 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRIDE-QA: Visual Question Answering Dataset for Spatiotemporal Reasoning in Urban Driving Scenes
Aug 14, 2025Vision-Language Models (VLMs) have been applied to autonomous driving to support decision-making in complex real-world scenarios. However, their training on static, web-sourced image-text pairs fundamentally limits the precise spatiotemporal reasoning required to understand and predict dynamic traffic scenes. We address this critical gap with STRIDE-QA, a large-scale visual question answering (VQA) dataset for physically grounded reasoning from an ego-centric perspective. Constructed from 100 hours of multi-sensor driving data in Tokyo, capturing diverse and challenging conditions, STRIDE-QA is the largest VQA dataset for spatiotemporal reasoning in urban driving, offering 16 million QA pairs over 285K frames. Grounded by dense, automatically generated annotations including 3D bounding boxes, segmentation masks, and multi-object tracks, the dataset uniquely supports both object-centric and ego-centric reasoning through three novel QA tasks that require spatial localization and temporal prediction. Our benchmarks demonstrate that existing VLMs struggle significantly, achieving near-zero scores on prediction consistency. In contrast, VLMs fine-tuned on STRIDE-QA exhibit dramatic performance gains, achieving 55% success in spatial localization and 28% consistency in future motion prediction, compared to near-zero scores from general-purpose VLMs. Therefore, STRIDE-QA establishes a comprehensive foundation for developing more reliable VLMs for safety-critical autonomous systems.
One-D-Piece: Image Tokenizer Meets Quality-Controllable Compression
Jan 17, 2025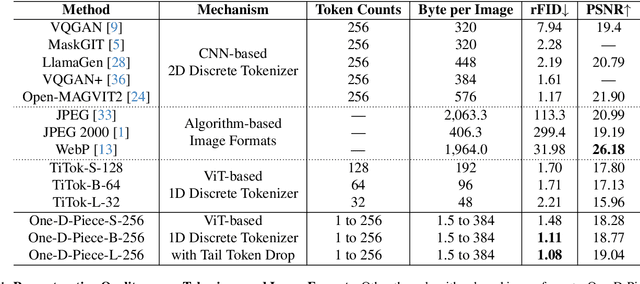

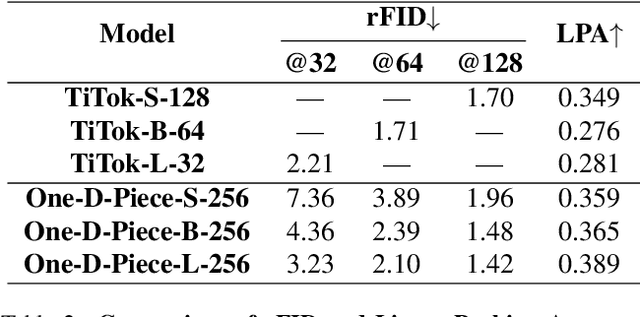
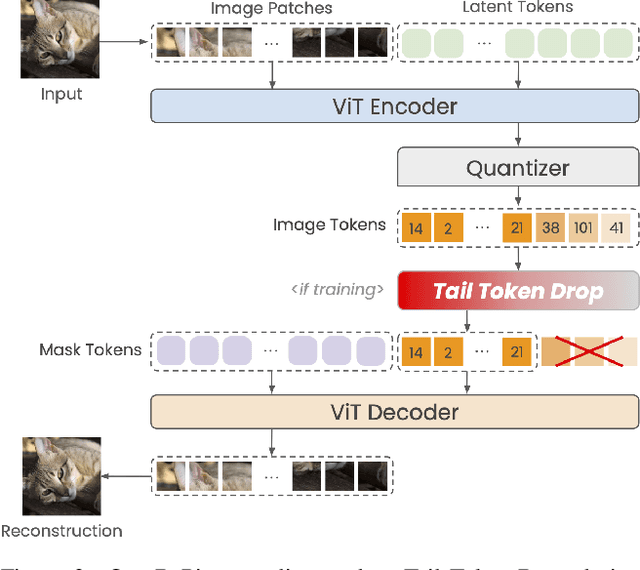
Current image tokenization methods require a large number of tokens to capture the information contained within images. Although the amount of information varies across images, most image tokenizers only support fixed-length tokenization, leading to inefficiency in token allocation. In this study, we introduce One-D-Piece, a discrete image tokenizer designed for variable-length tokenization, achieving quality-controllable mechanism. To enable variable compression rate, we introduce a simple but effective regularization mechanism named "Tail Token Drop" into discrete one-dimensional image tokenizers. This method encourages critical information to concentrate at the head of the token sequence, enabling support of variadic tokenization, while preserving state-of-the-art reconstruction quality. We evaluate our tokenizer across multiple reconstruction quality metrics and find that it delivers significantly better perceptual quality than existing quality-controllable compression methods, including JPEG and WebP, at smaller byte sizes. Furthermore, we assess our tokenizer on various downstream computer vision tasks, including image classification, object detection, semantic segmentation, and depth estimation, confirming its adaptability to numerous applications compared to other variable-rate methods. Our approach demonstrates the versatility of variable-length discrete image tokenization, establishing a new paradigm in both compression efficiency and reconstruction performance. Finally, we validate the effectiveness of tail token drop via detailed analysis of tokenizers.
