 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Efficient Hypergradient Estimation for Decentralized Bi-Level Reinforcement Learning
Mar 16, 2026Many strategic decision-making problems, such as environment design for warehouse robots, can be naturally formulated as bi-level reinforcement learning (RL), where a leader agent optimizes its objective while a follower solves a Markov decision process (MDP) conditioned on the leader's decisions. In many situations, a fundamental challenge arises when the leader cannot intervene in the follower's optimization process; it can only observe the optimization outcome. We address this decentralized setting by deriving the hypergradient of the leader's objective, i.e., the gradient of the leader's strategy that accounts for changes in the follower's optimal policy. Unlike prior hypergradient-based methods that require extensive data for repeated state visits or rely on gradient estimators whose complexity can increase substantially with the high-dimensional leader's decision space, we leverage the Boltzmann covariance trick to derive an alternative hypergradient formulation. This enables efficient hypergradient estimation solely from interaction samples, even when the leader's decision space is high-dimensional. Additionally, to our knowledge, this is the first method that enables hypergradient-based optimization for 2-player Markov games in decentralized settings. Experiments highlight the impact of hypergradient updates and demonstrate our method's effectiveness in both discrete and continuous state tasks.
Cost-Minimized Label-Flipping Poisoning Attack to LLM Alignment
Nov 12, 2025Large language models (LLMs) are increasingly deployed in real-world systems, making it critical to understand their vulnerabilities. While data poisoning attacks during RLHF/DPO alignment have been studied empirically, their theoretical foundations remain unclear. We investigate the minimum-cost poisoning attack required to steer an LLM's policy toward an attacker's target by flipping preference labels during RLHF/DPO, without altering the compared outputs. We formulate this as a convex optimization problem with linear constraints, deriving lower and upper bounds on the minimum attack cost. As a byproduct of this theoretical analysis, we show that any existing label-flipping attack can be post-processed via our proposed method to reduce the number of label flips required while preserving the intended poisoning effect. Empirical results demonstrate that this cost-minimization post-processing can significantly reduce poisoning costs over baselines, particularly when the reward model's feature dimension is small relative to the dataset size. These findings highlight fundamental vulnerabilities in RLHF/DPO pipelines and provide tools to evaluate their robustness against low-cost poisoning attacks.
A Provable Approach for End-to-End Safe Reinforcement Learning
May 28, 2025A longstanding goal in safe reinforcement learning (RL) is a method to ensure the safety of a policy throughout the entire process, from learning to operation. However, existing safe RL paradigms inherently struggle to achieve this objective. We propose a method, called Provably Lifetime Safe RL (PLS), that integrates offline safe RL with safe policy deployment to address this challenge. Our proposed method learns a policy offline using return-conditioned supervised learning and then deploys the resulting policy while cautiously optimizing a limited set of parameters, known as target returns, using Gaussian processes (GPs). Theoretically, we justify the use of GPs by analyzing the mathematical relationship between target and actual returns. We then prove that PLS finds near-optimal target returns while guaranteeing safety with high probability. Empirically, we demonstrate that PLS outperforms baselines both in safety and reward performance, thereby achieving the longstanding goal to obtain high rewards while ensuring the safety of a policy throughout the lifetime from learning to operation.
Vulnerability Mitigation for Safety-Aligned Language Models via Debiasing
Feb 04, 2025Safety alignment is an essential research topic for real-world AI applications. Despite the multifaceted nature of safety and trustworthiness in AI, current safety alignment methods often focus on a comprehensive notion of safety. By carefully assessing models from the existing safety-alignment methods, we found that, while they generally improved overall safety performance, they failed to ensure safety in specific categories. Our study first identified the difficulty of eliminating such vulnerabilities without sacrificing the model's helpfulness. We observed that, while smaller KL penalty parameters, increased training iterations, and dataset cleansing can enhance safety, they do not necessarily improve the trade-off between safety and helpfulness. We discovered that safety alignment could even induce undesired effects and result in a model that prefers generating negative tokens leading to rejective responses, regardless of the input context. To address this, we introduced a learning-free method, Token-level Safety-Debiased Inference (TSDI), to estimate and correct this bias during the generation process using randomly constructed prompts. Our experiments demonstrated that our method could enhance the model's helpfulness while maintaining safety, thus improving the trade-off Pareto-front.
