 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVecSet-Edit: Unleashing Pre-trained LRM for Mesh Editing from Single Image
Feb 04, 20263D editing has emerged as a critical research area to provide users with flexible control over 3D assets. While current editing approaches predominantly focus on 3D Gaussian Splatting or multi-view images, the direct editing of 3D meshes remains underexplored. Prior attempts, such as VoxHammer, rely on voxel-based representations that suffer from limited resolution and necessitate labor-intensive 3D mask. To address these limitations, we propose \textbf{VecSet-Edit}, the first pipeline that leverages the high-fidelity VecSet Large Reconstruction Model (LRM) as a backbone for mesh editing. Our approach is grounded on a analysis of the spatial properties in VecSet tokens, revealing that token subsets govern distinct geometric regions. Based on this insight, we introduce Mask-guided Token Seeding and Attention-aligned Token Gating strategies to precisely localize target regions using only 2D image conditions. Also, considering the difference between VecSet diffusion process versus voxel we design a Drift-aware Token Pruning to reject geometric outliers during the denoising process. Finally, our Detail-preserving Texture Baking module ensures that we not only preserve the geometric details of original mesh but also the textural information. More details can be found in our project page: https://github.com/BlueDyee/VecSet-Edit/tree/main
Not All Thats Rare Is Lost: Causal Paths to Rare Concept Synthesis
May 27, 2025



Diffusion models have shown strong capabilities in high-fidelity image generation but often falter when synthesizing rare concepts, i.e., prompts that are infrequently observed in the training distribution. In this paper, we introduce RAP, a principled framework that treats rare concept generation as navigating a latent causal path: a progressive, model-aligned trajectory through the generative space from frequent concepts to rare targets. Rather than relying on heuristic prompt alternation, we theoretically justify that rare prompt guidance can be approximated by semantically related frequent prompts. We then formulate prompt switching as a dynamic process based on score similarity, enabling adaptive stage transitions. Furthermore, we reinterpret prompt alternation as a second-order denoising mechanism, promoting smooth semantic progression and coherent visual synthesis. Through this causal lens, we align input scheduling with the model's internal generative dynamics. Experiments across diverse diffusion backbones demonstrate that RAP consistently enhances rare concept generation, outperforming strong baselines in both automated evaluations and human studies.
MAD: Makeup All-in-One with Cross-Domain Diffusion Model
Apr 03, 2025

