 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRead or Ignore? A Unified Benchmark for Typographic-Attack Robustness and Text Recognition in Vision-Language Models
Dec 10, 2025Large vision-language models (LVLMs) are vulnerable to typographic attacks, where misleading text within an image overrides visual understanding. Existing evaluation protocols and defenses, largely focused on object recognition, implicitly encourage ignoring text to achieve robustness; however, real-world scenarios often require joint reasoning over both objects and text (e.g., recognizing pedestrians while reading traffic signs). To address this, we introduce a novel task, Read-or-Ignore VQA (RIO-VQA), which formalizes selective text use in visual question answering (VQA): models must decide, from context, when to read text and when to ignore it. For evaluation, we present the Read-or-Ignore Benchmark (RIO-Bench), a standardized dataset and protocol that, for each real image, provides same-scene counterfactuals (read / ignore) by varying only the textual content and question type. Using RIO-Bench, we show that strong LVLMs and existing defenses fail to balance typographic robustness and text-reading capability, highlighting the need for improved approaches. Finally, RIO-Bench enables a novel data-driven defense that learns adaptive selective text use, moving beyond prior non-adaptive, text-ignoring defenses. Overall, this work reveals a fundamental misalignment between the existing evaluation scope and real-world requirements, providing a principled path toward reliable LVLMs. Our Project Page is at https://turingmotors.github.io/rio-vqa/.
Toward Safer Diffusion Language Models: Discovery and Mitigation of Priming Vulnerability
Oct 01, 2025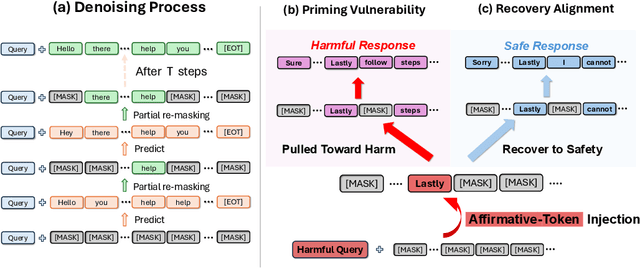

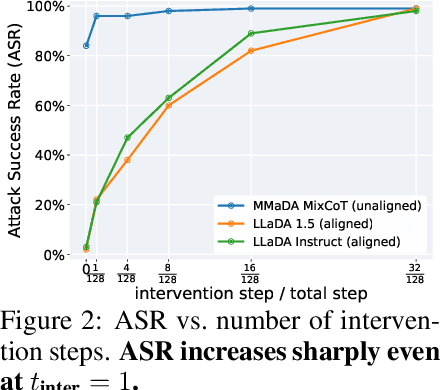
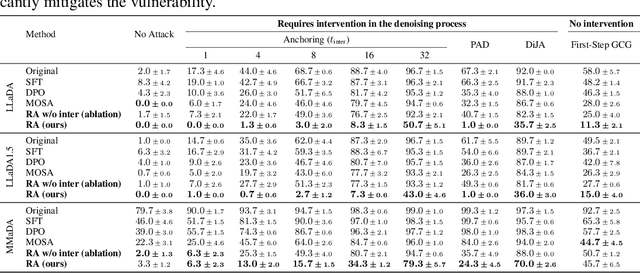
Diffusion language models (DLMs) generate tokens in parallel through iterative denoising, which can reduce latency and enable bidirectional conditioning. However, the safety risks posed by jailbreak attacks that exploit this inference mechanism are not well understood. In this paper, we reveal that DLMs have a critical vulnerability stemming from their iterative denoising process and propose a countermeasure. Specifically, our investigation shows that if an affirmative token for a harmful query appears at an intermediate step, subsequent denoising can be steered toward a harmful response even in aligned models. As a result, simply injecting such affirmative tokens can readily bypass the safety guardrails. Furthermore, we demonstrate that the vulnerability allows existing optimization-based jailbreak attacks to succeed on DLMs. Building on this analysis, we propose a novel safety alignment method tailored to DLMs that trains models to generate safe responses from contaminated intermediate states that contain affirmative tokens. Our experiments indicate that the proposed method significantly mitigates the vulnerability with minimal impact on task performance. Furthermore, our method improves robustness against conventional jailbreak attacks. Our work underscores the need for DLM-specific safety research.
Understanding Sensitivity of Differential Attention through the Lens of Adversarial Robustness
Oct 01, 2025Differential Attention (DA) has been proposed as a refinement to standard attention, suppressing redundant or noisy context through a subtractive structure and thereby reducing contextual hallucination. While this design sharpens task-relevant focus, we show that it also introduces a structural fragility under adversarial perturbations. Our theoretical analysis identifies negative gradient alignment-a configuration encouraged by DA's subtraction-as the key driver of sensitivity amplification, leading to increased gradient norms and elevated local Lipschitz constants. We empirically validate this Fragile Principle through systematic experiments on ViT/DiffViT and evaluations of pretrained CLIP/DiffCLIP, spanning five datasets in total. These results demonstrate higher attack success rates, frequent gradient opposition, and stronger local sensitivity compared to standard attention. Furthermore, depth-dependent experiments reveal a robustness crossover: stacking DA layers attenuates small perturbations via depth-dependent noise cancellation, though this protection fades under larger attack budgets. Overall, our findings uncover a fundamental trade-off: DA improves discriminative focus on clean inputs but increases adversarial vulnerability, underscoring the need to jointly design for selectivity and robustness in future attention mechanisms.