ACT-Bench: Towards Action Controllable World Models for Autonomous Driving
Dec 06, 2024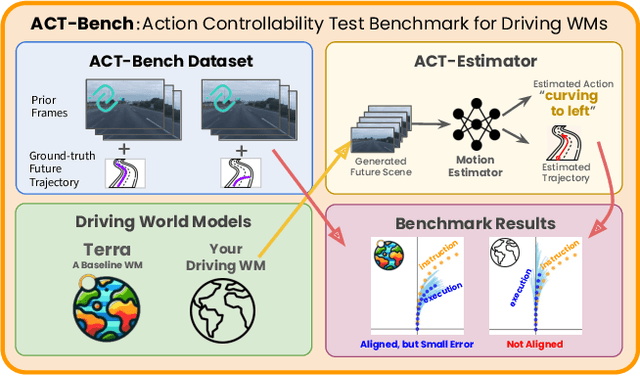



World models have emerged as promising neural simulators for autonomous driving, with the potential to supplement scarce real-world data and enable closed-loop evaluations. However, current research primarily evaluates these models based on visual realism or downstream task performance, with limited focus on fidelity to specific action instructions - a crucial property for generating targeted simulation scenes. Although some studies address action fidelity, their evaluations rely on closed-source mechanisms, limiting reproducibility. To address this gap, we develop an open-access evaluation framework, ACT-Bench, for quantifying action fidelity, along with a baseline world model, Terra. Our benchmarking framework includes a large-scale dataset pairing short context videos from nuScenes with corresponding future trajectory data, which provides conditional input for generating future video frames and enables evaluation of action fidelity for executed motions. Furthermore, Terra is trained on multiple large-scale trajectory-annotated datasets to enhance action fidelity. Leveraging this framework, we demonstrate that the state-of-the-art model does not fully adhere to given instructions, while Terra achieves improved action fidelity. All components of our benchmark framework will be made publicly available to support future research.
CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
Aug 19, 2024



Autonomous driving, particularly navigating complex and unanticipated scenarios, demands sophisticated reasoning and planning capabilities. While Multi-modal Large Language Models (MLLMs) offer a promising avenue for this, their use has been largely confined to understanding complex environmental contexts or generating high-level driving commands, with few studies extending their application to end-to-end path planning. A major research bottleneck is the lack of large-scale annotated datasets encompassing vision, language, and action. To address this issue, we propose CoVLA (Comprehensive Vision-Language-Action) Dataset, an extensive dataset comprising real-world driving videos spanning more than 80 hours. This dataset leverages a novel, scalable approach based on automated data processing and a caption generation pipeline to generate accurate driving trajectories paired with detailed natural language descriptions of driving environments and maneuvers. This approach utilizes raw in-vehicle sensor data, allowing it to surpass existing datasets in scale and annotation richness. Using CoVLA, we investigate the driving capabilities of MLLMs that can handle vision, language, and action in a variety of driving scenarios. Our results illustrate the strong proficiency of our model in generating coherent language and action outputs, emphasizing the potential of Vision-Language-Action (VLA) models in the field of autonomous driving. This dataset establishes a framework for robust, interpretable, and data-driven autonomous driving systems by providing a comprehensive platform for training and evaluating VLA models, contributing to safer and more reliable self-driving vehicles. The dataset is released for academic purpose.
