 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathCal: State-Aware Reflection-Marker Calibration for Efficient Reasoning
May 21, 2026The emergence of Large Reasoning Language Models (LRMs) has paved the way for tackling complex reasoning tasks through test-time scaling by generating long-form Chain-of-Thought (CoT) trajectories during inference. Meanwhile, these trajectories often contain explicit reflection markers such as ``wait'', ``but'', and ``alternatively'', signaling hesitation, revision, and the consideration of alternative explorations, respectively. Recent studies on test-time control leverage such markers as lightweight handles for steering reasoning, typically treating them as a single coarse-grained category rather than distinguishing their distinct functional roles. In this paper, we conduct type-wise suppression and fixed-prefix intervention, revealing that reflection markers differ not only in their functional roles but also in when they exert the greatest influence. Specifically, different marker classes affect accuracy and generation length in distinct ways, and marker choices are most consequential before the model settles into a stable reasoning trajectory. Motivated by these findings, we introduce PathCal, a novel training-free decoding controller that calibrates reasoning paths by distinguishing marker types and intervening only at locally uncertain states. At each decoding step, PathCal utilizes the distribution over reflection-markers to estimate local competition between maintaining the current reasoning trajectory and initiating a competing branch, and softly rebalances marker logits when competing-branch evidence becomes excessive. Experiments across six reasoning benchmarks demonstrate that PathCal achieves a better efficiency--performance trade-off, improving or preserving accuracy while reducing generation length, without relying on external verifiers or additional sampling.
Read or Ignore? A Unified Benchmark for Typographic-Attack Robustness and Text Recognition in Vision-Language Models
Dec 10, 2025Large vision-language models (LVLMs) are vulnerable to typographic attacks, where misleading text within an image overrides visual understanding. Existing evaluation protocols and defenses, largely focused on object recognition, implicitly encourage ignoring text to achieve robustness; however, real-world scenarios often require joint reasoning over both objects and text (e.g., recognizing pedestrians while reading traffic signs). To address this, we introduce a novel task, Read-or-Ignore VQA (RIO-VQA), which formalizes selective text use in visual question answering (VQA): models must decide, from context, when to read text and when to ignore it. For evaluation, we present the Read-or-Ignore Benchmark (RIO-Bench), a standardized dataset and protocol that, for each real image, provides same-scene counterfactuals (read / ignore) by varying only the textual content and question type. Using RIO-Bench, we show that strong LVLMs and existing defenses fail to balance typographic robustness and text-reading capability, highlighting the need for improved approaches. Finally, RIO-Bench enables a novel data-driven defense that learns adaptive selective text use, moving beyond prior non-adaptive, text-ignoring defenses. Overall, this work reveals a fundamental misalignment between the existing evaluation scope and real-world requirements, providing a principled path toward reliable LVLMs. Our Project Page is at https://turingmotors.github.io/rio-vqa/.
Understanding Sensitivity of Differential Attention through the Lens of Adversarial Robustness
Oct 01, 2025Differential Attention (DA) has been proposed as a refinement to standard attention, suppressing redundant or noisy context through a subtractive structure and thereby reducing contextual hallucination. While this design sharpens task-relevant focus, we show that it also introduces a structural fragility under adversarial perturbations. Our theoretical analysis identifies negative gradient alignment-a configuration encouraged by DA's subtraction-as the key driver of sensitivity amplification, leading to increased gradient norms and elevated local Lipschitz constants. We empirically validate this Fragile Principle through systematic experiments on ViT/DiffViT and evaluations of pretrained CLIP/DiffCLIP, spanning five datasets in total. These results demonstrate higher attack success rates, frequent gradient opposition, and stronger local sensitivity compared to standard attention. Furthermore, depth-dependent experiments reveal a robustness crossover: stacking DA layers attenuates small perturbations via depth-dependent noise cancellation, though this protection fades under larger attack budgets. Overall, our findings uncover a fundamental trade-off: DA improves discriminative focus on clean inputs but increases adversarial vulnerability, underscoring the need to jointly design for selectivity and robustness in future attention mechanisms.
