 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestore, Assess, Repeat: A Unified Framework for Iterative Image Restoration
Mar 27, 2026Image restoration aims to recover high quality images from inputs degraded by various factors, such as adverse weather, blur, or low light. While recent studies have shown remarkable progress across individual or unified restoration tasks, they still suffer from limited generalization and inefficiency when handling unknown or composite degradations. To address these limitations, we propose RAR, a Restore, Assess and Repeat process, that integrates Image Quality Assessment (IQA) and Image Restoration (IR) into a unified framework to iteratively and efficiently achieve high quality image restoration. Specifically, we introduce a restoration process that operates entirely in the latent domain to jointly perform degradation identification, image restoration, and quality verification. The resulting model is fully trainable end to end and allows for an all-in-one assess and restore approach that dynamically adapts the restoration process. Also, the tight integration of IQA and IR into a unified model minimizes the latency and information loss that typically arises from keeping the two modules disjoint, (e.g. during image and/or text decoding). Extensive experiments show that our approach consistent improvements under single, unknown and composite degradations, thereby establishing a new state-of-the-art.
Self-Reinforced Graph Contrastive Learning
May 19, 2025



Graphs serve as versatile data structures in numerous real-world domains-including social networks, molecular biology, and knowledge graphs-by capturing intricate relational information among entities. Among graph-based learning techniques, Graph Contrastive Learning (GCL) has gained significant attention for its ability to derive robust, self-supervised graph representations through the contrasting of positive and negative sample pairs. However, a critical challenge lies in ensuring high-quality positive pairs so that the intrinsic semantic and structural properties of the original graph are preserved rather than distorted. To address this issue, we propose SRGCL (Self-Reinforced Graph Contrastive Learning), a novel framework that leverages the model's own encoder to dynamically evaluate and select high-quality positive pairs. We designed a unified positive pair generator employing multiple augmentation strategies, and a selector guided by the manifold hypothesis to maintain the underlying geometry of the latent space. By adopting a probabilistic mechanism for selecting positive pairs, SRGCL iteratively refines its assessment of pair quality as the encoder's representational power improves. Extensive experiments on diverse graph-level classification tasks demonstrate that SRGCL, as a plug-in module, consistently outperforms state-of-the-art GCL methods, underscoring its adaptability and efficacy across various domains.
DiffVQA: Video Quality Assessment Using Diffusion Feature Extractor
May 06, 2025Video Quality Assessment (VQA) aims to evaluate video quality based on perceptual distortions and human preferences. Despite the promising performance of existing methods using Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), they often struggle to align closely with human perceptions, particularly in diverse real-world scenarios. This challenge is exacerbated by the limited scale and diversity of available datasets. To address this limitation, we introduce a novel VQA framework, DiffVQA, which harnesses the robust generalization capabilities of diffusion models pre-trained on extensive datasets. Our framework adapts these models to reconstruct identical input frames through a control module. The adapted diffusion model is then used to extract semantic and distortion features from a resizing branch and a cropping branch, respectively. To enhance the model's ability to handle long-term temporal dynamics, a parallel Mamba module is introduced, which extracts temporal coherence augmented features that are merged with the diffusion features to predict the final score. Experiments across multiple datasets demonstrate DiffVQA's superior performance on intra-dataset evaluations and its exceptional generalization across datasets. These results confirm that leveraging a diffusion model as a feature extractor can offer enhanced VQA performance compared to CNN and ViT backbones.
Data Poisoning Attacks to Locally Differentially Private Range Query Protocols
Mar 05, 2025



Trajectory data, which tracks movements through geographic locations, is crucial for improving real-world applications. However, collecting such sensitive data raises considerable privacy concerns. Local differential privacy (LDP) offers a solution by allowing individuals to locally perturb their trajectory data before sharing it. Despite its privacy benefits, LDP protocols are vulnerable to data poisoning attacks, where attackers inject fake data to manipulate aggregated results. In this work, we make the first attempt to analyze vulnerabilities in several representative LDP trajectory protocols. We propose \textsc{TraP}, a heuristic algorithm for data \underline{P}oisoning attacks using a prefix-suffix method to optimize fake \underline{Tra}jectory selection, significantly reducing computational complexity. Our experimental results demonstrate that our attack can substantially increase target pattern occurrences in the perturbed trajectory dataset with few fake users. This study underscores the urgent need for robust defenses and better protocol designs to safeguard LDP trajectory data against malicious manipulation.
