 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Provable Approach for End-to-End Safe Reinforcement Learning
May 28, 2025A longstanding goal in safe reinforcement learning (RL) is a method to ensure the safety of a policy throughout the entire process, from learning to operation. However, existing safe RL paradigms inherently struggle to achieve this objective. We propose a method, called Provably Lifetime Safe RL (PLS), that integrates offline safe RL with safe policy deployment to address this challenge. Our proposed method learns a policy offline using return-conditioned supervised learning and then deploys the resulting policy while cautiously optimizing a limited set of parameters, known as target returns, using Gaussian processes (GPs). Theoretically, we justify the use of GPs by analyzing the mathematical relationship between target and actual returns. We then prove that PLS finds near-optimal target returns while guaranteeing safety with high probability. Empirically, we demonstrate that PLS outperforms baselines both in safety and reward performance, thereby achieving the longstanding goal to obtain high rewards while ensuring the safety of a policy throughout the lifetime from learning to operation.
Vulnerability Mitigation for Safety-Aligned Language Models via Debiasing
Feb 04, 2025Safety alignment is an essential research topic for real-world AI applications. Despite the multifaceted nature of safety and trustworthiness in AI, current safety alignment methods often focus on a comprehensive notion of safety. By carefully assessing models from the existing safety-alignment methods, we found that, while they generally improved overall safety performance, they failed to ensure safety in specific categories. Our study first identified the difficulty of eliminating such vulnerabilities without sacrificing the model's helpfulness. We observed that, while smaller KL penalty parameters, increased training iterations, and dataset cleansing can enhance safety, they do not necessarily improve the trade-off between safety and helpfulness. We discovered that safety alignment could even induce undesired effects and result in a model that prefers generating negative tokens leading to rejective responses, regardless of the input context. To address this, we introduced a learning-free method, Token-level Safety-Debiased Inference (TSDI), to estimate and correct this bias during the generation process using randomly constructed prompts. Our experiments demonstrated that our method could enhance the model's helpfulness while maintaining safety, thus improving the trade-off Pareto-front.
Stepwise Alignment for Constrained Language Model Policy Optimization
Apr 17, 2024Safety and trustworthiness are indispensable requirements for applying AI systems based on large language models (LLMs) in real-world applications. This paper formulates a human value alignment as a language model policy optimization problem to maximize reward under a safety constraint and then proposes an algorithm called Stepwise Alignment for Constrained Policy Optimization (SACPO). A key idea behind SACPO, supported by theory, is that the optimal policy incorporating both reward and safety can be directly obtained from a reward-aligned policy. Based on this key idea, SACPO aligns the LLMs with each metric step-wise while leveraging simple yet powerful alignment algorithms such as direct preference optimization (DPO). SACPO provides many benefits such as simplicity, stability, computational efficiency, and flexibility regarding algorithms and dataset selection. Under mild assumption, our theoretical analysis provides the upper bounds regarding near-optimality and safety constraint violation. Our experimental results show that SACPO can fine-tune Alpaca-7B better than the state-of-the-art method in terms of both helpfulness and harmlessness
Few-Shot Image-to-Semantics Translation for Policy Transfer in Reinforcement Learning
Jan 31, 2023We investigate policy transfer using image-to-semantics translation to mitigate learning difficulties in vision-based robotics control agents. This problem assumes two environments: a simulator environment with semantics, that is, low-dimensional and essential information, as the state space, and a real-world environment with images as the state space. By learning mapping from images to semantics, we can transfer a policy, pre-trained in the simulator, to the real world, thereby eliminating real-world on-policy agent interactions to learn, which are costly and risky. In addition, using image-to-semantics mapping is advantageous in terms of the computational efficiency to train the policy and the interpretability of the obtained policy over other types of sim-to-real transfer strategies. To tackle the main difficulty in learning image-to-semantics mapping, namely the human annotation cost for producing a training dataset, we propose two techniques: pair augmentation with the transition function in the simulator environment and active learning. We observed a reduction in the annotation cost without a decline in the performance of the transfer, and the proposed approach outperformed the existing approach without annotation.