STRIDE-QA: Visual Question Answering Dataset for Spatiotemporal Reasoning in Urban Driving Scenes
Aug 14, 2025Vision-Language Models (VLMs) have been applied to autonomous driving to support decision-making in complex real-world scenarios. However, their training on static, web-sourced image-text pairs fundamentally limits the precise spatiotemporal reasoning required to understand and predict dynamic traffic scenes. We address this critical gap with STRIDE-QA, a large-scale visual question answering (VQA) dataset for physically grounded reasoning from an ego-centric perspective. Constructed from 100 hours of multi-sensor driving data in Tokyo, capturing diverse and challenging conditions, STRIDE-QA is the largest VQA dataset for spatiotemporal reasoning in urban driving, offering 16 million QA pairs over 285K frames. Grounded by dense, automatically generated annotations including 3D bounding boxes, segmentation masks, and multi-object tracks, the dataset uniquely supports both object-centric and ego-centric reasoning through three novel QA tasks that require spatial localization and temporal prediction. Our benchmarks demonstrate that existing VLMs struggle significantly, achieving near-zero scores on prediction consistency. In contrast, VLMs fine-tuned on STRIDE-QA exhibit dramatic performance gains, achieving 55% success in spatial localization and 28% consistency in future motion prediction, compared to near-zero scores from general-purpose VLMs. Therefore, STRIDE-QA establishes a comprehensive foundation for developing more reliable VLMs for safety-critical autonomous systems.
One-D-Piece: Image Tokenizer Meets Quality-Controllable Compression
Jan 17, 2025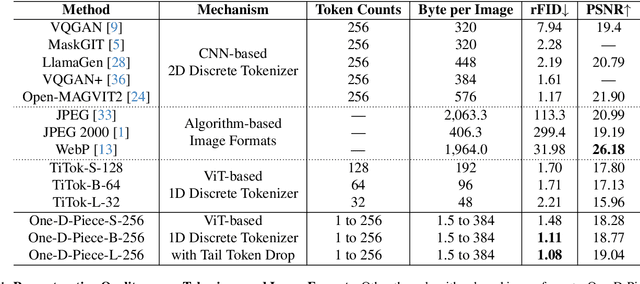

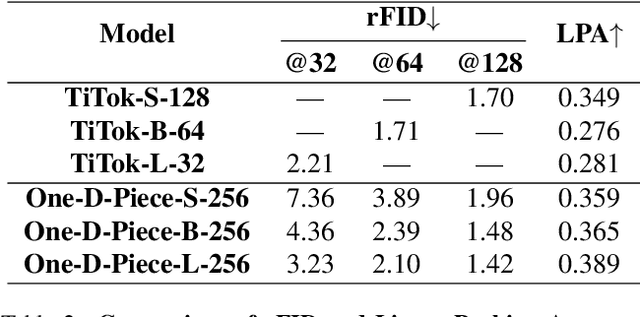
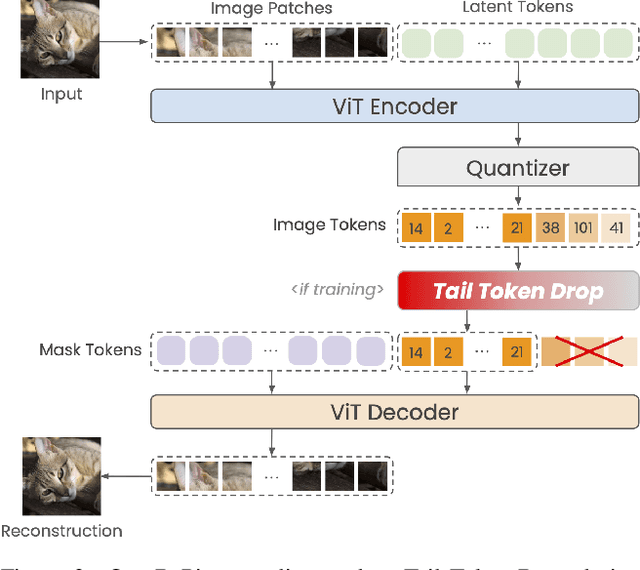
Current image tokenization methods require a large number of tokens to capture the information contained within images. Although the amount of information varies across images, most image tokenizers only support fixed-length tokenization, leading to inefficiency in token allocation. In this study, we introduce One-D-Piece, a discrete image tokenizer designed for variable-length tokenization, achieving quality-controllable mechanism. To enable variable compression rate, we introduce a simple but effective regularization mechanism named "Tail Token Drop" into discrete one-dimensional image tokenizers. This method encourages critical information to concentrate at the head of the token sequence, enabling support of variadic tokenization, while preserving state-of-the-art reconstruction quality. We evaluate our tokenizer across multiple reconstruction quality metrics and find that it delivers significantly better perceptual quality than existing quality-controllable compression methods, including JPEG and WebP, at smaller byte sizes. Furthermore, we assess our tokenizer on various downstream computer vision tasks, including image classification, object detection, semantic segmentation, and depth estimation, confirming its adaptability to numerous applications compared to other variable-rate methods. Our approach demonstrates the versatility of variable-length discrete image tokenization, establishing a new paradigm in both compression efficiency and reconstruction performance. Finally, we validate the effectiveness of tail token drop via detailed analysis of tokenizers.