Heron-Bench: A Benchmark for Evaluating Vision Language Models in Japanese
Apr 11, 2024Vision Language Models (VLMs) have undergone a rapid evolution, giving rise to significant advancements in the realm of multimodal understanding tasks. However, the majority of these models are trained and evaluated on English-centric datasets, leaving a gap in the development and evaluation of VLMs for other languages, such as Japanese. This gap can be attributed to the lack of methodologies for constructing VLMs and the absence of benchmarks to accurately measure their performance. To address this issue, we introduce a novel benchmark, Japanese Heron-Bench, for evaluating Japanese capabilities of VLMs. The Japanese Heron-Bench consists of a variety of imagequestion answer pairs tailored to the Japanese context. Additionally, we present a baseline Japanese VLM that has been trained with Japanese visual instruction tuning datasets. Our Heron-Bench reveals the strengths and limitations of the proposed VLM across various ability dimensions. Furthermore, we clarify the capability gap between strong closed models like GPT-4V and the baseline model, providing valuable insights for future research in this domain. We release the benchmark dataset and training code to facilitate further developments in Japanese VLM research.
Evaluation of Large Language Models for Decision Making in Autonomous Driving
Dec 11, 2023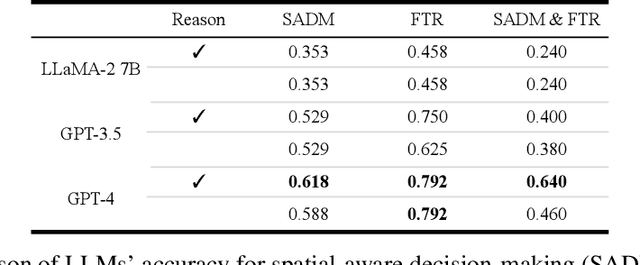



Various methods have been proposed for utilizing Large Language Models (LLMs) in autonomous driving. One strategy of using LLMs for autonomous driving involves inputting surrounding objects as text prompts to the LLMs, along with their coordinate and velocity information, and then outputting the subsequent movements of the vehicle. When using LLMs for such purposes, capabilities such as spatial recognition and planning are essential. In particular, two foundational capabilities are required: (1) spatial-aware decision making, which is the ability to recognize space from coordinate information and make decisions to avoid collisions, and (2) the ability to adhere to traffic rules. However, quantitative research has not been conducted on how accurately different types of LLMs can handle these problems. In this study, we quantitatively evaluated these two abilities of LLMs in the context of autonomous driving. Furthermore, to conduct a Proof of Concept (POC) for the feasibility of implementing these abilities in actual vehicles, we developed a system that uses LLMs to drive a vehicle.
NuScenes-MQA: Integrated Evaluation of Captions and QA for Autonomous Driving Datasets using Markup Annotations
Dec 11, 2023Visual Question Answering (VQA) is one of the most important tasks in autonomous driving, which requires accurate recognition and complex situation evaluations. However, datasets annotated in a QA format, which guarantees precise language generation and scene recognition from driving scenes, have not been established yet. In this work, we introduce Markup-QA, a novel dataset annotation technique in which QAs are enclosed within markups. This approach facilitates the simultaneous evaluation of a model's capabilities in sentence generation and VQA. Moreover, using this annotation methodology, we designed the NuScenes-MQA dataset. This dataset empowers the development of vision language models, especially for autonomous driving tasks, by focusing on both descriptive capabilities and precise QA. The dataset is available at https://github.com/turingmotors/NuScenes-MQA.