 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending Unauthorized Model Merging via Dual-Stage Weight Protection
Nov 14, 2025

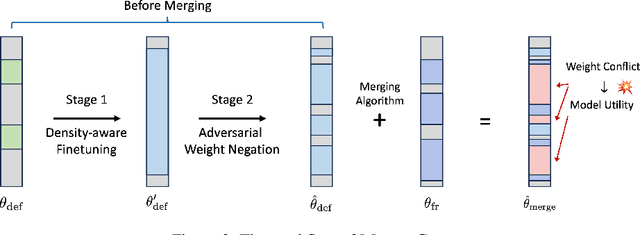

The rapid proliferation of pretrained models and open repositories has made model merging a convenient yet risky practice, allowing free-riders to combine fine-tuned models into a new multi-capability model without authorization. Such unauthorized model merging not only violates intellectual property rights but also undermines model ownership and accountability. To address this issue, we present MergeGuard, a proactive dual-stage weight protection framework that disrupts merging compatibility while maintaining task fidelity. In the first stage, we redistribute task-relevant information across layers via L2-regularized optimization, ensuring that important gradients are evenly dispersed. In the second stage, we inject structured perturbations to misalign task subspaces, breaking curvature compatibility in the loss landscape. Together, these stages reshape the model's parameter geometry such that merged models collapse into destructive interference while the protected model remains fully functional. Extensive experiments on both vision (ViT-L-14) and language (Llama2, Gemma2, Mistral) models demonstrate that MergeGuard reduces merged model accuracy by up to 90% with less than 1.5% performance loss on the protected model.
VP-NTK: Exploring the Benefits of Visual Prompting in Differentially Private Data Synthesis
Mar 20, 2025Differentially private (DP) synthetic data has become the de facto standard for releasing sensitive data. However, many DP generative models suffer from the low utility of synthetic data, especially for high-resolution images. On the other hand, one of the emerging techniques in parameter efficient fine-tuning (PEFT) is visual prompting (VP), which allows well-trained existing models to be reused for the purpose of adapting to subsequent downstream tasks. In this work, we explore such a phenomenon in constructing captivating generative models with DP constraints. We show that VP in conjunction with DP-NTK, a DP generator that exploits the power of the neural tangent kernel (NTK) in training DP generative models, achieves a significant performance boost, particularly for high-resolution image datasets, with accuracy improving from 0.644$\pm$0.044 to 0.769. Lastly, we perform ablation studies on the effect of different parameters that influence the overall performance of VP-NTK. Our work demonstrates a promising step forward in improving the utility of DP synthetic data, particularly for high-resolution images.
Data Poisoning Attacks to Locally Differentially Private Range Query Protocols
Mar 05, 2025Trajectory data, which tracks movements through geographic locations, is crucial for improving real-world applications. However, collecting such sensitive data raises considerable privacy concerns. Local differential privacy (LDP) offers a solution by allowing individuals to locally perturb their trajectory data before sharing it. Despite its privacy benefits, LDP protocols are vulnerable to data poisoning attacks, where attackers inject fake data to manipulate aggregated results. In this work, we make the first attempt to analyze vulnerabilities in several representative LDP trajectory protocols. We propose \textsc{TraP}, a heuristic algorithm for data \underline{P}oisoning attacks using a prefix-suffix method to optimize fake \underline{Tra}jectory selection, significantly reducing computational complexity. Our experimental results demonstrate that our attack can substantially increase target pattern occurrences in the perturbed trajectory dataset with few fake users. This study underscores the urgent need for robust defenses and better protocol designs to safeguard LDP trajectory data against malicious manipulation.
Beyond Natural Language Perplexity: Detecting Dead Code Poisoning in Code Generation Datasets
Feb 28, 2025



The increasing adoption of large language models (LLMs) for code-related tasks has raised concerns about the security of their training datasets. One critical threat is dead code poisoning, where syntactically valid but functionally redundant code is injected into training data to manipulate model behavior. Such attacks can degrade the performance of neural code search systems, leading to biased or insecure code suggestions. Existing detection methods, such as token-level perplexity analysis, fail to effectively identify dead code due to the structural and contextual characteristics of programming languages. In this paper, we propose DePA (Dead Code Perplexity Analysis), a novel line-level detection and cleansing method tailored to the structural properties of code. DePA computes line-level perplexity by leveraging the contextual relationships between code lines and identifies anomalous lines by comparing their perplexity to the overall distribution within the file. Our experiments on benchmark datasets demonstrate that DePA significantly outperforms existing methods, achieving 0.14-0.19 improvement in detection F1-score and a 44-65% increase in poisoned segment localization precision. Furthermore, DePA enhances detection speed by 0.62-23x, making it practical for large-scale dataset cleansing. Overall, by addressing the unique challenges of dead code poisoning, DePA provides a robust and efficient solution for safeguarding the integrity of code generation model training datasets.
Layer-Aware Task Arithmetic: Disentangling Task-Specific and Instruction-Following Knowledge
Feb 27, 2025