ACT-Bench: Towards Action Controllable World Models for Autonomous Driving
Dec 06, 2024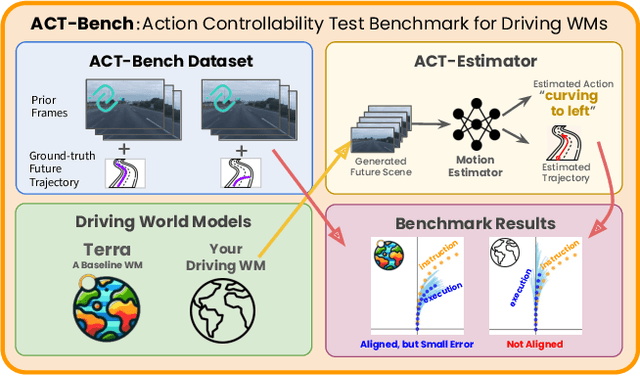



World models have emerged as promising neural simulators for autonomous driving, with the potential to supplement scarce real-world data and enable closed-loop evaluations. However, current research primarily evaluates these models based on visual realism or downstream task performance, with limited focus on fidelity to specific action instructions - a crucial property for generating targeted simulation scenes. Although some studies address action fidelity, their evaluations rely on closed-source mechanisms, limiting reproducibility. To address this gap, we develop an open-access evaluation framework, ACT-Bench, for quantifying action fidelity, along with a baseline world model, Terra. Our benchmarking framework includes a large-scale dataset pairing short context videos from nuScenes with corresponding future trajectory data, which provides conditional input for generating future video frames and enables evaluation of action fidelity for executed motions. Furthermore, Terra is trained on multiple large-scale trajectory-annotated datasets to enhance action fidelity. Leveraging this framework, we demonstrate that the state-of-the-art model does not fully adhere to given instructions, while Terra achieves improved action fidelity. All components of our benchmark framework will be made publicly available to support future research.
Self-Preference Bias in LLM-as-a-Judge
Oct 29, 2024



Automated evaluation leveraging large language models (LLMs), commonly referred to as LLM evaluators or LLM-as-a-judge, has been widely used in measuring the performance of dialogue systems. However, the self-preference bias in LLMs has posed significant risks, including promoting specific styles or policies intrinsic to the LLMs. Despite the importance of this issue, there is a lack of established methods to measure the self-preference bias quantitatively, and its underlying causes are poorly understood. In this paper, we introduce a novel quantitative metric to measure the self-preference bias. Our experimental results demonstrate that GPT-4 exhibits a significant degree of self-preference bias. To explore the causes, we hypothesize that LLMs may favor outputs that are more familiar to them, as indicated by lower perplexity. We analyze the relationship between LLM evaluations and the perplexities of outputs. Our findings reveal that LLMs assign significantly higher evaluations to outputs with lower perplexity than human evaluators, regardless of whether the outputs were self-generated. This suggests that the essence of the bias lies in perplexity and that the self-preference bias exists because LLMs prefer texts more familiar to them.
