 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Data Scaling Law for Meta Learning via Complexity Minimization
Jun 01, 2026Pre-training has become a fundamental paradigm in modern machine learning, with one of its key empirical benefits being reduced downstream sample complexity as the scale of pre-training data increases. However, existing theoretical frameworks for pre-training do not fully explain this phenomenon. In this paper, we introduce complexity minimization, a novel meta-representation learning framework designed to enable theoretical analysis of this scaling behavior, which learns representations by evaluating the downstream model complexity best suited to each domain and minimizing the worst-case such complexity across source domains. Our end-to-end theoretical analysis, spanning pre-training through downstream regression, shows that this framework provably captures this scaling behavior; in particular, we show that the error rate of few-shot adaptation improves as the amount of meta-training data grows. Empirically, we demonstrate that incorporating complexity regularization into existing meta-learning methods consistently improves downstream sample efficiency.
Provable Target Sample Complexity Improvements as Pre-Trained Models Scale
Feb 04, 2026Pre-trained models have become indispensable for efficiently building models across a broad spectrum of downstream tasks. The advantages of pre-trained models have been highlighted by empirical studies on scaling laws, which demonstrate that larger pre-trained models can significantly reduce the sample complexity of downstream learning. However, existing theoretical investigations of pre-trained models lack the capability to explain this phenomenon. In this paper, we provide a theoretical investigation by introducing a novel framework, caulking, inspired by parameter-efficient fine-tuning (PEFT) methods such as adapter-based fine-tuning, low-rank adaptation, and partial fine-tuning. Our analysis establishes that improved pre-trained models provably decrease the sample complexity of downstream tasks, thereby offering theoretical justification for the empirically observed scaling laws relating pre-trained model size to downstream performance, a relationship not covered by existing results.
Behavior-Targeted Attack on Reinforcement Learning with Limited Access to Victim's Policy
Jun 06, 2024This study considers the attack on reinforcement learning agents where the adversary aims to control the victim's behavior as specified by the adversary by adding adversarial modifications to the victim's state observation. While some attack methods reported success in manipulating the victim agent's behavior, these methods often rely on environment-specific heuristics. In addition, all existing attack methods require white-box access to the victim's policy. In this study, we propose a novel method for manipulating the victim agent in the black-box (i.e., the adversary is allowed to observe the victim's state and action only) and no-box (i.e., the adversary is allowed to observe the victim's state only) setting without requiring environment-specific heuristics. Our attack method is formulated as a bi-level optimization problem that is reduced to a distribution matching problem and can be solved by an existing imitation learning algorithm in the black-box and no-box settings. Empirical evaluations on several reinforcement learning benchmarks show that our proposed method has superior attack performance to baselines.
Adversarial Attacks on Hidden Tasks in Multi-Task Learning
May 28, 2024
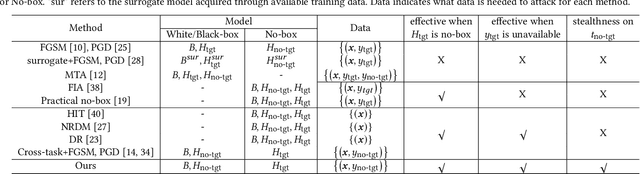

Deep learning models are susceptible to adversarial attacks, where slight perturbations to input data lead to misclassification. Adversarial attacks become increasingly effective with access to information about the targeted classifier. In the context of multi-task learning, where a single model learns multiple tasks simultaneously, attackers may aim to exploit vulnerabilities in specific tasks with limited information. This paper investigates the feasibility of attacking hidden tasks within multi-task classifiers, where model access regarding the hidden target task and labeled data for the hidden target task are not available, but model access regarding the non-target tasks is available. We propose a novel adversarial attack method that leverages knowledge from non-target tasks and the shared backbone network of the multi-task model to force the model to forget knowledge related to the target task. Experimental results on CelebA and DeepFashion datasets demonstrate the effectiveness of our method in degrading the accuracy of hidden tasks while preserving the performance of visible tasks, contributing to the understanding of adversarial vulnerabilities in multi-task classifiers.