DSL-FIQA: Assessing Facial Image Quality via Dual-Set Degradation Learning and Landmark-Guided Transformer
Jun 13, 2024Generic Face Image Quality Assessment (GFIQA) evaluates the perceptual quality of facial images, which is crucial in improving image restoration algorithms and selecting high-quality face images for downstream tasks. We present a novel transformer-based method for GFIQA, which is aided by two unique mechanisms. First, a Dual-Set Degradation Representation Learning (DSL) mechanism uses facial images with both synthetic and real degradations to decouple degradation from content, ensuring generalizability to real-world scenarios. This self-supervised method learns degradation features on a global scale, providing a robust alternative to conventional methods that use local patch information in degradation learning. Second, our transformer leverages facial landmarks to emphasize visually salient parts of a face image in evaluating its perceptual quality. We also introduce a balanced and diverse Comprehensive Generic Face IQA (CGFIQA-40k) dataset of 40K images carefully designed to overcome the biases, in particular the imbalances in skin tone and gender representation, in existing datasets. Extensive analysis and evaluation demonstrate the robustness of our method, marking a significant improvement over prior methods.
RobustSAM: Segment Anything Robustly on Degraded Images
Jun 13, 2024Segment Anything Model (SAM) has emerged as a transformative approach in image segmentation, acclaimed for its robust zero-shot segmentation capabilities and flexible prompting system. Nonetheless, its performance is challenged by images with degraded quality. Addressing this limitation, we propose the Robust Segment Anything Model (RobustSAM), which enhances SAM's performance on low-quality images while preserving its promptability and zero-shot generalization. Our method leverages the pre-trained SAM model with only marginal parameter increments and computational requirements. The additional parameters of RobustSAM can be optimized within 30 hours on eight GPUs, demonstrating its feasibility and practicality for typical research laboratories. We also introduce the Robust-Seg dataset, a collection of 688K image-mask pairs with different degradations designed to train and evaluate our model optimally. Extensive experiments across various segmentation tasks and datasets confirm RobustSAM's superior performance, especially under zero-shot conditions, underscoring its potential for extensive real-world application. Additionally, our method has been shown to effectively improve the performance of SAM-based downstream tasks such as single image dehazing and deblurring.
Improving Point-based Crowd Counting and Localization Based on Auxiliary Point Guidance
May 17, 2024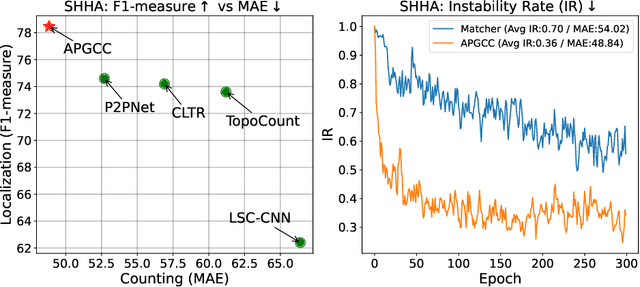
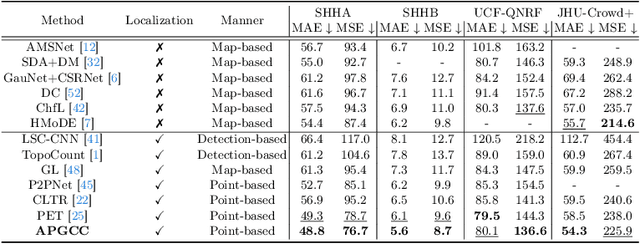
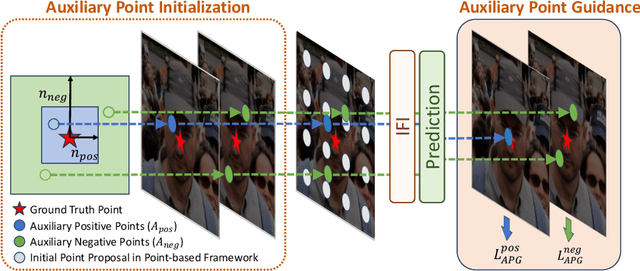
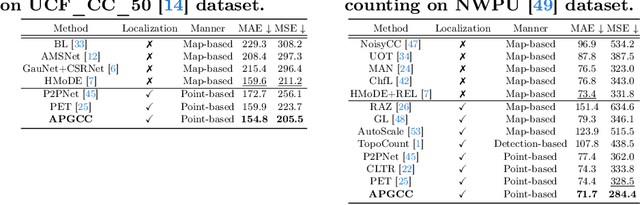
Crowd counting and localization have become increasingly important in computer vision due to their wide-ranging applications. While point-based strategies have been widely used in crowd counting methods, they face a significant challenge, i.e., the lack of an effective learning strategy to guide the matching process. This deficiency leads to instability in matching point proposals to target points, adversely affecting overall performance. To address this issue, we introduce an effective approach to stabilize the proposal-target matching in point-based methods. We propose Auxiliary Point Guidance (APG) to provide clear and effective guidance for proposal selection and optimization, addressing the core issue of matching uncertainty. Additionally, we develop Implicit Feature Interpolation (IFI) to enable adaptive feature extraction in diverse crowd scenarios, further enhancing the model's robustness and accuracy. Extensive experiments demonstrate the effectiveness of our approach, showing significant improvements in crowd counting and localization performance, particularly under challenging conditions. The source codes and trained models will be made publicly available.