Large language models (LLMs) demonstrate strong task-specific capabilities through fine-tuning, but merging multiple fine-tuned models often leads to degraded performance due to overlapping instruction-following components. Task Arithmetic (TA), which combines task vectors derived from fine-tuning, enables multi-task learning and task forgetting but struggles to isolate task-specific knowledge from general instruction-following behavior. To address this, we propose Layer-Aware Task Arithmetic (LATA), a novel approach that assigns layer-specific weights to task vectors based on their alignment with instruction-following or task-specific components. By amplifying task-relevant layers and attenuating instruction-following layers, LATA improves task learning and forgetting performance while preserving overall model utility. Experiments on multiple benchmarks, including WikiText-2, GSM8K, and HumanEval, demonstrate that LATA outperforms existing methods in both multi-task learning and selective task forgetting, achieving higher task accuracy and alignment with minimal degradation in output quality. Our findings highlight the importance of layer-wise analysis in disentangling task-specific and general-purpose knowledge, offering a robust framework for efficient model merging and editing.
BADTV: Unveiling Backdoor Threats in Third-Party Task Vectors
Jan 04, 2025Task arithmetic in large-scale pre-trained models enables flexible adaptation to diverse downstream tasks without extensive re-training. By leveraging task vectors (TVs), users can perform modular updates to pre-trained models through simple arithmetic operations like addition and subtraction. However, this flexibility introduces new security vulnerabilities. In this paper, we identify and evaluate the susceptibility of TVs to backdoor attacks, demonstrating how malicious actors can exploit TVs to compromise model integrity. By developing composite backdoors and eliminating redudant clean tasks, we introduce BadTV, a novel backdoor attack specifically designed to remain effective under task learning, forgetting, and analogies operations. Our extensive experiments reveal that BadTV achieves near-perfect attack success rates across various scenarios, significantly impacting the security of models using task arithmetic. We also explore existing defenses, showing that current methods fail to detect or mitigate BadTV. Our findings highlight the need for robust defense mechanisms to secure TVs in real-world applications, especially as TV services become more popular in machine-learning ecosystems.
Prompting the Unseen: Detecting Hidden Backdoors in Black-Box Models
Nov 14, 2024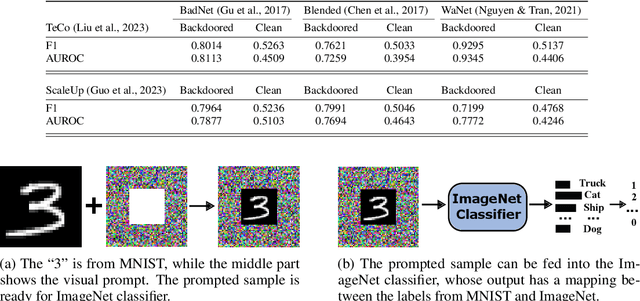
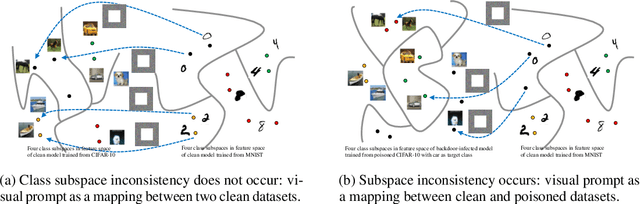

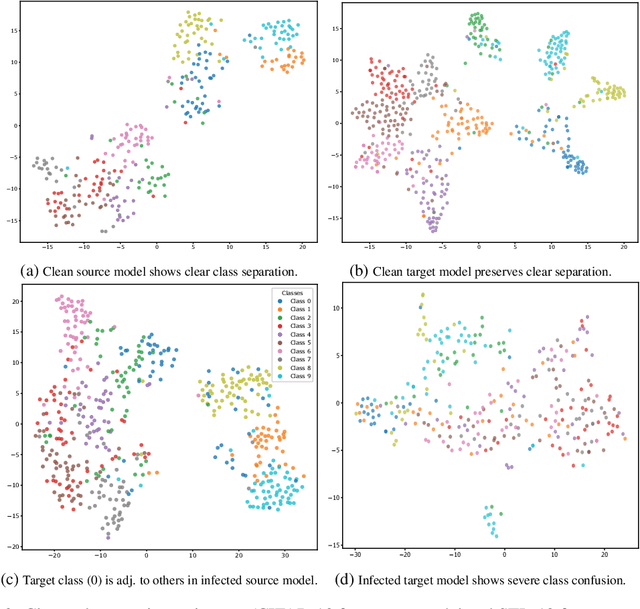
Visual prompting (VP) is a new technique that adapts well-trained frozen models for source domain tasks to target domain tasks. This study examines VP's benefits for black-box model-level backdoor detection. The visual prompt in VP maps class subspaces between source and target domains. We identify a misalignment, termed class subspace inconsistency, between clean and poisoned datasets. Based on this, we introduce \textsc{BProm}, a black-box model-level detection method to identify backdoors in suspicious models, if any. \textsc{BProm} leverages the low classification accuracy of prompted models when backdoors are present. Extensive experiments confirm \textsc{BProm}'s effectiveness.
Information-Theoretical Principled Trade-off between Jailbreakability and Stealthiness on Vision Language Models
Oct 02, 2024



