 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRead or Ignore? A Unified Benchmark for Typographic-Attack Robustness and Text Recognition in Vision-Language Models
Dec 10, 2025Large vision-language models (LVLMs) are vulnerable to typographic attacks, where misleading text within an image overrides visual understanding. Existing evaluation protocols and defenses, largely focused on object recognition, implicitly encourage ignoring text to achieve robustness; however, real-world scenarios often require joint reasoning over both objects and text (e.g., recognizing pedestrians while reading traffic signs). To address this, we introduce a novel task, Read-or-Ignore VQA (RIO-VQA), which formalizes selective text use in visual question answering (VQA): models must decide, from context, when to read text and when to ignore it. For evaluation, we present the Read-or-Ignore Benchmark (RIO-Bench), a standardized dataset and protocol that, for each real image, provides same-scene counterfactuals (read / ignore) by varying only the textual content and question type. Using RIO-Bench, we show that strong LVLMs and existing defenses fail to balance typographic robustness and text-reading capability, highlighting the need for improved approaches. Finally, RIO-Bench enables a novel data-driven defense that learns adaptive selective text use, moving beyond prior non-adaptive, text-ignoring defenses. Overall, this work reveals a fundamental misalignment between the existing evaluation scope and real-world requirements, providing a principled path toward reliable LVLMs. Our Project Page is at https://turingmotors.github.io/rio-vqa/.
Understanding Sensitivity of Differential Attention through the Lens of Adversarial Robustness
Oct 01, 2025Differential Attention (DA) has been proposed as a refinement to standard attention, suppressing redundant or noisy context through a subtractive structure and thereby reducing contextual hallucination. While this design sharpens task-relevant focus, we show that it also introduces a structural fragility under adversarial perturbations. Our theoretical analysis identifies negative gradient alignment-a configuration encouraged by DA's subtraction-as the key driver of sensitivity amplification, leading to increased gradient norms and elevated local Lipschitz constants. We empirically validate this Fragile Principle through systematic experiments on ViT/DiffViT and evaluations of pretrained CLIP/DiffCLIP, spanning five datasets in total. These results demonstrate higher attack success rates, frequent gradient opposition, and stronger local sensitivity compared to standard attention. Furthermore, depth-dependent experiments reveal a robustness crossover: stacking DA layers attenuates small perturbations via depth-dependent noise cancellation, though this protection fades under larger attack budgets. Overall, our findings uncover a fundamental trade-off: DA improves discriminative focus on clean inputs but increases adversarial vulnerability, underscoring the need to jointly design for selectivity and robustness in future attention mechanisms.
