 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Benchmarks Leak: Inference-Time Decontamination for LLMs
Jan 27, 2026Benchmark-based evaluation is the de facto standard for comparing large language models (LLMs). However, its reliability is increasingly threatened by test set contamination, where test samples or their close variants leak into training data and artificially inflate reported performance. To address this issue, prior work has explored two main lines of mitigation. One line attempts to identify and remove contaminated benchmark items before evaluation, but this inevitably alters the evaluation set itself and becomes unreliable when contamination is moderate or severe. The other line preserves the benchmark and instead suppresses contaminated behavior at evaluation time; however, such interventions often interfere with normal inference and lead to noticeable performance degradation on clean inputs. We propose DeconIEP, a decontamination framework that operates entirely during evaluation by applying small, bounded perturbations in the input embedding space. Guided by a relatively less-contaminated reference model, DeconIEP learns an instance-adaptive perturbation generator that steers the evaluated model away from memorization-driven shortcut pathways. Across multiple open-weight LLMs and benchmarks, extensive empirical results show that DeconIEP achieves strong decontamination effectiveness while incurring only minimal degradation in benign utility.
Disrupting Model Merging: A Parameter-Level Defense Without Sacrificing Accuracy
Mar 08, 2025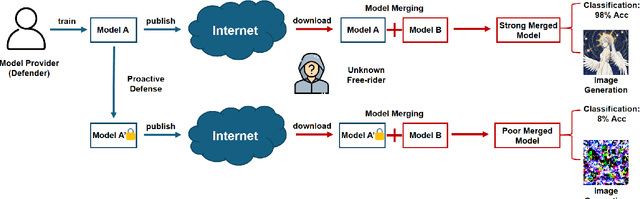
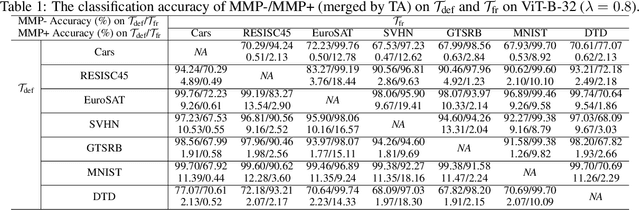
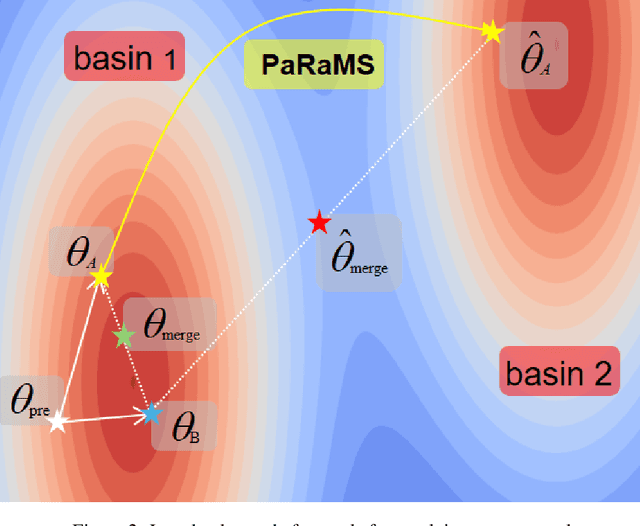

Model merging is a technique that combines multiple finetuned models into a single model without additional training, allowing a free-rider to cheaply inherit specialized capabilities. This study investigates methodologies to suppress unwanted model merging by free-riders. Existing methods such as model watermarking or fingerprinting can only detect merging in hindsight. In contrast, we propose a first proactive defense against model merging. Specifically, our defense method modifies the model parameters so that the model is disrupted if the model is merged with any other model, while its functionality is kept unchanged if not merged with others. Our approach consists of two modules, rearranging MLP parameters and scaling attention heads, which push the model out of the shared basin in parameter space, causing the merging performance with other models to degrade significantly. We conduct extensive experiments on image classification, image generation, and text classification to demonstrate that our defense severely disrupts merging while retaining the functionality of the post-protect model. Moreover, we analyze potential adaptive attacks and further propose a dropout-based pruning to improve our proposal's robustness.
