 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOSE: Pose estimation Of virtual Sync Exhibit system
Oct 20, 2024



This work is a portable MetaVerse implementation, and we use 3D pose estimation with AI to make virtual avatars do synchronized actions and interact with the environment. The motivation is that we find it inconvenient to use joysticks and sensors when playing with fitness rings. In order to replace joysticks and reduce costs, we developed a platform that can control virtual avatars through pose estimation to identify the movements of real people, and we also implemented a multi-process to achieve modularization and reduce the overall latency.
IKDP: Inverse Kinematics through Diffusion Process
Oct 20, 2024



It is a common problem in robotics to specify the position of each joint of the robot so that the endpoint reaches a certain target in space. This can be solved in two ways, forward kinematics method and inverse kinematics method. However, inverse kinematics cannot be solved by an algorithm. The common method is the Jacobian inverse technique, and some people have tried to find the answer by machine learning. In this project, we will show how to use the Conditional Denoising Diffusion Probabilistic Model to integrate the solution of calculating IK. Index Terms: Inverse kinematics, Denoising Diffusion Probabilistic Model, self Attention, Transformer
YOLO-RD: Introducing Relevant and Compact Explicit Knowledge to YOLO by Retriever-Dictionary
Oct 20, 2024
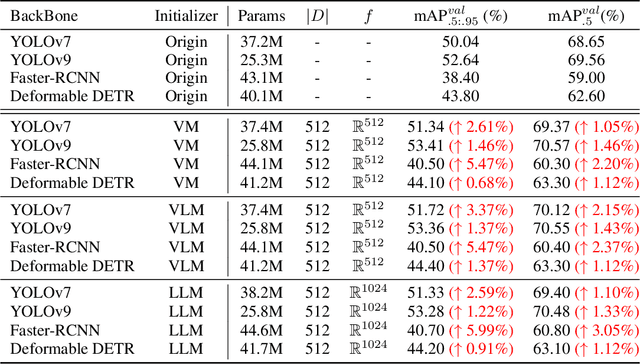
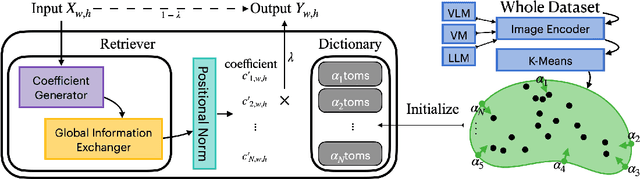

Identifying and localizing objects within images is a fundamental challenge, and numerous efforts have been made to enhance model accuracy by experimenting with diverse architectures and refining training strategies. Nevertheless, a prevalent limitation in existing models is overemphasizing the current input while ignoring the information from the entire dataset. We introduce an innovative {\em \textbf{R}etriever}-{\em\textbf{D}ictionary} (RD) module to address this issue. This architecture enables YOLO-based models to efficiently retrieve features from a Dictionary that contains the insight of the dataset, which is built by the knowledge from Visual Models (VM), Large Language Models (LLM), or Visual Language Models (VLM). The flexible RD enables the model to incorporate such explicit knowledge that enhances the ability to benefit multiple tasks, specifically, segmentation, detection, and classification, from pixel to image level. The experiments show that using the RD significantly improves model performance, achieving more than a 3\% increase in mean Average Precision for object detection with less than a 1\% increase in model parameters. Beyond 1-stage object detection models, the RD module improves the effectiveness of 2-stage models and DETR-based architectures, such as Faster R-CNN and Deformable DETR
Traffic Scene Generation from Natural Language Description for Autonomous Vehicles with Large Language Model
Sep 15, 2024


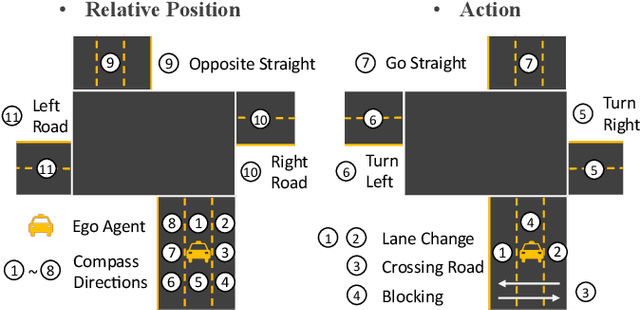
Text-to-scene generation, transforming textual descriptions into detailed scenes, typically relies on generating key scenarios along predetermined paths, constraining environmental diversity and limiting customization flexibility. To address these limitations, we propose a novel text-to-traffic scene framework that leverages a large language model to generate diverse traffic scenarios within the Carla simulator based on natural language descriptions. Users can define specific parameters such as weather conditions, vehicle types, and road signals, while our pipeline can autonomously select the starting point and scenario details, generating scenes from scratch without relying on predetermined locations or trajectories. Furthermore, our framework supports both critical and routine traffic scenarios, enhancing its applicability. Experimental results indicate that our approach promotes diverse agent planning and road selection, enhancing the training of autonomous agents in traffic environments. Notably, our methodology has achieved a 16% reduction in average collision rates. Our work is made publicly available at https://basiclab.github.io/TTSG.