 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Neural Reward Models Learn Features for Policy Optimization: A Single-Index Analysis
May 23, 2026Reward modeling is not only a prediction problem: in KL-regularized policy optimization, the learned reward is exponentiated to define the deployed policy, so downstream value depends on errors in reward-tilted regions. We study this feedback in a Gaussian single-index model with $r^*(x) = σ^*(\langle θ^*, x\rangle)$ and $x \sim N(0, I_d)$. We analyze a two-stage neural reward model that first learns the hidden direction $θ^*$ from reward-weighted samples and then fits the readout layer by weighted ridge regression. Exponential reward weighting changes the Hermite signal available to the first layer; for any feature-learning temperature $β_1$ above a dimension-free $O(1)$ threshold, a constant fraction of neurons recover the hidden direction, with weak-recovery complexity governed by the generative exponent. After feature recovery, we derive tilted-policy value-gap bounds for an idealized label-weighted fit with weights $e^{y/β_2}$ and a more practical surrogate-weighted fit with weights $e^{r_{a_0}(x)/β_2}$. Keeping the $β_2$-dependence explicit yields an admissible set of deployment temperatures, balancing the gain from lowering $β_2$ against the learning cost amplified by exponential weighting; in the surrogate-weighted case, proxy-dependent factors shrink this admissible set.
Inference-Aware Meta-Alignment of LLMs via Non-Linear GRPO
Feb 02, 2026Aligning large language models (LLMs) to diverse human preferences is fundamentally challenging since criteria can often conflict with each other. Inference-time alignment methods have recently gained popularity as they allow LLMs to be aligned to multiple criteria via different alignment algorithms at inference time. However, inference-time alignment is computationally expensive since it often requires multiple forward passes of the base model. In this work, we propose inference-aware meta-alignment (IAMA), a novel approach that enables LLMs to be aligned to multiple criteria with limited computational budget at inference time. IAMA trains a base model such that it can be effectively aligned to multiple tasks via different inference-time alignment algorithms. To solve the non-linear optimization problems involved in IAMA, we propose non-linear GRPO, which provably converges to the optimal solution in the space of probability measures.
Wafer Defect Root Cause Analysis with Partial Trajectory Regression
Jul 27, 2025



Identifying upstream processes responsible for wafer defects is challenging due to the combinatorial nature of process flows and the inherent variability in processing routes, which arises from factors such as rework operations and random process waiting times. This paper presents a novel framework for wafer defect root cause analysis, called Partial Trajectory Regression (PTR). The proposed framework is carefully designed to address the limitations of conventional vector-based regression models, particularly in handling variable-length processing routes that span a large number of heterogeneous physical processes. To compute the attribution score of each process given a detected high defect density on a specific wafer, we propose a new algorithm that compares two counterfactual outcomes derived from partial process trajectories. This is enabled by new representation learning methods, proc2vec and route2vec. We demonstrate the effectiveness of the proposed framework using real wafer history data from the NY CREATES fab in Albany.
Sequence-Aware Inline Measurement Attribution for Good-Bad Wafer Diagnosis
Jul 27, 2025How can we identify problematic upstream processes when a certain type of wafer defect starts appearing at a quality checkpoint? Given the complexity of modern semiconductor manufacturing, which involves thousands of process steps, cross-process root cause analysis for wafer defects has been considered highly challenging. This paper proposes a novel framework called Trajectory Shapley Attribution (TSA), an extension of Shapley values (SV), a widely used attribution algorithm in explainable artificial intelligence research. TSA overcomes key limitations of standard SV, including its disregard for the sequential nature of manufacturing processes and its reliance on an arbitrarily chosen reference point. We applied TSA to a good-bad wafer diagnosis task in experimental front-end-of-line processes at the NY CREATES Albany NanoTech fab, aiming to identify measurement items (serving as proxies for process parameters) most relevant to abnormal defect occurrence.
Path Learning with Trajectory Advantage Regression
Jun 24, 2025In this paper, we propose trajectory advantage regression, a method of offline path learning and path attribution based on reinforcement learning. The proposed method can be used to solve path optimization problems while algorithmically only solving a regression problem.
A Provable Approach for End-to-End Safe Reinforcement Learning
May 28, 2025A longstanding goal in safe reinforcement learning (RL) is a method to ensure the safety of a policy throughout the entire process, from learning to operation. However, existing safe RL paradigms inherently struggle to achieve this objective. We propose a method, called Provably Lifetime Safe RL (PLS), that integrates offline safe RL with safe policy deployment to address this challenge. Our proposed method learns a policy offline using return-conditioned supervised learning and then deploys the resulting policy while cautiously optimizing a limited set of parameters, known as target returns, using Gaussian processes (GPs). Theoretically, we justify the use of GPs by analyzing the mathematical relationship between target and actual returns. We then prove that PLS finds near-optimal target returns while guaranteeing safety with high probability. Empirically, we demonstrate that PLS outperforms baselines both in safety and reward performance, thereby achieving the longstanding goal to obtain high rewards while ensuring the safety of a policy throughout the lifetime from learning to operation.
Cumulative Stay-time Representation for Electronic Health Records in Medical Event Time Prediction
May 02, 2022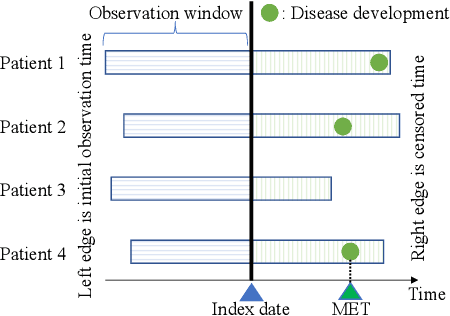
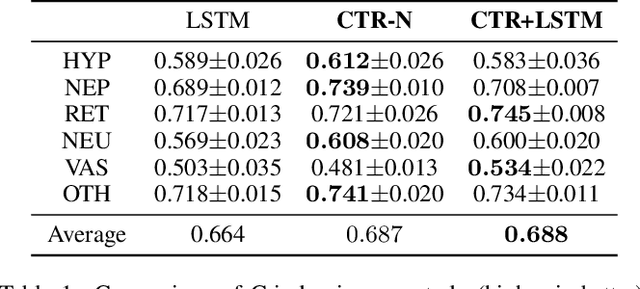
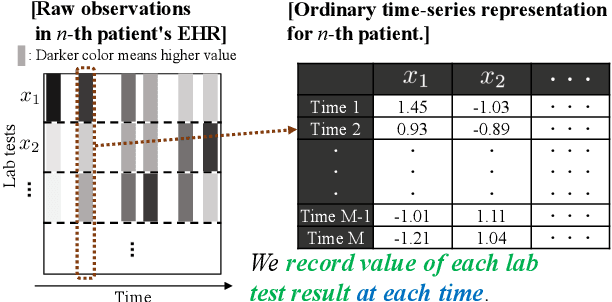