In recent years, Vision-Language Models (VLMs) have demonstrated significant advancements in artificial intelligence, transforming tasks across various domains. Despite their capabilities, these models are susceptible to jailbreak attacks, which can compromise their safety and reliability. This paper explores the trade-off between jailbreakability and stealthiness in VLMs, presenting a novel algorithm to detect non-stealthy jailbreak attacks and enhance model robustness. We introduce a stealthiness-aware jailbreak attack using diffusion models, highlighting the challenge of detecting AI-generated content. Our approach leverages Fano's inequality to elucidate the relationship between attack success rates and stealthiness scores, providing an explainable framework for evaluating these threats. Our contributions aim to fortify AI systems against sophisticated attacks, ensuring their outputs remain aligned with ethical standards and user expectations.
Exploring Robustness of Visual State Space model against Backdoor Attacks
Aug 22, 2024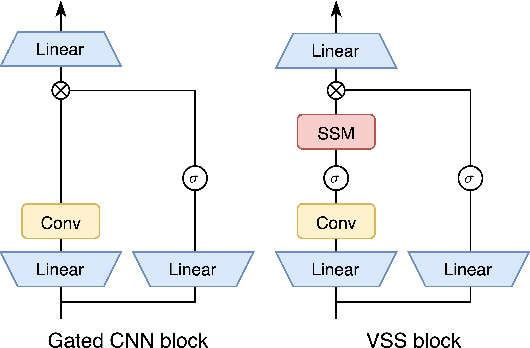
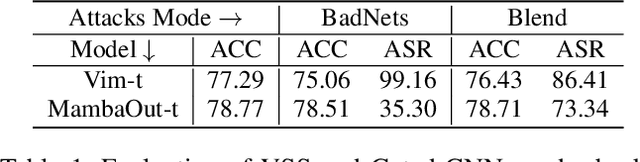

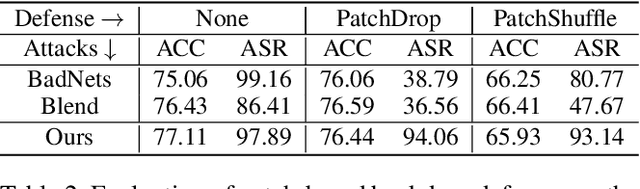
Visual State Space Model (VSS) has demonstrated remarkable performance in various computer vision tasks. However, in the process of development, backdoor attacks have brought severe challenges to security. Such attacks cause an infected model to predict target labels when a specific trigger is activated, while the model behaves normally on benign samples. In this paper, we conduct systematic experiments to comprehend on robustness of VSS through the lens of backdoor attacks, specifically how the state space model (SSM) mechanism affects robustness. We first investigate the vulnerability of VSS to different backdoor triggers and reveal that the SSM mechanism, which captures contextual information within patches, makes the VSS model more susceptible to backdoor triggers compared to models without SSM. Furthermore, we analyze the sensitivity of the VSS model to patch processing techniques and discover that these triggers are effectively disrupted. Based on these observations, we consider an effective backdoor for the VSS model that recurs in each patch to resist patch perturbations. Extensive experiments across three datasets and various backdoor attacks reveal that the VSS model performs comparably to Transformers (ViTs) but is less robust than the Gated CNNs, which comprise only stacked Gated CNN blocks without SSM.
Defending Against Repetitive-based Backdoor Attacks on Semi-supervised Learning through Lens of Rate-Distortion-Perception Trade-off
Jul 14, 2024Semi-supervised learning (SSL) has achieved remarkable performance with a small fraction of labeled data by leveraging vast amounts of unlabeled data from the Internet. However, this large pool of untrusted data is extremely vulnerable to data poisoning, leading to potential backdoor attacks. Current backdoor defenses are not yet effective against such a vulnerability in SSL. In this study, we propose a novel method, Unlabeled Data Purification (UPure), to disrupt the association between trigger patterns and target classes by introducing perturbations in the frequency domain. By leveraging the Rate- Distortion-Perception (RDP) trade-off, we further identify the frequency band, where the perturbations are added, and justify this selection. Notably, UPure purifies poisoned unlabeled data without the need of extra clean labeled data. Extensive experiments on four benchmark datasets and five SSL algorithms demonstrate that UPure effectively reduces the attack success rate from 99.78% to 0% while maintaining model accuracy