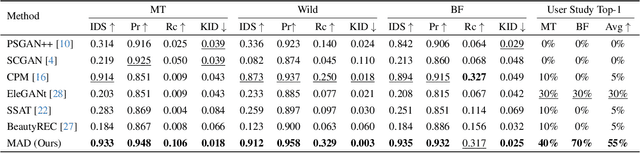

Existing makeup techniques often require designing multiple models to handle different inputs and align features across domains for different makeup tasks, e.g., beauty filter, makeup transfer, and makeup removal, leading to increased complexity. Another limitation is the absence of text-guided makeup try-on, which is more user-friendly without needing reference images. In this study, we make the first attempt to use a single model for various makeup tasks. Specifically, we formulate different makeup tasks as cross-domain translations and leverage a cross-domain diffusion model to accomplish all tasks. Unlike existing methods that rely on separate encoder-decoder configurations or cycle-based mechanisms, we propose using different domain embeddings to facilitate domain control. This allows for seamless domain switching by merely changing embeddings with a single model, thereby reducing the reliance on additional modules for different tasks. Moreover, to support precise text-to-makeup applications, we introduce the MT-Text dataset by extending the MT dataset with textual annotations, advancing the practicality of makeup technologies.
Anomaly Detection for Hybrid Butterfly Subspecies via Probability Filtering
Apr 02, 2025Detecting butterfly hybrids requires knowledge of the parent subspecies, and the process can be tedious when encountering a new subspecies. This study focuses on a specific scenario where a model trained to recognize hybrid species A can generalize to species B when B biologically mimics A. Since species A and B share similar patterns, we leverage BioCLIP as our feature extractor to capture features based on their taxonomy. Consequently, the algorithm designed for species A can be transferred to B, as their hybrid and non-hybrid patterns exhibit similar relationships. To determine whether a butterfly is a hybrid, we adopt proposed probability filtering and color jittering to augment and simulate the mimicry. With these approaches, we achieve second place in the official development phase. Our code is publicly available at https://github.com/Justin900429/NSF-HDR-Challenge.
TF-TI2I: Training-Free Text-and-Image-to-Image Generation via Multi-Modal Implicit-Context Learning in Text-to-Image Models
Mar 19, 2025Text-and-Image-To-Image (TI2I), an extension of Text-To-Image (T2I), integrates image inputs with textual instructions to enhance image generation. Existing methods often partially utilize image inputs, focusing on specific elements like objects or styles, or they experience a decline in generation quality with complex, multi-image instructions. To overcome these challenges, we introduce Training-Free Text-and-Image-to-Image (TF-TI2I), which adapts cutting-edge T2I models such as SD3 without the need for additional training. Our method capitalizes on the MM-DiT architecture, in which we point out that textual tokens can implicitly learn visual information from vision tokens. We enhance this interaction by extracting a condensed visual representation from reference images, facilitating selective information sharing through Reference Contextual Masking -- this technique confines the usage of contextual tokens to instruction-relevant visual information. Additionally, our Winner-Takes-All module mitigates distribution shifts by prioritizing the most pertinent references for each vision token. Addressing the gap in TI2I evaluation, we also introduce the FG-TI2I Bench, a comprehensive benchmark tailored for TI2I and compatible with existing T2I methods. Our approach shows robust performance across various benchmarks, confirming its effectiveness in handling complex image-generation tasks.
FreeCond: Free Lunch in the Input Conditions of Text-Guided Inpainting
Nov 30, 2024In this study, we aim to determine and solve the deficiency of Stable Diffusion Inpainting (SDI) in following the instruction of both prompt and mask. Due to the training bias from masking, the inpainting quality is hindered when the prompt instruction and image condition are not related. Therefore, we conduct a detailed analysis of the internal representations learned by SDI, focusing on how the mask input influences the cross-attention layer. We observe that adapting text key tokens toward the input mask enables the model to selectively paint within the given area. Leveraging these insights, we propose FreeCond, which adjusts only the input mask condition and image condition. By increasing the latent mask value and modifying the frequency of image condition, we align the cross-attention features with the model's training bias to improve generation quality without additional computation, particularly when user inputs are complicated and deviate from the training setup. Extensive experiments demonstrate that FreeCond can enhance any SDI-based model, e.g., yielding up to a 60% and 58% improvement of SDI and SDXLI in the CLIP score.
Traffic Scene Generation from Natural Language Description for Autonomous Vehicles with Large Language Model
Sep 15, 2024Text-to-scene generation, transforming textual descriptions into detailed scenes, typically relies on generating key scenarios along predetermined paths, constraining environmental diversity and limiting customization flexibility. To address these limitations, we propose a novel text-to-traffic scene framework that leverages a large language model to generate diverse traffic scenarios within the Carla simulator based on natural language descriptions. Users can define specific parameters such as weather conditions, vehicle types, and road signals, while our pipeline can autonomously select the starting point and scenario details, generating scenes from scratch without relying on predetermined locations or trajectories. Furthermore, our framework supports both critical and routine traffic scenarios, enhancing its applicability. Experimental results indicate that our approach promotes diverse agent planning and road selection, enhancing the training of autonomous agents in traffic environments. Notably, our methodology has achieved a 16% reduction in average collision rates. Our work is made publicly available at https://basiclab.github.io/TTSG.
Training-and-prompt-free General Painterly Harmonization Using Image-wise Attention Sharing
Apr 19, 2024Painterly Image Harmonization aims at seamlessly blending disparate visual elements within a single coherent image. However, previous approaches often encounter significant limitations due to training data constraints, the need for time-consuming fine-tuning, or reliance on additional prompts. To surmount these hurdles, we design a Training-and-prompt-Free General Painterly Harmonization method using image-wise attention sharing (TF-GPH), which integrates a novel "share-attention module". This module redefines the traditional self-attention mechanism by allowing for comprehensive image-wise attention, facilitating the use of a state-of-the-art pretrained latent diffusion model without the typical training data limitations. Additionally, we further introduce "similarity reweighting" mechanism enhances performance by effectively harnessing cross-image information, surpassing the capabilities of fine-tuning or prompt-based approaches. At last, we recognize the deficiencies in existing benchmarks and propose the "General Painterly Harmonization Benchmark", which employs range-based evaluation metrics to more accurately reflect real-world application. Extensive experiments demonstrate the superior efficacy of our method across various benchmarks. The code and web demo are available at https://github.com/BlueDyee/TF-GPH.
Vision Transformers: State of the Art and Research Challenges
Jul 07, 2022


Transformers have achieved great success in natural language processing. Due to the powerful capability of self-attention mechanism in transformers, researchers develop the vision transformers for a variety of computer vision tasks, such as image recognition, object detection, image segmentation, pose estimation, and 3D reconstruction. This paper presents a comprehensive overview of the literature on different architecture designs and training tricks (including self-supervised learning) for vision transformers. Our goal is to provide a systematic review with the open research opportunities.