We address the problem of predicting when a disease will develop, i.e., medical event time (MET), from a patient's electronic health record (EHR). The MET of non-communicable diseases like diabetes is highly correlated to cumulative health conditions, more specifically, how much time the patient spent with specific health conditions in the past. The common time-series representation is indirect in extracting such information from EHR because it focuses on detailed dependencies between values in successive observations, not cumulative information. We propose a novel data representation for EHR called cumulative stay-time representation (CTR), which directly models such cumulative health conditions. We derive a trainable construction of CTR based on neural networks that has the flexibility to fit the target data and scalability to handle high-dimensional EHR. Numerical experiments using synthetic and real-world datasets demonstrate that CTR alone achieves a high prediction performance, and it enhances the performance of existing models when combined with them.
Biases in In Silico Evaluation of Molecular Optimization Methods and Bias-Reduced Evaluation Methodology
Jan 28, 2022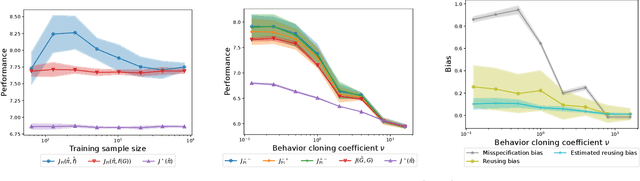
We are interested in in silico evaluation methodology for molecular optimization methods. Given a sample of molecules and their properties of our interest, we wish not only to train an agent that can find molecules optimized with respect to the target property but also to evaluate its performance. A common practice is to train a predictor of the target property on the sample and use it for both training and evaluating the agent. We show that this evaluator potentially suffers from two biases; one is due to misspecification of the predictor and the other to reusing the same sample for training and evaluation. We discuss bias reduction methods for each of the biases comprehensively, and empirically investigate their effectiveness.
A Theoretical Framework of Almost Hyperparameter-free Hyperparameter Selection Methods for Offline Policy Evaluation
Jan 07, 2022

We are concerned with the problem of hyperparameter selection of offline policy evaluation (OPE). OPE is a key component of offline reinforcement learning, which is a core technology for data-driven decision optimization without environment simulators. However, the current state-of-the-art OPE methods are not hyperparameter-free, which undermines their utility in real-life applications. We address this issue by introducing a new approximate hyperparameter selection (AHS) framework for OPE, which defines a notion of optimality (called selection criteria) in a quantitative and interpretable manner without hyperparameters. We then derive four AHS methods each of which has different characteristics such as convergence rate and time complexity. Finally, we verify effectiveness and limitation of these methods with a preliminary experiment.
PAC-Bayesian Transportation Bound
May 31, 2019We present a new generalization error bound, the \emph{PAC-Bayesian transportation bound}, unifying the PAC-Bayesian analysis and the generic chaining method in view of the optimal transportation. The proposed bound is the first PAC-Bayesian framework that characterizes the cost of de-randomization of stochastic predictors facing any Lipschitz loss functions. As an example, we give an upper bound on the de-randomization cost of spectrally normalized neural networks~(NNs) to evaluate how much randomness contributes to the generalization of NNs.