 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVP-NTK: Exploring the Benefits of Visual Prompting in Differentially Private Data Synthesis
Mar 20, 2025Differentially private (DP) synthetic data has become the de facto standard for releasing sensitive data. However, many DP generative models suffer from the low utility of synthetic data, especially for high-resolution images. On the other hand, one of the emerging techniques in parameter efficient fine-tuning (PEFT) is visual prompting (VP), which allows well-trained existing models to be reused for the purpose of adapting to subsequent downstream tasks. In this work, we explore such a phenomenon in constructing captivating generative models with DP constraints. We show that VP in conjunction with DP-NTK, a DP generator that exploits the power of the neural tangent kernel (NTK) in training DP generative models, achieves a significant performance boost, particularly for high-resolution image datasets, with accuracy improving from 0.644$\pm$0.044 to 0.769. Lastly, we perform ablation studies on the effect of different parameters that influence the overall performance of VP-NTK. Our work demonstrates a promising step forward in improving the utility of DP synthetic data, particularly for high-resolution images.
POSE: Pose estimation Of virtual Sync Exhibit system
Oct 20, 2024This work is a portable MetaVerse implementation, and we use 3D pose estimation with AI to make virtual avatars do synchronized actions and interact with the environment. The motivation is that we find it inconvenient to use joysticks and sensors when playing with fitness rings. In order to replace joysticks and reduce costs, we developed a platform that can control virtual avatars through pose estimation to identify the movements of real people, and we also implemented a multi-process to achieve modularization and reduce the overall latency.
Ring-A-Bell! How Reliable are Concept Removal Methods for Diffusion Models?
Oct 16, 2023


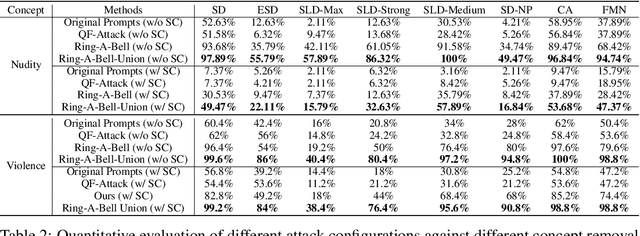
Diffusion models for text-to-image (T2I) synthesis, such as Stable Diffusion (SD), have recently demonstrated exceptional capabilities for generating high-quality content. However, this progress has raised several concerns of potential misuse, particularly in creating copyrighted, prohibited, and restricted content, or NSFW (not safe for work) images. While efforts have been made to mitigate such problems, either by implementing a safety filter at the evaluation stage or by fine-tuning models to eliminate undesirable concepts or styles, the effectiveness of these safety measures in dealing with a wide range of prompts remains largely unexplored. In this work, we aim to investigate these safety mechanisms by proposing one novel concept retrieval algorithm for evaluation. We introduce Ring-A-Bell, a model-agnostic red-teaming tool for T2I diffusion models, where the whole evaluation can be prepared in advance without prior knowledge of the target model. Specifically, Ring-A-Bell first performs concept extraction to obtain holistic representations for sensitive and inappropriate concepts. Subsequently, by leveraging the extracted concept, Ring-A-Bell automatically identifies problematic prompts for diffusion models with the corresponding generation of inappropriate content, allowing the user to assess the reliability of deployed safety mechanisms. Finally, we empirically validate our method by testing online services such as Midjourney and various methods of concept removal. Our results show that Ring-A-Bell, by manipulating safe prompting benchmarks, can transform prompts that were originally regarded as safe to evade existing safety mechanisms, thus revealing the defects of the so-called safety mechanisms which could practically lead to the generation of harmful contents.