MergePrint: Robust Fingerprinting against Merging Large Language Models
Oct 11, 2024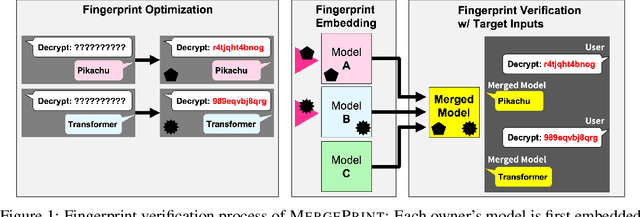
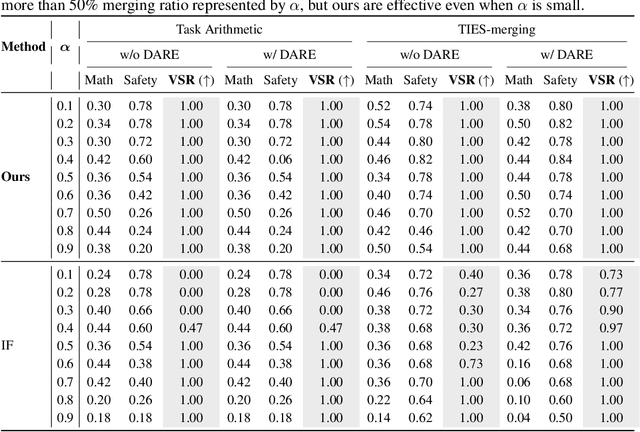
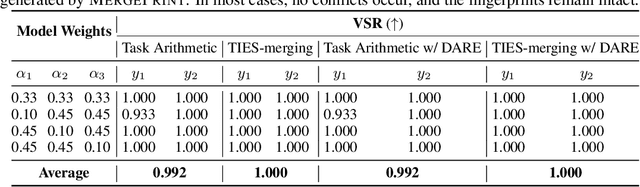
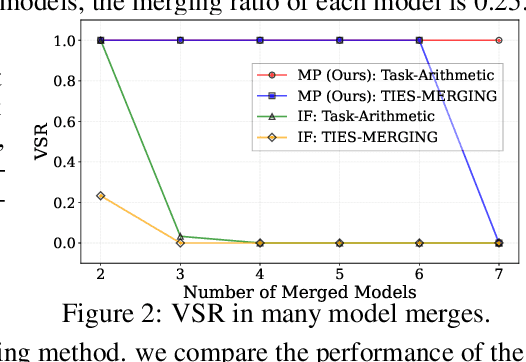
As the cost of training large language models (LLMs) rises, protecting their intellectual property has become increasingly critical. Model merging, which integrates multiple expert models into a single model capable of performing multiple tasks, presents a growing risk of unauthorized and malicious usage. While fingerprinting techniques have been studied for asserting model ownership, existing methods have primarily focused on fine-tuning, leaving model merging underexplored. To address this gap, we propose a novel fingerprinting method MergePrint that embeds robust fingerprints designed to preserve ownership claims even after model merging. By optimizing against a pseudo-merged model, which simulates post-merged model weights, MergePrint generates fingerprints that remain detectable after merging. Additionally, we optimize the fingerprint inputs to minimize performance degradation, enabling verification through specific outputs from targeted inputs. This approach provides a practical fingerprinting strategy for asserting ownership in cases of misappropriation through model merging.
Watermark-embedded Adversarial Examples for Copyright Protection against Diffusion Models
Apr 19, 2024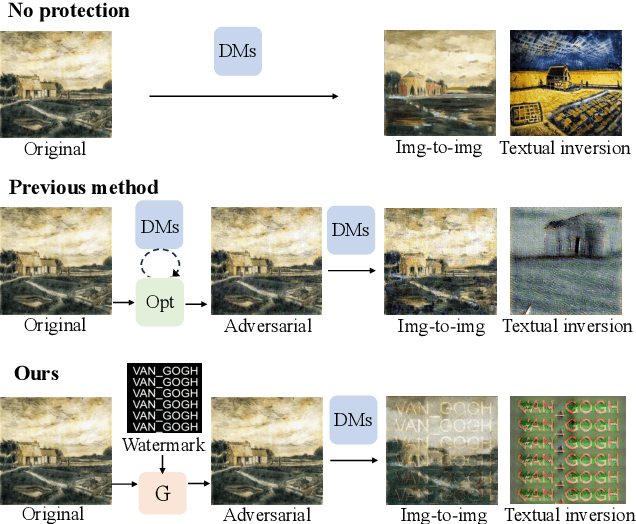
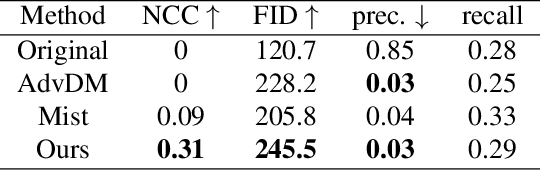
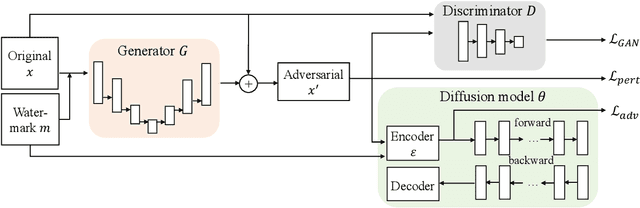

Diffusion Models (DMs) have shown remarkable capabilities in various image-generation tasks. However, there are growing concerns that DMs could be used to imitate unauthorized creations and thus raise copyright issues. To address this issue, we propose a novel framework that embeds personal watermarks in the generation of adversarial examples. Such examples can force DMs to generate images with visible watermarks and prevent DMs from imitating unauthorized images. We construct a generator based on conditional adversarial networks and design three losses (adversarial loss, GAN loss, and