 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVP-NTK: Exploring the Benefits of Visual Prompting in Differentially Private Data Synthesis
Mar 20, 2025Differentially private (DP) synthetic data has become the de facto standard for releasing sensitive data. However, many DP generative models suffer from the low utility of synthetic data, especially for high-resolution images. On the other hand, one of the emerging techniques in parameter efficient fine-tuning (PEFT) is visual prompting (VP), which allows well-trained existing models to be reused for the purpose of adapting to subsequent downstream tasks. In this work, we explore such a phenomenon in constructing captivating generative models with DP constraints. We show that VP in conjunction with DP-NTK, a DP generator that exploits the power of the neural tangent kernel (NTK) in training DP generative models, achieves a significant performance boost, particularly for high-resolution image datasets, with accuracy improving from 0.644$\pm$0.044 to 0.769. Lastly, we perform ablation studies on the effect of different parameters that influence the overall performance of VP-NTK. Our work demonstrates a promising step forward in improving the utility of DP synthetic data, particularly for high-resolution images.
Data Poisoning Attacks to Locally Differentially Private Range Query Protocols
Mar 05, 2025Trajectory data, which tracks movements through geographic locations, is crucial for improving real-world applications. However, collecting such sensitive data raises considerable privacy concerns. Local differential privacy (LDP) offers a solution by allowing individuals to locally perturb their trajectory data before sharing it. Despite its privacy benefits, LDP protocols are vulnerable to data poisoning attacks, where attackers inject fake data to manipulate aggregated results. In this work, we make the first attempt to analyze vulnerabilities in several representative LDP trajectory protocols. We propose \textsc{TraP}, a heuristic algorithm for data \underline{P}oisoning attacks using a prefix-suffix method to optimize fake \underline{Tra}jectory selection, significantly reducing computational complexity. Our experimental results demonstrate that our attack can substantially increase target pattern occurrences in the perturbed trajectory dataset with few fake users. This study underscores the urgent need for robust defenses and better protocol designs to safeguard LDP trajectory data against malicious manipulation.
BADTV: Unveiling Backdoor Threats in Third-Party Task Vectors
Jan 04, 2025Task arithmetic in large-scale pre-trained models enables flexible adaptation to diverse downstream tasks without extensive re-training. By leveraging task vectors (TVs), users can perform modular updates to pre-trained models through simple arithmetic operations like addition and subtraction. However, this flexibility introduces new security vulnerabilities. In this paper, we identify and evaluate the susceptibility of TVs to backdoor attacks, demonstrating how malicious actors can exploit TVs to compromise model integrity. By developing composite backdoors and eliminating redudant clean tasks, we introduce BadTV, a novel backdoor attack specifically designed to remain effective under task learning, forgetting, and analogies operations. Our extensive experiments reveal that BadTV achieves near-perfect attack success rates across various scenarios, significantly impacting the security of models using task arithmetic. We also explore existing defenses, showing that current methods fail to detect or mitigate BadTV. Our findings highlight the need for robust defense mechanisms to secure TVs in real-world applications, especially as TV services become more popular in machine-learning ecosystems.
Safe LoRA: the Silver Lining of Reducing Safety Risks when Fine-tuning Large Language Models
May 27, 2024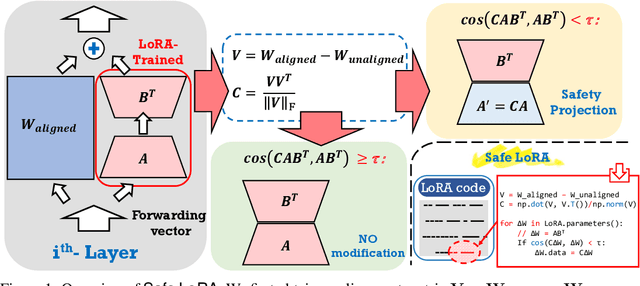