Rethinking Backdoor Attacks on Dataset Distillation: A Kernel Method Perspective
Nov 28, 2023



Dataset distillation offers a potential means to enhance data efficiency in deep learning. Recent studies have shown its ability to counteract backdoor risks present in original training samples. In this study, we delve into the theoretical aspects of backdoor attacks and dataset distillation based on kernel methods. We introduce two new theory-driven trigger pattern generation methods specialized for dataset distillation. Following a comprehensive set of analyses and experiments, we show that our optimization-based trigger design framework informs effective backdoor attacks on dataset distillation. Notably, datasets poisoned by our designed trigger prove resilient against conventional backdoor attack detection and mitigation methods. Our empirical results validate that the triggers developed using our approaches are proficient at executing resilient backdoor attacks.
Counting Crowds in Bad Weather
Jun 02, 2023Crowd counting has recently attracted significant attention in the field of computer vision due to its wide applications to image understanding. Numerous methods have been proposed and achieved state-of-the-art performance for real-world tasks. However, existing approaches do not perform well under adverse weather such as haze, rain, and snow since the visual appearances of crowds in such scenes are drastically different from those images in clear weather of typical datasets. In this paper, we propose a method for robust crowd counting in adverse weather scenarios. Instead of using a two-stage approach that involves image restoration and crowd counting modules, our model learns effective features and adaptive queries to account for large appearance variations. With these weather queries, the proposed model can learn the weather information according to the degradation of the input image and optimize with the crowd counting module simultaneously. Experimental results show that the proposed algorithm is effective in counting crowds under different weather types on benchmark datasets. The source code and trained models will be made available to the public.
DehazeNeRF: Multiple Image Haze Removal and 3D Shape Reconstruction using Neural Radiance Fields
Mar 20, 2023



Neural radiance fields (NeRFs) have demonstrated state-of-the-art performance for 3D computer vision tasks, including novel view synthesis and 3D shape reconstruction. However, these methods fail in adverse weather conditions. To address this challenge, we introduce DehazeNeRF as a framework that robustly operates in hazy conditions. DehazeNeRF extends the volume rendering equation by adding physically realistic terms that model atmospheric scattering. By parameterizing these terms using suitable networks that match the physical properties, we introduce effective inductive biases, which, together with the proposed regularizations, allow DehazeNeRF to demonstrate successful multi-view haze removal, novel view synthesis, and 3D shape reconstruction where existing approaches fail.