 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeron-Bench: A Benchmark for Evaluating Vision Language Models in Japanese
Apr 11, 2024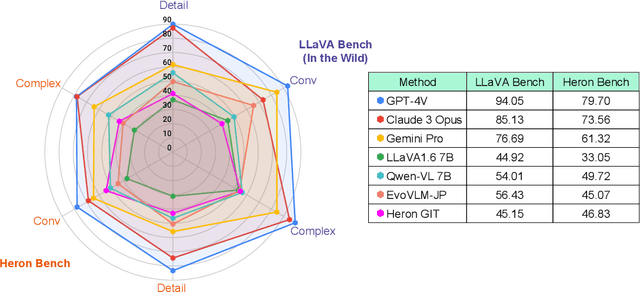
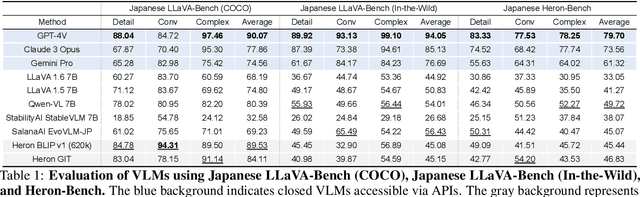
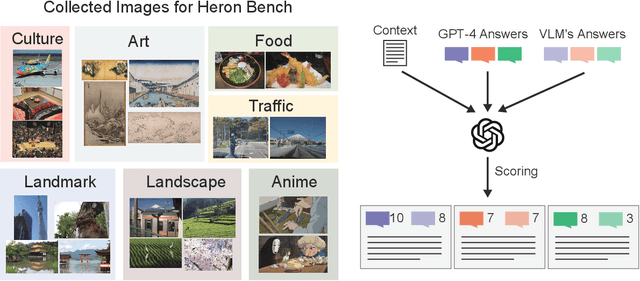
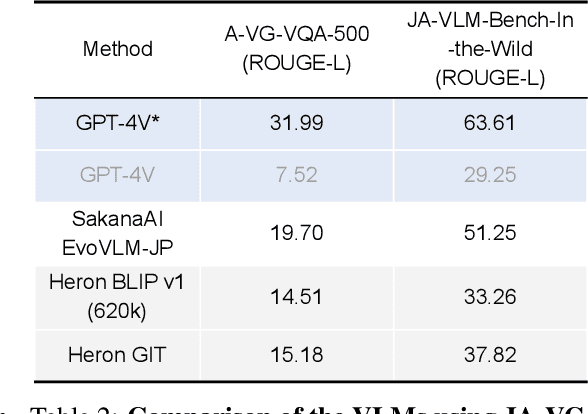
Vision Language Models (VLMs) have undergone a rapid evolution, giving rise to significant advancements in the realm of multimodal understanding tasks. However, the majority of these models are trained and evaluated on English-centric datasets, leaving a gap in the development and evaluation of VLMs for other languages, such as Japanese. This gap can be attributed to the lack of methodologies for constructing VLMs and the absence of benchmarks to accurately measure their performance. To address this issue, we introduce a novel benchmark, Japanese Heron-Bench, for evaluating Japanese capabilities of VLMs. The Japanese Heron-Bench consists of a variety of imagequestion answer pairs tailored to the Japanese context. Additionally, we present a baseline Japanese VLM that has been trained with Japanese visual instruction tuning datasets. Our Heron-Bench reveals the strengths and limitations of the proposed VLM across various ability dimensions. Furthermore, we clarify the capability gap between strong closed models like GPT-4V and the baseline model, providing valuable insights for future research in this domain. We release the benchmark dataset and training code to facilitate further developments in Japanese VLM research.
Evaluation of Large Language Models for Decision Making in Autonomous Driving
Dec 11, 2023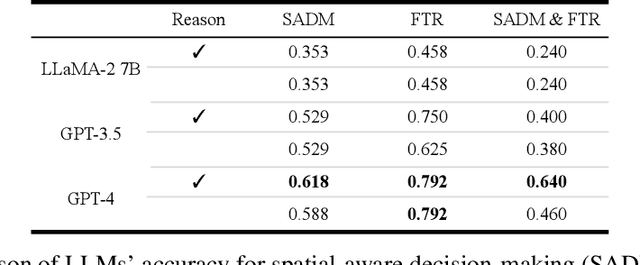



Various methods have been proposed for utilizing Large Language Models (LLMs) in autonomous driving. One strategy of using LLMs for autonomous driving involves inputting surrounding objects as text prompts to the LLMs, along with their coordinate and velocity information, and then outputting the subsequent movements of the vehicle. When using LLMs for such purposes, capabilities such as spatial recognition and planning are essential. In particular, two foundational capabilities are required: (1) spatial-aware decision making, which is the ability to recognize space from coordinate information and make decisions to avoid collisions, and (2) the ability to adhere to traffic rules. However, quantitative research has not been conducted on how accurately different types of LLMs can handle these problems. In this study, we quantitatively evaluated these two abilities of LLMs in the context of autonomous driving. Furthermore, to conduct a Proof of Concept (POC) for the feasibility of implementing these abilities in actual vehicles, we developed a system that uses LLMs to drive a vehicle.
NuScenes-MQA: Integrated Evaluation of Captions and QA for Autonomous Driving Datasets using Markup Annotations
Dec 11, 2023
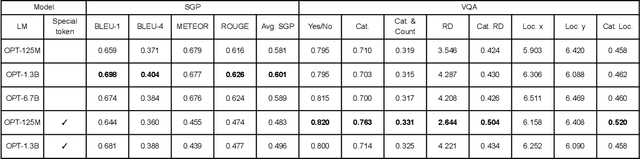
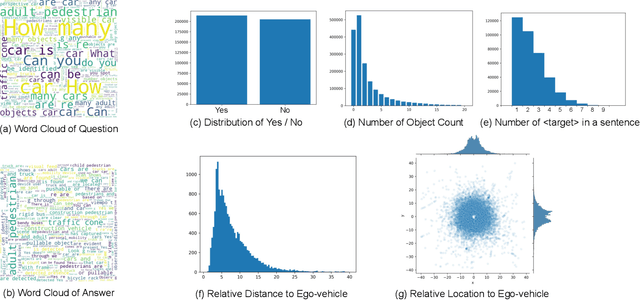
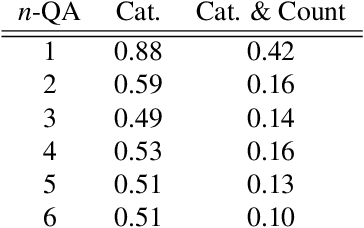
Visual Question Answering (VQA) is one of the most important tasks in autonomous driving, which requires accurate recognition and complex situation evaluations. However, datasets annotated in a QA format, which guarantees precise language generation and scene recognition from driving scenes, have not been established yet. In this work, we introduce Markup-QA, a novel dataset annotation technique in which QAs are enclosed within markups. This approach facilitates the simultaneous evaluation of a model's capabilities in sentence generation and VQA. Moreover, using this annotation methodology, we designed the NuScenes-MQA dataset. This dataset empowers the development of vision language models, especially for autonomous driving tasks, by focusing on both descriptive capabilities and precise QA. The dataset is available at https://github.com/turingmotors/NuScenes-MQA.