BADTV: Unveiling Backdoor Threats in Third-Party Task Vectors
Jan 04, 2025Task arithmetic in large-scale pre-trained models enables flexible adaptation to diverse downstream tasks without extensive re-training. By leveraging task vectors (TVs), users can perform modular updates to pre-trained models through simple arithmetic operations like addition and subtraction. However, this flexibility introduces new security vulnerabilities. In this paper, we identify and evaluate the susceptibility of TVs to backdoor attacks, demonstrating how malicious actors can exploit TVs to compromise model integrity. By developing composite backdoors and eliminating redudant clean tasks, we introduce BadTV, a novel backdoor attack specifically designed to remain effective under task learning, forgetting, and analogies operations. Our extensive experiments reveal that BadTV achieves near-perfect attack success rates across various scenarios, significantly impacting the security of models using task arithmetic. We also explore existing defenses, showing that current methods fail to detect or mitigate BadTV. Our findings highlight the need for robust defense mechanisms to secure TVs in real-world applications, especially as TV services become more popular in machine-learning ecosystems.
Parameter Matching Attack: Enhancing Practical Applicability of Availability Attacks
Jul 02, 2024
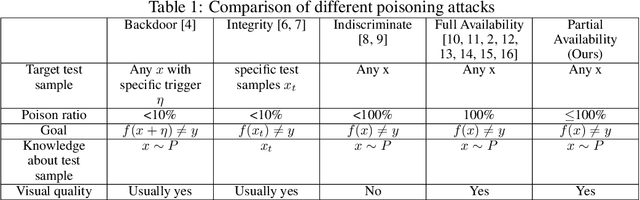


The widespread use of personal data for training machine learning models raises significant privacy concerns, as individuals have limited control over how their public data is subsequently utilized. Availability attacks have emerged as a means for data owners to safeguard their data by desning imperceptible perturbations that degrade model performance when incorporated into training datasets. However, existing availability attacks exhibit limitations in practical applicability, particularly when only a portion of the data can be perturbed. To address this challenge, we propose a novel availability attack approach termed Parameter Matching Attack (PMA). PMA is the first availability attack that works when only a portion of data can be perturbed. PMA optimizes perturbations so that when the model is trained on a mixture of clean and perturbed data, the resulting model will approach a model designed to perform poorly. Experimental results across four datasets demonstrate that PMA outperforms existing methods, achieving significant model performance degradation when a part of the training data is perturbed. Our code is available in the supplementary.
Zero-shot domain adaptation based on dual-level mix and contrast
Jun 27, 2024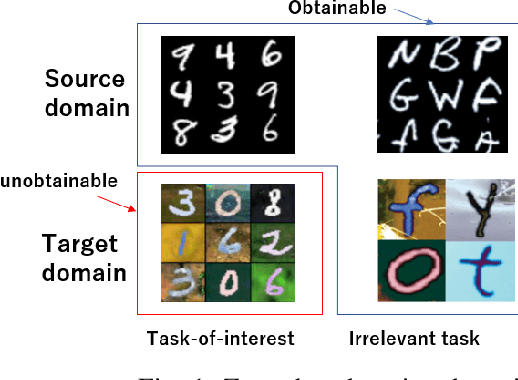