Harnessing the Power of Vicinity-Informed Analysis for Classification under Covariate Shift
May 27, 2024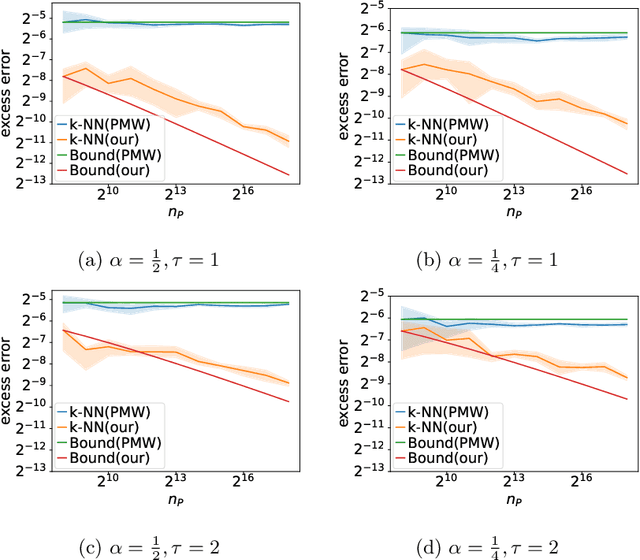
Transfer learning enhances prediction accuracy on a target distribution by leveraging data from a source distribution, demonstrating significant benefits in various applications. This paper introduces a novel dissimilarity measure that utilizes vicinity information, i.e., the local structure of data points, to analyze the excess error in classification under covariate shift, a transfer learning setting where marginal feature distributions differ but conditional label distributions remain the same. We characterize the excess error using the proposed measure and demonstrate faster or competitive convergence rates compared to previous techniques. Notably, our approach is effective in situations where the non-absolute continuousness assumption, which often appears in real-world applications, holds. Our theoretical analysis bridges the gap between current theoretical findings and empirical observations in transfer learning, particularly in scenarios with significant differences between source and target distributions.
Statistically Significant Concept-based Explanation of Image Classifiers via Model Knockoffs
May 31, 2023



A concept-based classifier can explain the decision process of a deep learning model by human-understandable concepts in image classification problems. However, sometimes concept-based explanations may cause false positives, which misregards unrelated concepts as important for the prediction task. Our goal is to find the statistically significant concept for classification to prevent misinterpretation. In this study, we propose a method using a deep learning model to learn the image concept and then using the Knockoff samples to select the important concepts for prediction by controlling the False Discovery Rate (FDR) under a certain value. We evaluate the proposed method in our synthetic and real data experiments. Also, it shows that our method can control the FDR properly while selecting highly interpretable concepts to improve the trustworthiness of the model.
Covariance Matrix Adaptation Evolutionary Strategy with Worst-Case Ranking Approximation for Min--Max Optimization and its Application to Berthing Control Tasks
Mar 28, 2023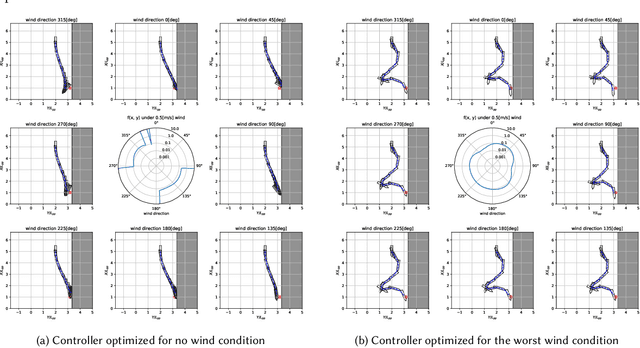

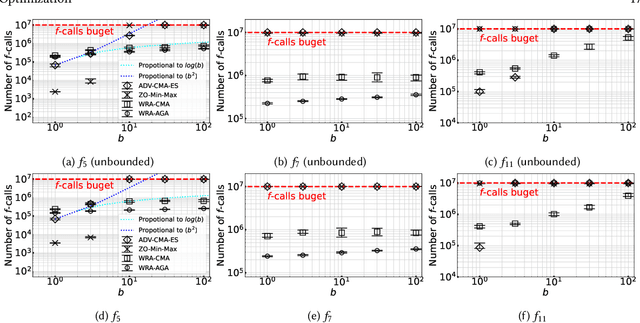
In this study, we consider a continuous min--max optimization problem $\min_{x \in \mathbb{X} \max_{y \in \mathbb{Y}}}f(x,y)$ whose objective function is a black-box. We propose a novel approach to minimize the worst-case objective function $F(x) = \max_{y} f(x,y)$ directly using a covariance matrix adaptation evolution strategy (CMA-ES) in which the rankings of solution candidates are approximated by our proposed worst-case ranking approximation (WRA) mechanism. We develop two variants of WRA combined with CMA-ES and approximate gradient ascent as numerical solvers for the inner maximization problem. Numerical experiments show that our proposed approach outperforms several existing approaches when the objective function is a smooth strongly convex--concave function and the interaction between $x$ and $y$ is strong. We investigate the advantages of the proposed approach for problems where the objective function is not limited to smooth strongly convex--concave functions. The effectiveness of the proposed approach is demonstrated in the robust berthing control problem with uncertainty.ngly convex--concave functions. The effectiveness of the proposed approach is demonstrated in the robust berthing control problem with uncertainty.
