 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVulnerability Mitigation for Safety-Aligned Language Models via Debiasing
Feb 04, 2025Safety alignment is an essential research topic for real-world AI applications. Despite the multifaceted nature of safety and trustworthiness in AI, current safety alignment methods often focus on a comprehensive notion of safety. By carefully assessing models from the existing safety-alignment methods, we found that, while they generally improved overall safety performance, they failed to ensure safety in specific categories. Our study first identified the difficulty of eliminating such vulnerabilities without sacrificing the model's helpfulness. We observed that, while smaller KL penalty parameters, increased training iterations, and dataset cleansing can enhance safety, they do not necessarily improve the trade-off between safety and helpfulness. We discovered that safety alignment could even induce undesired effects and result in a model that prefers generating negative tokens leading to rejective responses, regardless of the input context. To address this, we introduced a learning-free method, Token-level Safety-Debiased Inference (TSDI), to estimate and correct this bias during the generation process using randomly constructed prompts. Our experiments demonstrated that our method could enhance the model's helpfulness while maintaining safety, thus improving the trade-off Pareto-front.
Unsupervised Causal Binary Concepts Discovery with VAE for Black-box Model Explanation
Sep 09, 2021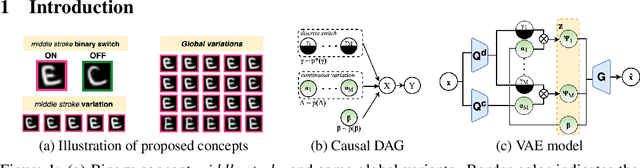
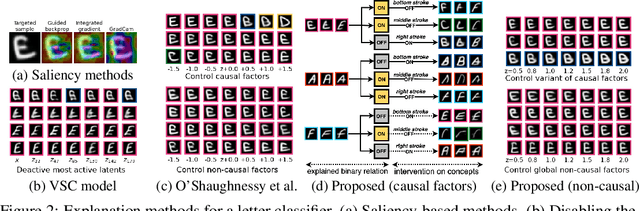

We aim to explain a black-box classifier with the form: `data X is classified as class Y because X \textit{has} A, B and \textit{does not have} C' in which A, B, and C are high-level concepts. The challenge is that we have to discover in an unsupervised manner a set of concepts, i.e., A, B and C, that is useful for the explaining the classifier. We first introduce a structural generative model that is suitable to express and discover such concepts. We then propose a learning process that simultaneously learns the data distribution and encourages certain concepts to have a large causal influence on the classifier output. Our method also allows easy integration of user's prior knowledge to induce high interpretability of concepts. Using multiple datasets, we demonstrate that our method can discover useful binary concepts for explanation.
Seasonal-adjustment Based Feature Selection Method for Large-scale Search Engine Logs
Aug 22, 2020
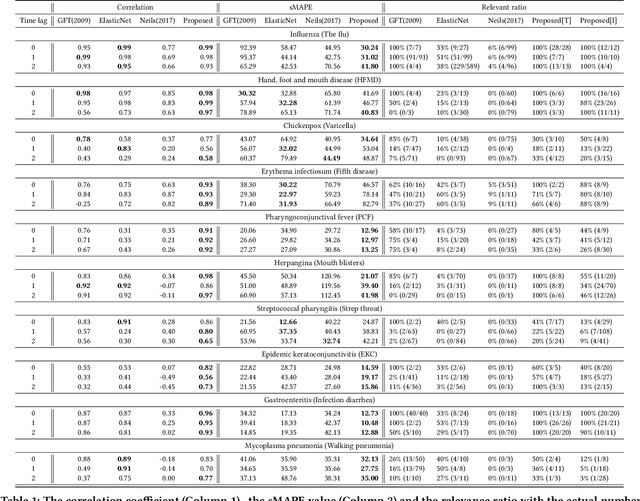
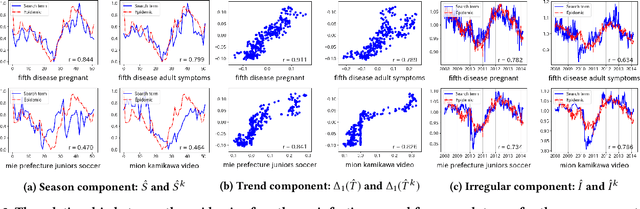
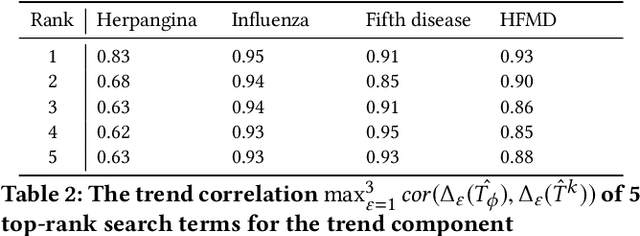
Search engine logs have a great potential in tracking and predicting outbreaks of infectious disease. More precisely, one can use the search volume of some search terms to predict the infection rate of an infectious disease in nearly real-time. However, conducting accurate and stable prediction of outbreaks using search engine logs is a challenging task due to the following two-way instability characteristics of the search logs. First, the search volume of a search term may change irregularly in the short-term, for example, due to environmental factors such as the amount of media or news. Second, the search volume may also change in the long-term due to the demographic change of the search engine. That is to say, if a model is trained with such search logs with ignoring such characteristic, the resulting prediction would contain serious mispredictions when these changes occur. In this work, we proposed a novel feature selection method to overcome this instability problem. In particular, we employ a seasonal-adjustment method that decomposes each time series into three components: seasonal, trend and irregular component and build prediction models for each component individually. We also carefully design a feature selection method to select proper search terms to predict each component. We conducted comprehensive experiments on ten different kinds of infectious diseases. The experimental results show that the proposed method outperforms all comparative methods in prediction accuracy for seven of ten diseases, in both now-casting and forecasting setting. Also, the proposed method is more successful in selecting search terms that are semantically related to target diseases.