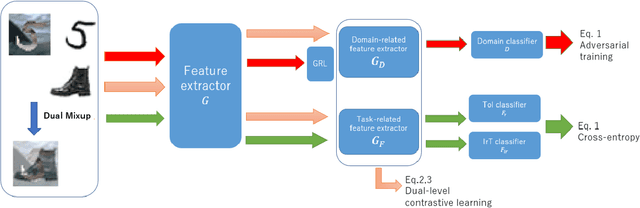
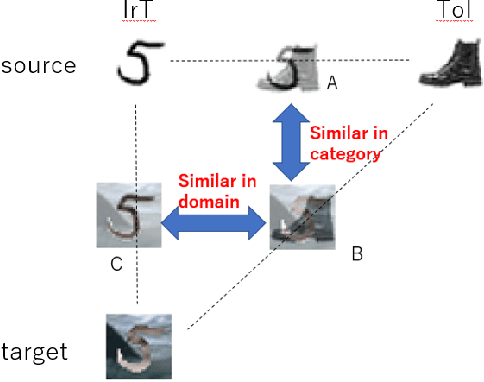
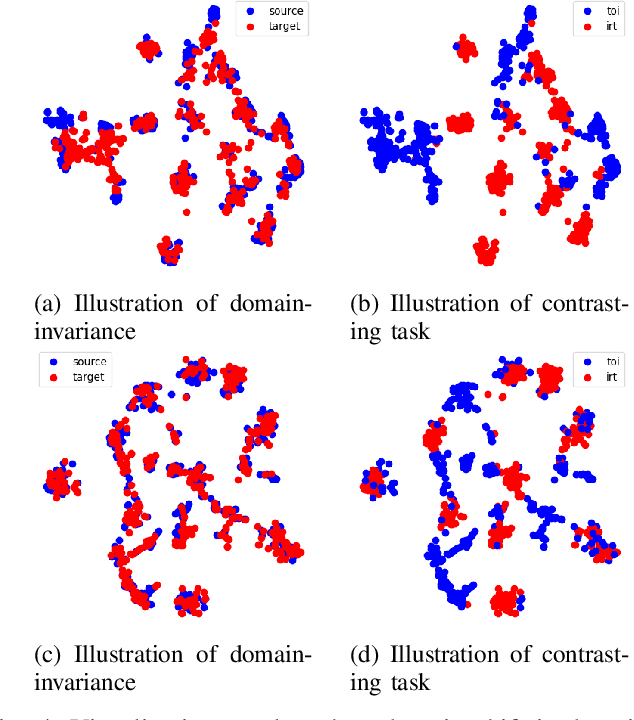
Zero-shot domain adaptation (ZSDA) is a domain adaptation problem in the situation that labeled samples for a target task (task of interest) are only available from the source domain at training time, but for a task different from the task of interest (irrelevant task), labeled samples are available from both source and target domains. In this situation, classical domain adaptation techniques can only learn domain-invariant features in the irrelevant task. However, due to the difference in sample distribution between the two tasks, domain-invariant features learned in the irrelevant task are biased and not necessarily domain-invariant in the task of interest. To solve this problem, this paper proposes a new ZSDA method to learn domain-invariant features with low task bias. To this end, we propose (1) data augmentation with dual-level mixups in both task and domain to fill the absence of target task-of-interest data, (2) an extension of domain adversarial learning to learn domain-invariant features with less task bias, and (3) a new dual-level contrastive learning method that enhances domain-invariance and less task biasedness of features. Experimental results show that our proposal achieves good performance on several benchmarks.
Adversarial Attacks on Hidden Tasks in Multi-Task Learning
May 28, 2024
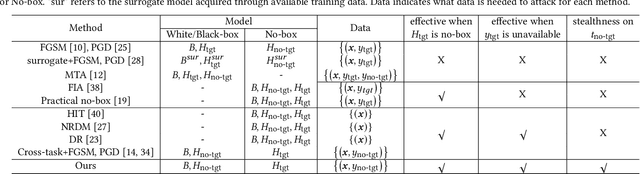

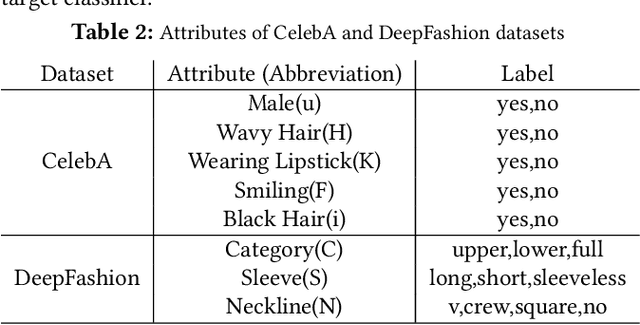
Deep learning models are susceptible to adversarial attacks, where slight perturbations to input data lead to misclassification. Adversarial attacks become increasingly effective with access to information about the targeted classifier. In the context of multi-task learning, where a single model learns multiple tasks simultaneously, attackers may aim to exploit vulnerabilities in specific tasks with limited information. This paper investigates the feasibility of attacking hidden tasks within multi-task classifiers, where model access regarding the hidden target task and labeled data for the hidden target task are not available, but model access regarding the non-target tasks is available. We propose a novel adversarial attack method that leverages knowledge from non-target tasks and the shared backbone network of the multi-task model to force the model to forget knowledge related to the target task. Experimental results on CelebA and DeepFashion datasets demonstrate the effectiveness of our method in degrading the accuracy of hidden tasks while preserving the performance of visible tasks, contributing to the understanding of adversarial vulnerabilities in multi-task classifiers.