perturbation loss) to generate adversarial examples that have subtle perturbation but can effectively attack DMs to prevent copyright violations. Training a generator for a personal watermark by our method only requires 5-10 samples within 2-3 minutes, and once the generator is trained, it can generate adversarial examples with that watermark significantly fast (0.2s per image). We conduct extensive experiments in various conditional image-generation scenarios. Compared to existing methods that generate images with chaotic textures, our method adds visible watermarks on the generated images, which is a more straightforward way to indicate copyright violations. We also observe that our adversarial examples exhibit good transferability across unknown generative models. Therefore, this work provides a simple yet powerful way to protect copyright from DM-based imitation.
Understanding Likelihood of Normalizing Flow and Image Complexity through the Lens of Out-of-Distribution Detection
Feb 16, 2024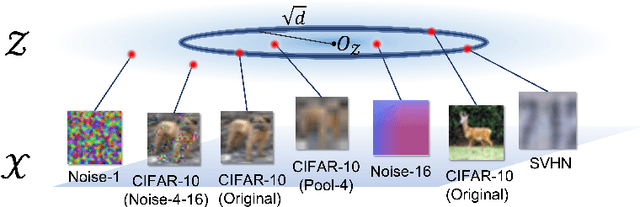
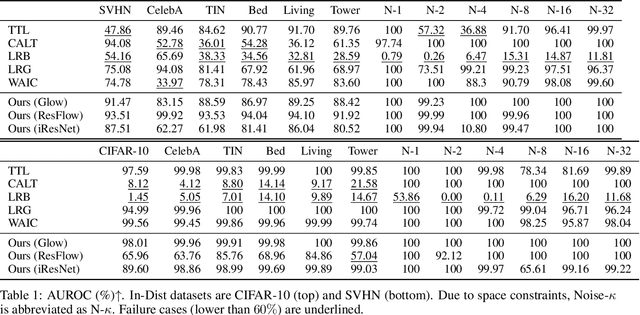

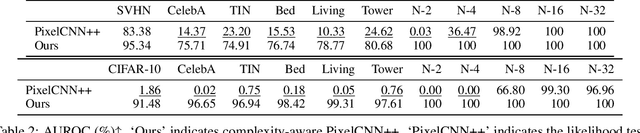
Out-of-distribution (OOD) detection is crucial to safety-critical machine learning applications and has been extensively studied. While recent studies have predominantly focused on classifier-based methods, research on deep generative model (DGM)-based methods have lagged relatively. This disparity may be attributed to a perplexing phenomenon: DGMs often assign higher likelihoods to unknown OOD inputs than to their known training data. This paper focuses on explaining the underlying mechanism of this phenomenon. We propose a hypothesis that less complex images concentrate in high-density regions in the latent space, resulting in a higher likelihood assignment in the Normalizing Flow (NF). We experimentally demonstrate its validity for five NF architectures, concluding that their likelihood is untrustworthy. Additionally, we show that this problem can be alleviated by treating image complexity as an independent variable. Finally, we provide evidence of the potential applicability of our hypothesis in another DGM, PixelCNN++.