MergePrint: Robust Fingerprinting against Merging Large Language Models
Oct 11, 2024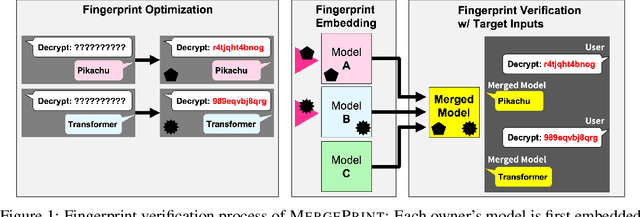
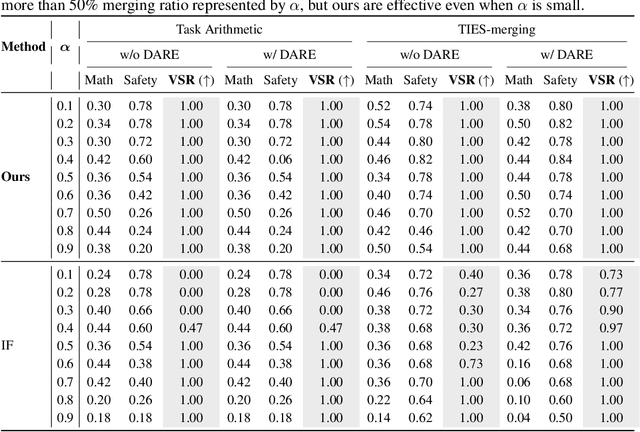
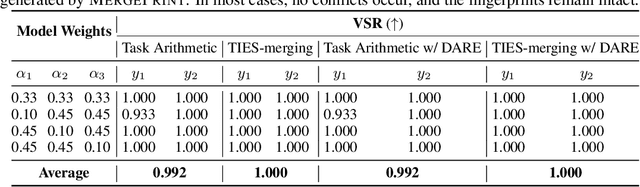
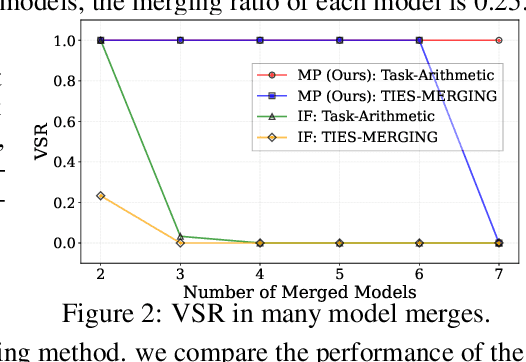
As the cost of training large language models (LLMs) rises, protecting their intellectual property has become increasingly critical. Model merging, which integrates multiple expert models into a single model capable of performing multiple tasks, presents a growing risk of unauthorized and malicious usage. While fingerprinting techniques have been studied for asserting model ownership, existing methods have primarily focused on fine-tuning, leaving model merging underexplored. To address this gap, we propose a novel fingerprinting method MergePrint that embeds robust fingerprints designed to preserve ownership claims even after model merging. By optimizing against a pseudo-merged model, which simulates post-merged model weights, MergePrint generates fingerprints that remain detectable after merging. Additionally, we optimize the fingerprint inputs to minimize performance degradation, enabling verification through specific outputs from targeted inputs. This approach provides a practical fingerprinting strategy for asserting ownership in cases of misappropriation through model merging.
Behavior-Targeted Attack on Reinforcement Learning with Limited Access to Victim's Policy
Jun 06, 2024This study considers the attack on reinforcement learning agents where the adversary aims to control the victim's behavior as specified by the adversary by adding adversarial modifications to the victim's state observation. While some attack methods reported success in manipulating the victim agent's behavior, these methods often rely on environment-specific heuristics. In addition, all existing attack methods require white-box access to the victim's policy. In this study, we propose a novel method for manipulating the victim agent in the black-box (i.e., the adversary is allowed to observe the victim's state and action only) and no-box (i.e., the adversary is allowed to observe the victim's state only) setting without requiring environment-specific heuristics. Our attack method is formulated as a bi-level optimization problem that is reduced to a distribution matching problem and can be solved by an existing imitation learning algorithm in the black-box and no-box settings. Empirical evaluations on several reinforcement learning benchmarks show that our proposed method has superior attack performance to baselines.