 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing the Power of Vicinity-Informed Analysis for Classification under Covariate Shift
May 27, 2024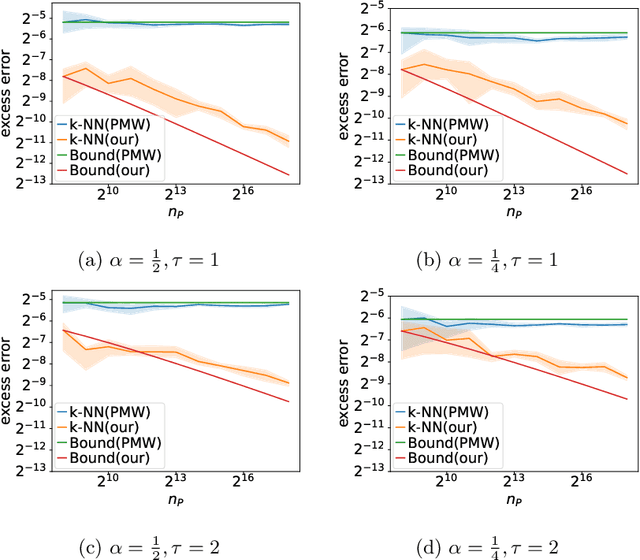
Transfer learning enhances prediction accuracy on a target distribution by leveraging data from a source distribution, demonstrating significant benefits in various applications. This paper introduces a novel dissimilarity measure that utilizes vicinity information, i.e., the local structure of data points, to analyze the excess error in classification under covariate shift, a transfer learning setting where marginal feature distributions differ but conditional label distributions remain the same. We characterize the excess error using the proposed measure and demonstrate faster or competitive convergence rates compared to previous techniques. Notably, our approach is effective in situations where the non-absolute continuousness assumption, which often appears in real-world applications, holds. Our theoretical analysis bridges the gap between current theoretical findings and empirical observations in transfer learning, particularly in scenarios with significant differences between source and target distributions.
Policy Iteration for Pareto-Optimal Policies in Stochastic Stackelberg Games
May 07, 2024In general-sum stochastic games, a stationary Stackelberg equilibrium (SSE) does not always exist, in which the leader maximizes leader's return for all the initial states when the follower takes the best response against the leader's policy. Existing methods of determining the SSEs require strong assumptions to guarantee the convergence and the coincidence of the limit with the SSE. Moreover, our analysis suggests that the performance at the fixed points of these methods is not reasonable when they are not SSEs. Herein, we introduced the concept of Pareto-optimality as a reasonable alternative to SSEs. We derive the policy improvement theorem for stochastic games with the best-response follower and propose an iterative algorithm to determine the Pareto-optimal policies based on it. Monotone improvement and convergence of the proposed approach are proved, and its convergence to SSEs is proved in a special case.
Stepwise Alignment for Constrained Language Model Policy Optimization
Apr 17, 2024Safety and trustworthiness are indispensable requirements for applying AI systems based on large language models (LLMs) in real-world applications. This paper formulates a human value alignment as a language model policy optimization problem to maximize reward under a safety constraint and then proposes an algorithm called Stepwise Alignment for Constrained Policy Optimization (SACPO). A key idea behind SACPO, supported by theory, is that the optimal policy incorporating both reward and safety can be directly obtained from a reward-aligned policy. Based on this key idea, SACPO aligns the LLMs with each metric step-wise while leveraging simple yet powerful alignment algorithms such as direct preference optimization (DPO). SACPO provides many benefits such as simplicity, stability, computational efficiency, and flexibility regarding algorithms and dataset selection. Under mild assumption, our theoretical analysis provides the upper bounds regarding near-optimality and safety constraint violation. Our experimental results show that SACPO can fine-tune Alpaca-7B better than the state-of-the-art method in terms of both helpfulness and harmlessness