MergePrint: Robust Fingerprinting against Merging Large Language Models
Oct 11, 2024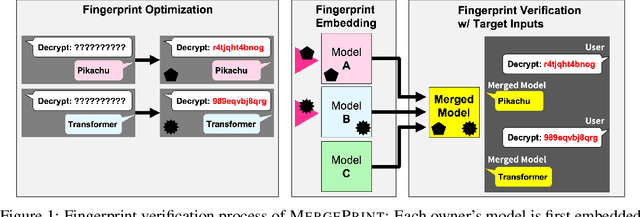
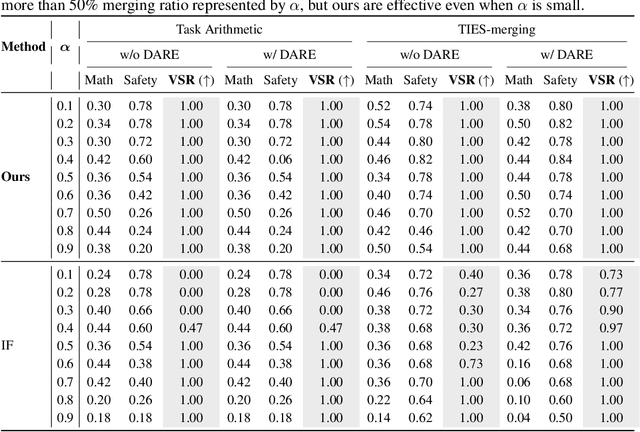
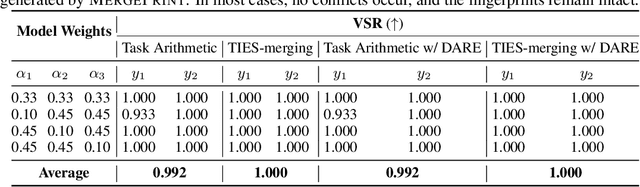
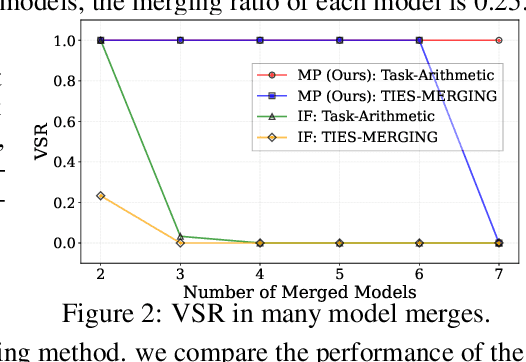
As the cost of training large language models (LLMs) rises, protecting their intellectual property has become increasingly critical. Model merging, which integrates multiple expert models into a single model capable of performing multiple tasks, presents a growing risk of unauthorized and malicious usage. While fingerprinting techniques have been studied for asserting model ownership, existing methods have primarily focused on fine-tuning, leaving model merging underexplored. To address this gap, we propose a novel fingerprinting method MergePrint that embeds robust fingerprints designed to preserve ownership claims even after model merging. By optimizing against a pseudo-merged model, which simulates post-merged model weights, MergePrint generates fingerprints that remain detectable after merging. Additionally, we optimize the fingerprint inputs to minimize performance degradation, enabling verification through specific outputs from targeted inputs. This approach provides a practical fingerprinting strategy for asserting ownership in cases of misappropriation through model merging.
Leveraging Many-To-Many Relationships for Defending Against Visual-Language Adversarial Attacks
May 29, 2024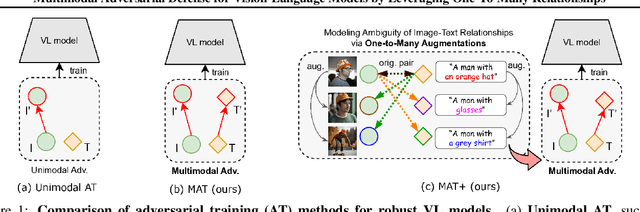
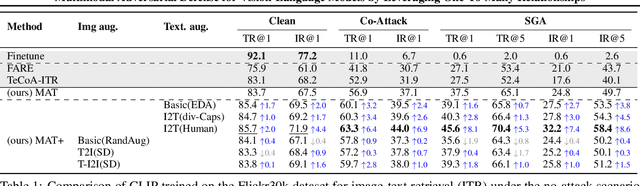
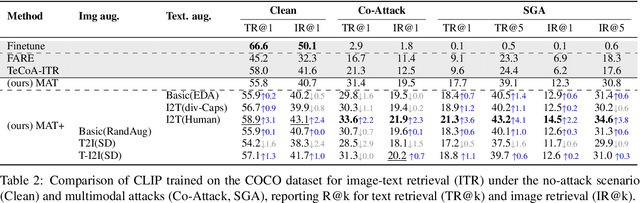
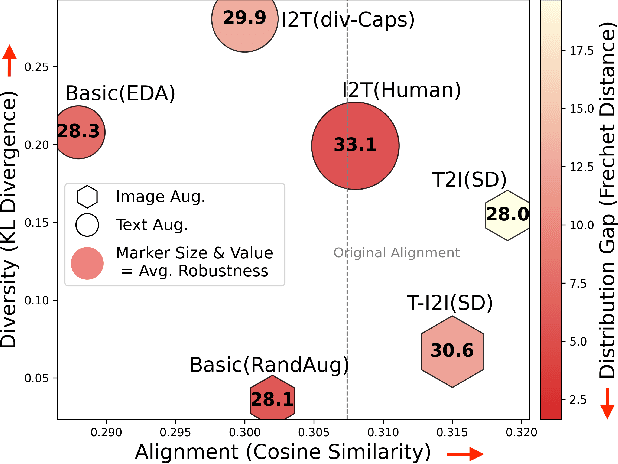
Recent studies have revealed that vision-language (VL) models are vulnerable to adversarial attacks for image-text retrieval (ITR). However, existing defense strategies for VL models primarily focus on zero-shot image classification, which do not consider the simultaneous manipulation of image and text, as well as the inherent many-to-many (N:N) nature of ITR, where a single image can be described in numerous ways, and vice versa. To this end, this paper studies defense strategies against adversarial attacks on VL models for ITR for the first time. Particularly, we focus on how to leverage the N:N relationship in ITR to enhance adversarial robustness. We found that, although adversarial training easily overfits to specific one-to-one (1:1) image-text pairs in the train data, diverse augmentation techniques to create one-to-many (1:N) / many-to-one (N:1) image-text pairs can significantly improve adversarial robustness in VL models. Additionally, we show that the alignment of the augmented image-text pairs is crucial for the effectiveness of the defense strategy, and that inappropriate augmentations can even degrade the model's performance. Based on these findings, we propose a novel defense strategy that leverages the N:N relationship in ITR, which effectively generates diverse yet highly-aligned N:N pairs using basic augmentations and generative model-based augmentations. This work provides a novel perspective on defending against adversarial attacks in VL tasks and opens up new research directions for future work.