Stepwise Alignment for Constrained Language Model Policy Optimization
Apr 17, 2024Safety and trustworthiness are indispensable requirements for applying AI systems based on large language models (LLMs) in real-world applications. This paper formulates a human value alignment as a language model policy optimization problem to maximize reward under a safety constraint and then proposes an algorithm called Stepwise Alignment for Constrained Policy Optimization (SACPO). A key idea behind SACPO, supported by theory, is that the optimal policy incorporating both reward and safety can be directly obtained from a reward-aligned policy. Based on this key idea, SACPO aligns the LLMs with each metric step-wise while leveraging simple yet powerful alignment algorithms such as direct preference optimization (DPO). SACPO provides many benefits such as simplicity, stability, computational efficiency, and flexibility regarding algorithms and dataset selection. Under mild assumption, our theoretical analysis provides the upper bounds regarding near-optimality and safety constraint violation. Our experimental results show that SACPO can fine-tune Alpaca-7B better than the state-of-the-art method in terms of both helpfulness and harmlessness
Max-Min Off-Policy Actor-Critic Method Focusing on Worst-Case Robustness to Model Misspecification
Nov 07, 2022In the field of reinforcement learning, because of the high cost and risk of policy training in the real world, policies are trained in a simulation environment and transferred to the corresponding real-world environment. However, the simulation environment does not perfectly mimic the real-world environment, lead to model misspecification. Multiple studies report significant deterioration of policy performance in a real-world environment. In this study, we focus on scenarios involving a simulation environment with uncertainty parameters and the set of their possible values, called the uncertainty parameter set. The aim is to optimize the worst-case performance on the uncertainty parameter set to guarantee the performance in the corresponding real-world environment. To obtain a policy for the optimization, we propose an off-policy actor-critic approach called the Max-Min Twin Delayed Deep Deterministic Policy Gradient algorithm (M2TD3), which solves a max-min optimization problem using a simultaneous gradient ascent descent approach. Experiments in multi-joint dynamics with contact (MuJoCo) environments show that the proposed method exhibited a worst-case performance superior to several baseline approaches.
Level Generation for Angry Birds with Sequential VAE and Latent Variable Evolution
Apr 13, 2021

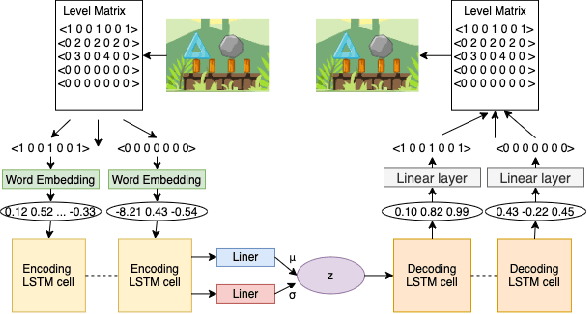

Video game level generation based on machine learning (ML), in particular, deep generative models, has attracted attention as a technique to automate level generation. However, applications of existing ML-based level generations are mostly limited to tile-based level representation. When ML techniques are applied to game domains with non-tile-based level representation, such as Angry Birds, where objects in a level are specified by real-valued parameters, ML often fails to generate playable levels. In this study, we develop a deep-generative-model-based level generation for the game domain of Angry Birds. To overcome these drawbacks, we propose a sequential encoding of a level and process it as text data, whereas existing approaches employ a tile-based encoding and process it as an image. Experiments show that the proposed level generator drastically improves the stability and diversity of generated levels compared with existing approaches. We apply latent variable evolution with the proposed generator to control the feature of a generated level computed through an AI agent's play, while keeping the level stable and natural.