modules for different tasks. Moreover, to support precise text-to-makeup applications, we introduce the MT-Text dataset by extending the MT dataset with textual annotations, advancing the practicality of makeup technologies.
Foreground Focus: Enhancing Coherence and Fidelity in Camouflaged Image Generation
Apr 02, 2025Camouflaged image generation is emerging as a solution to data scarcity in camouflaged vision perception, offering a cost-effective alternative to data collection and labeling. Recently, the state-of-the-art approach successfully generates camouflaged images using only foreground objects. However, it faces two critical weaknesses: 1) the background knowledge does not integrate effectively with foreground features, resulting in a lack of foreground-background coherence (e.g., color discrepancy); 2) the generation process does not prioritize the fidelity of foreground objects, which leads to distortion, particularly for small objects. To address these issues, we propose a Foreground-Aware Camouflaged Image Generation (FACIG) model. Specifically, we introduce a Foreground-Aware Feature Integration Module (FAFIM) to strengthen the integration between foreground features and background knowledge. In addition, a Foreground-Aware Denoising Loss is designed to enhance foreground reconstruction supervision. Experiments on various datasets show our method outperforms previous methods in overall camouflaged image quality and foreground fidelity.