Rethinking Invariance Regularization in Adversarial Training to Improve Robustness-Accuracy Trade-off
Feb 22, 2024Although adversarial training has been the state-of-the-art approach to defend against adversarial examples (AEs), they suffer from a robustness-accuracy trade-off. In this work, we revisit representation-based invariance regularization to learn discriminative yet adversarially invariant representations, aiming to mitigate this trade-off. We empirically identify two key issues hindering invariance regularization: (1) a "gradient conflict" between invariance loss and classification objectives, indicating the existence of "collapsing solutions," and (2) the mixture distribution problem arising from diverged distributions of clean and adversarial inputs. To address these issues, we propose Asymmetrically Representation-regularized Adversarial Training (AR-AT), which incorporates a stop-gradient operation and a pre-dictor in the invariance loss to avoid "collapsing solutions," inspired by a recent non-contrastive self-supervised learning approach, and a split-BatchNorm (BN) structure to resolve the mixture distribution problem. Our method significantly improves the robustness-accuracy trade-off by learning adversarially invariant representations without sacrificing discriminative power. Furthermore, we discuss the relevance of our findings to knowledge-distillation-based defense methods, contributing to a deeper understanding of their relative successes.
Defending Against Physical Adversarial Patch Attacks on Infrared Human Detection
Sep 27, 2023

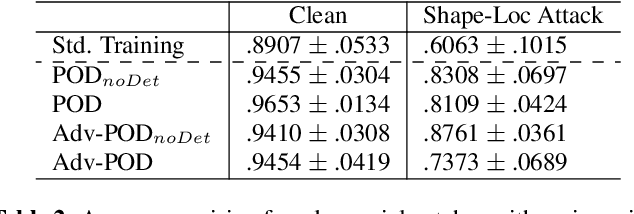

Infrared detection is an emerging technique for safety-critical tasks owing to its remarkable anti-interference capability. However, recent studies have revealed that it is vulnerable to physically-realizable adversarial patches, posing risks in its real-world applications. To address this problem, we are the first to investigate defense strategies against adversarial patch attacks on infrared detection, especially human detection. We have devised a straightforward defense strategy, patch-based occlusion-aware detection (POD), which efficiently augments training samples with random patches and subsequently detects them. POD not only robustly detects people but also identifies adversarial patch locations. Surprisingly, while being extremely computationally efficient, POD easily generalizes to state-of-the-art adversarial patch attacks that are unseen during training. Furthermore, POD improves detection precision even in a clean (i.e., no-patch) situation due to the data augmentation effect. Evaluation demonstrated that POD is robust to adversarial patches of various shapes and sizes. The effectiveness of our baseline approach is shown to be a viable defense mechanism for real-world infrared human detection systems, paving the way for exploring future research directions.