Max-Min Off-Policy Actor-Critic Method Focusing on Worst-Case Robustness to Model Misspecification
Nov 07, 2022In the field of reinforcement learning, because of the high cost and risk of policy training in the real world, policies are trained in a simulation environment and transferred to the corresponding real-world environment. However, the simulation environment does not perfectly mimic the real-world environment, lead to model misspecification. Multiple studies report significant deterioration of policy performance in a real-world environment. In this study, we focus on scenarios involving a simulation environment with uncertainty parameters and the set of their possible values, called the uncertainty parameter set. The aim is to optimize the worst-case performance on the uncertainty parameter set to guarantee the performance in the corresponding real-world environment. To obtain a policy for the optimization, we propose an off-policy actor-critic approach called the Max-Min Twin Delayed Deep Deterministic Policy Gradient algorithm (M2TD3), which solves a max-min optimization problem using a simultaneous gradient ascent descent approach. Experiments in multi-joint dynamics with contact (MuJoCo) environments show that the proposed method exhibited a worst-case performance superior to several baseline approaches.
AdvantageNAS: Efficient Neural Architecture Search with Credit Assignment
Dec 11, 2020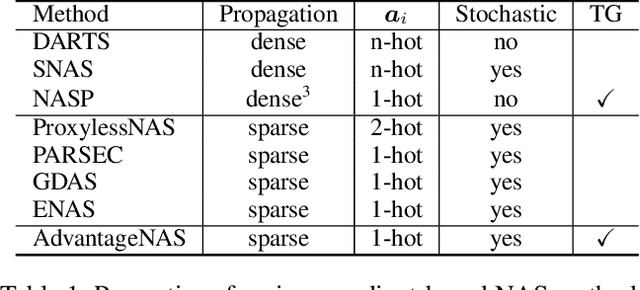
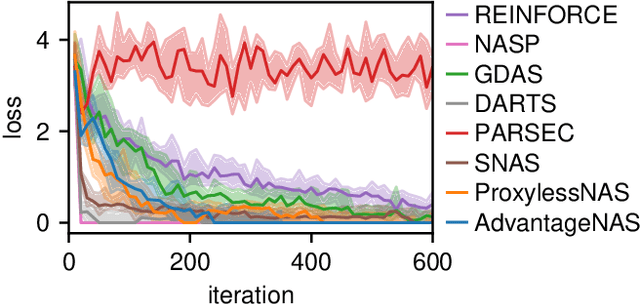
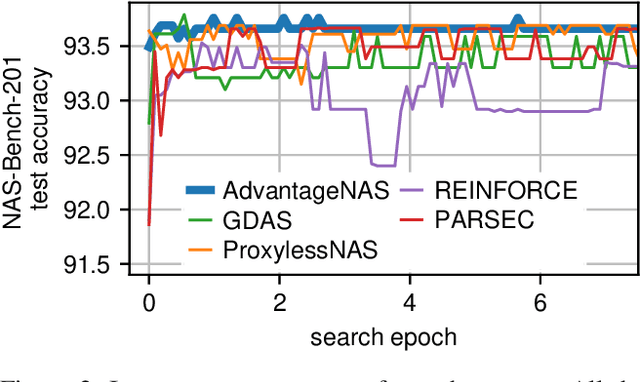

Neural architecture search (NAS) is an approach for automatically designing a neural network architecture without human effort or expert knowledge. However, the high computational cost of NAS limits its use in commercial applications. Two recent NAS paradigms, namely one-shot and sparse propagation, which reduce the time and space complexities, respectively, provide clues for solving this problem. In this paper, we propose a novel search strategy for one-shot and sparse propagation NAS, namely AdvantageNAS, which further reduces the time complexity of NAS by reducing the number of search iterations. AdvantageNAS is a gradient-based approach that improves the search efficiency by introducing credit assignment in gradient estimation for architecture updates. Experiments on the NAS-Bench-201 and PTB dataset show that AdvantageNAS discovers an architecture with higher performance under a limited time budget compared to existing sparse propagation NAS. To further reveal the reliabilities of AdvantageNAS, we investigate it theoretically and find that it monotonically improves the expected loss and thus converges.