Few-Shot Image-to-Semantics Translation for Policy Transfer in Reinforcement Learning
Jan 31, 2023We investigate policy transfer using image-to-semantics translation to mitigate learning difficulties in vision-based robotics control agents. This problem assumes two environments: a simulator environment with semantics, that is, low-dimensional and essential information, as the state space, and a real-world environment with images as the state space. By learning mapping from images to semantics, we can transfer a policy, pre-trained in the simulator, to the real world, thereby eliminating real-world on-policy agent interactions to learn, which are costly and risky. In addition, using image-to-semantics mapping is advantageous in terms of the computational efficiency to train the policy and the interpretability of the obtained policy over other types of sim-to-real transfer strategies. To tackle the main difficulty in learning image-to-semantics mapping, namely the human annotation cost for producing a training dataset, we propose two techniques: pair augmentation with the transition function in the simulator environment and active learning. We observed a reduction in the annotation cost without a decline in the performance of the transfer, and the proposed approach outperformed the existing approach without annotation.
Adaptive Scenario Subset Selection for Worst-Case Optimization and its Application to Well Placement Optimization
Nov 29, 2022



In this study, we consider simulation-based worst-case optimization problems with continuous design variables and a finite scenario set. To reduce the number of simulations required and increase the number of restarts for better local optimum solutions, we propose a new approach referred to as adaptive scenario subset selection (AS3). The proposed approach subsamples a scenario subset as a support to construct the worst-case function in a given neighborhood, and we introduce such a scenario subset. Moreover, we develop a new optimization algorithm by combining AS3 and the covariance matrix adaptation evolution strategy (CMA-ES), denoted AS3-CMA-ES. At each algorithmic iteration, a subset of support scenarios is selected, and CMA-ES attempts to optimize the worst-case objective computed only through a subset of the scenarios. The proposed algorithm reduces the number of simulations required by executing simulations on only a scenario subset, rather than on all scenarios. In numerical experiments, we verified that AS3-CMA-ES is more efficient in terms of the number of simulations than the brute-force approach and a surrogate-assisted approach lq-CMA-ES when the ratio of the number of support scenarios to the total number of scenarios is relatively small. In addition, the usefulness of AS3-CMA-ES was evaluated for well placement optimization for carbon dioxide capture and storage (CCS). In comparison with the brute-force approach and lq-CMA-ES, AS3-CMA-ES was able to find better solutions because of more frequent restarts.
Max-Min Off-Policy Actor-Critic Method Focusing on Worst-Case Robustness to Model Misspecification
Nov 07, 2022In the field of reinforcement learning, because of the high cost and risk of policy training in the real world, policies are trained in a simulation environment and transferred to the corresponding real-world environment. However, the simulation environment does not perfectly mimic the real-world environment, lead to model misspecification. Multiple studies report significant deterioration of policy performance in a real-world environment. In this study, we focus on scenarios involving a simulation environment with uncertainty parameters and the set of their possible values, called the uncertainty parameter set. The aim is to optimize the worst-case performance on the uncertainty parameter set to guarantee the performance in the corresponding real-world environment. To obtain a policy for the optimization, we propose an off-policy actor-critic approach called the Max-Min Twin Delayed Deep Deterministic Policy Gradient algorithm (M2TD3), which solves a max-min optimization problem using a simultaneous gradient ascent descent approach. Experiments in multi-joint dynamics with contact (MuJoCo) environments show that the proposed method exhibited a worst-case performance superior to several baseline approaches.