Beyond In-Domain Scenarios: Robust Density-Aware Calibration
Feb 10, 2023



Calibrating deep learning models to yield uncertainty-aware predictions is crucial as deep neural networks get increasingly deployed in safety-critical applications. While existing post-hoc calibration methods achieve impressive results on in-domain test datasets, they are limited by their inability to yield reliable uncertainty estimates in domain-shift and out-of-domain (OOD) scenarios. We aim to bridge this gap by proposing DAC, an accuracy-preserving as well as Density-Aware Calibration method based on k-nearest-neighbors (KNN). In contrast to existing post-hoc methods, we utilize hidden layers of classifiers as a source for uncertainty-related information and study their importance. We show that DAC is a generic method that can readily be combined with state-of-the-art post-hoc methods. DAC boosts the robustness of calibration performance in domain-shift and OOD, while maintaining excellent in-domain predictive uncertainty estimates. We demonstrate that DAC leads to consistently better calibration across a large number of model architectures, datasets, and metrics. Additionally, we show that DAC improves calibration substantially on recent large-scale neural networks pre-trained on vast amounts of data.
Closer Look at the Transferability of Adversarial Examples: How They Fool Different Models Differently
Dec 29, 2021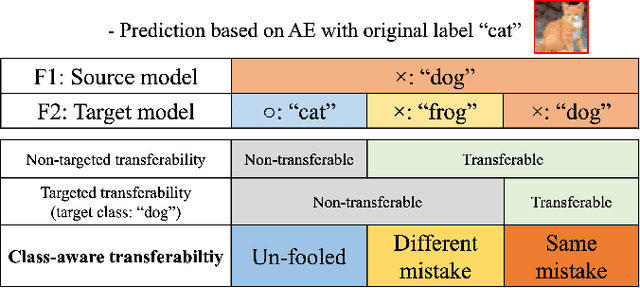
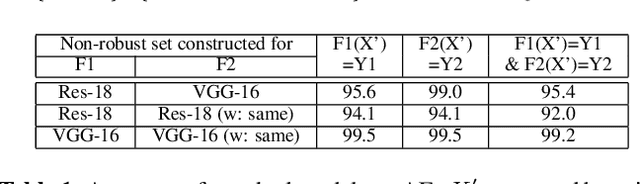
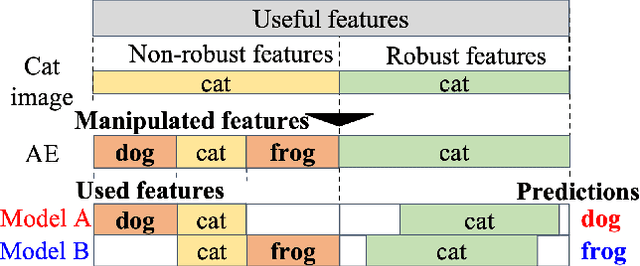
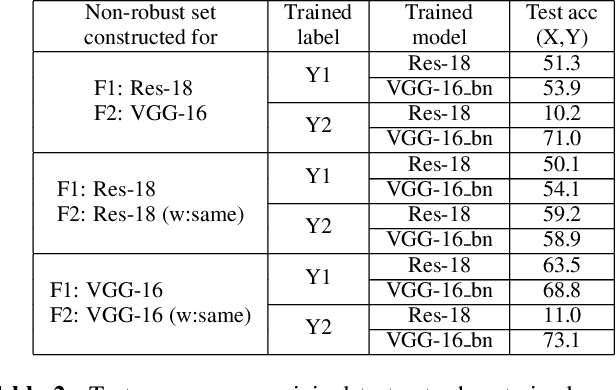
Deep neural networks are vulnerable to adversarial examples (AEs), which have adversarial transferability: AEs generated for the source model can mislead another (target) model's predictions. However, the transferability has not been understood from the perspective of to which class target model's predictions were misled (i.e., class-aware transferability). In this paper, we differentiate the cases in which a target model predicts the same wrong class as the source model ("same mistake") or a different wrong class ("different mistake") to analyze and provide an explanation of the mechanism. First, our analysis shows (1) that same mistakes correlate with "non-targeted transferability" and (2) that different mistakes occur between similar models regardless of the perturbation size. Second, we present evidence that the difference in same and different mistakes can be explained by non-robust features, predictive but human-uninterpretable patterns: different mistakes occur when non-robust features in AEs are used differently by models. Non-robust features can thus provide consistent explanations for the class-aware transferability of AEs.