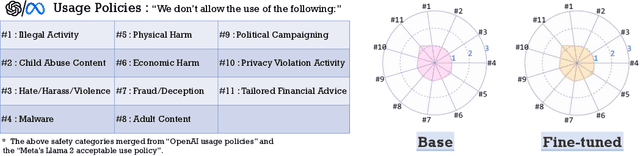
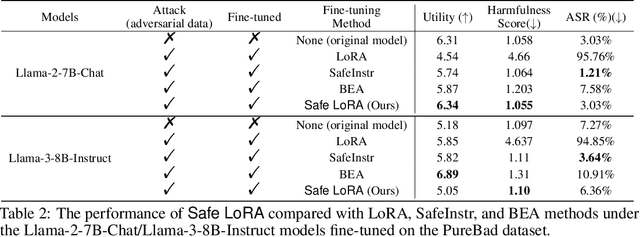
While large language models (LLMs) such as Llama-2 or GPT-4 have shown impressive zero-shot performance, fine-tuning is still necessary to enhance their performance for customized datasets, domain-specific tasks, or other private needs. However, fine-tuning all parameters of LLMs requires significant hardware resources, which can be impractical for typical users. Therefore, parameter-efficient fine-tuning such as LoRA have emerged, allowing users to fine-tune LLMs without the need for considerable computing resources, with little performance degradation compared to fine-tuning all parameters. Unfortunately, recent studies indicate that fine-tuning can increase the risk to the safety of LLMs, even when data does not contain malicious content. To address this challenge, we propose Safe LoRA, a simple one-liner patch to the original LoRA implementation by introducing the projection of LoRA weights from selected layers to the safety-aligned subspace, effectively reducing the safety risks in LLM fine-tuning while maintaining utility. It is worth noting that Safe LoRA is a training-free and data-free approach, as it only requires the knowledge of the weights from the base and aligned LLMs. Our extensive experiments demonstrate that when fine-tuning on purely malicious data, Safe LoRA retains similar safety performance as the original aligned model. Moreover, when the fine-tuning dataset contains a mixture of both benign and malicious data, Safe LoRA mitigates the negative effect made by malicious data while preserving performance on downstream tasks.
Ring-A-Bell! How Reliable are Concept Removal Methods for Diffusion Models?
Oct 16, 2023


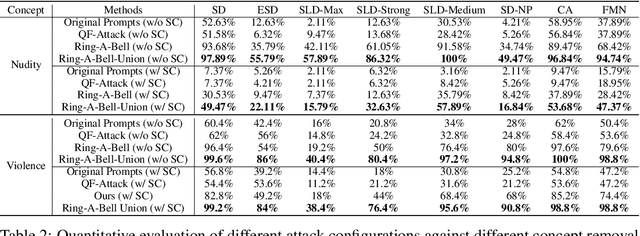
Diffusion models for text-to-image (T2I) synthesis, such as Stable Diffusion (SD), have recently demonstrated exceptional capabilities for generating high-quality content. However, this progress has raised several concerns of potential misuse, particularly in creating copyrighted, prohibited, and restricted content, or NSFW (not safe for work) images. While efforts have been made to mitigate such problems, either by implementing a safety filter at the evaluation stage or by fine-tuning models to eliminate undesirable concepts or styles, the effectiveness of these safety measures in dealing with a wide range of prompts remains largely unexplored. In this work, we aim to investigate these safety mechanisms by proposing one novel concept retrieval algorithm for evaluation. We introduce Ring-A-Bell, a model-agnostic red-teaming tool for T2I diffusion models, where the whole evaluation can be prepared in advance without prior knowledge of the target model. Specifically, Ring-A-Bell first performs concept extraction to obtain holistic representations for sensitive and inappropriate concepts. Subsequently, by leveraging the extracted concept, Ring-A-Bell automatically identifies problematic prompts for diffusion models with the corresponding generation of inappropriate content, allowing the user to assess the reliability of deployed safety mechanisms. Finally, we empirically validate our method by testing online services such as Midjourney and various methods of concept removal. Our results show that Ring-A-Bell, by manipulating safe prompting benchmarks, can transform prompts that were originally regarded as safe to evade existing safety mechanisms, thus revealing the defects of the so-called safety mechanisms which could practically lead to the generation of harmful contents.
DPAF: Image Synthesis via Differentially Private Aggregation in Forward Phase
Apr 20, 2023
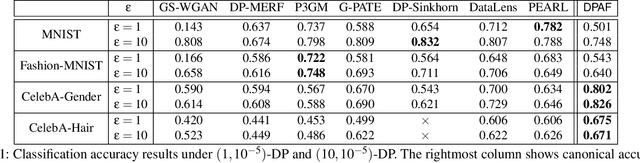

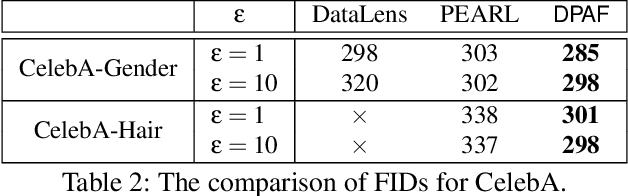
Differentially private synthetic data is a promising alternative for sensitive data release. Many differentially private generative models have been proposed in the literature. Unfortunately, they all suffer from the low utility of the synthetic data, particularly for images of high resolutions. Here, we propose DPAF, an effective differentially private generative model for high-dimensional image synthesis. Different from the prior private stochastic gradient descent-based methods that add Gaussian noises in the backward phase during the model training, DPAF adds a differentially private feature aggregation in the forward phase, bringing advantages, including the reduction of information loss in gradient clipping and low sensitivity for the aggregation. Moreover, as an improper batch size has an adverse impact on the utility of synthetic data, DPAF also tackles the problem of setting a proper batch size by proposing a novel training strategy that asymmetrically trains different parts of the discriminator. We extensively evaluate different methods on multiple image datasets (up to images of 128x128 resolution) to demonstrate the performance of DPAF.