 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRead or Ignore? A Unified Benchmark for Typographic-Attack Robustness and Text Recognition in Vision-Language Models
Dec 10, 2025Large vision-language models (LVLMs) are vulnerable to typographic attacks, where misleading text within an image overrides visual understanding. Existing evaluation protocols and defenses, largely focused on object recognition, implicitly encourage ignoring text to achieve robustness; however, real-world scenarios often require joint reasoning over both objects and text (e.g., recognizing pedestrians while reading traffic signs). To address this, we introduce a novel task, Read-or-Ignore VQA (RIO-VQA), which formalizes selective text use in visual question answering (VQA): models must decide, from context, when to read text and when to ignore it. For evaluation, we present the Read-or-Ignore Benchmark (RIO-Bench), a standardized dataset and protocol that, for each real image, provides same-scene counterfactuals (read / ignore) by varying only the textual content and question type. Using RIO-Bench, we show that strong LVLMs and existing defenses fail to balance typographic robustness and text-reading capability, highlighting the need for improved approaches. Finally, RIO-Bench enables a novel data-driven defense that learns adaptive selective text use, moving beyond prior non-adaptive, text-ignoring defenses. Overall, this work reveals a fundamental misalignment between the existing evaluation scope and real-world requirements, providing a principled path toward reliable LVLMs. Our Project Page is at https://turingmotors.github.io/rio-vqa/.
Understanding Sensitivity of Differential Attention through the Lens of Adversarial Robustness
Oct 01, 2025Differential Attention (DA) has been proposed as a refinement to standard attention, suppressing redundant or noisy context through a subtractive structure and thereby reducing contextual hallucination. While this design sharpens task-relevant focus, we show that it also introduces a structural fragility under adversarial perturbations. Our theoretical analysis identifies negative gradient alignment-a configuration encouraged by DA's subtraction-as the key driver of sensitivity amplification, leading to increased gradient norms and elevated local Lipschitz constants. We empirically validate this Fragile Principle through systematic experiments on ViT/DiffViT and evaluations of pretrained CLIP/DiffCLIP, spanning five datasets in total. These results demonstrate higher attack success rates, frequent gradient opposition, and stronger local sensitivity compared to standard attention. Furthermore, depth-dependent experiments reveal a robustness crossover: stacking DA layers attenuates small perturbations via depth-dependent noise cancellation, though this protection fades under larger attack budgets. Overall, our findings uncover a fundamental trade-off: DA improves discriminative focus on clean inputs but increases adversarial vulnerability, underscoring the need to jointly design for selectivity and robustness in future attention mechanisms.
STRIDE-QA: Visual Question Answering Dataset for Spatiotemporal Reasoning in Urban Driving Scenes
Aug 14, 2025Vision-Language Models (VLMs) have been applied to autonomous driving to support decision-making in complex real-world scenarios. However, their training on static, web-sourced image-text pairs fundamentally limits the precise spatiotemporal reasoning required to understand and predict dynamic traffic scenes. We address this critical gap with STRIDE-QA, a large-scale visual question answering (VQA) dataset for physically grounded reasoning from an ego-centric perspective. Constructed from 100 hours of multi-sensor driving data in Tokyo, capturing diverse and challenging conditions, STRIDE-QA is the largest VQA dataset for spatiotemporal reasoning in urban driving, offering 16 million QA pairs over 285K frames. Grounded by dense, automatically generated annotations including 3D bounding boxes, segmentation masks, and multi-object tracks, the dataset uniquely supports both object-centric and ego-centric reasoning through three novel QA tasks that require spatial localization and temporal prediction. Our benchmarks demonstrate that existing VLMs struggle significantly, achieving near-zero scores on prediction consistency. In contrast, VLMs fine-tuned on STRIDE-QA exhibit dramatic performance gains, achieving 55% success in spatial localization and 28% consistency in future motion prediction, compared to near-zero scores from general-purpose VLMs. Therefore, STRIDE-QA establishes a comprehensive foundation for developing more reliable VLMs for safety-critical autonomous systems.
One-D-Piece: Image Tokenizer Meets Quality-Controllable Compression
Jan 17, 2025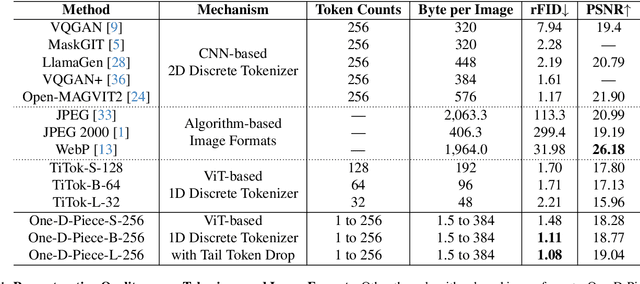

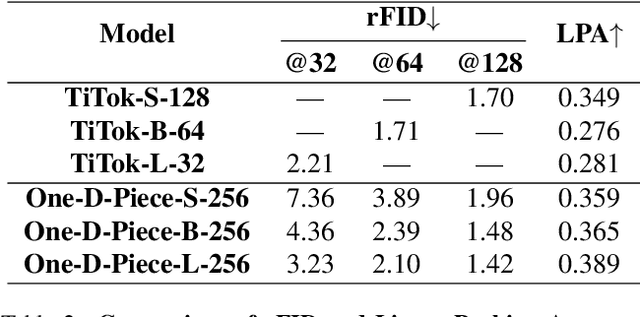
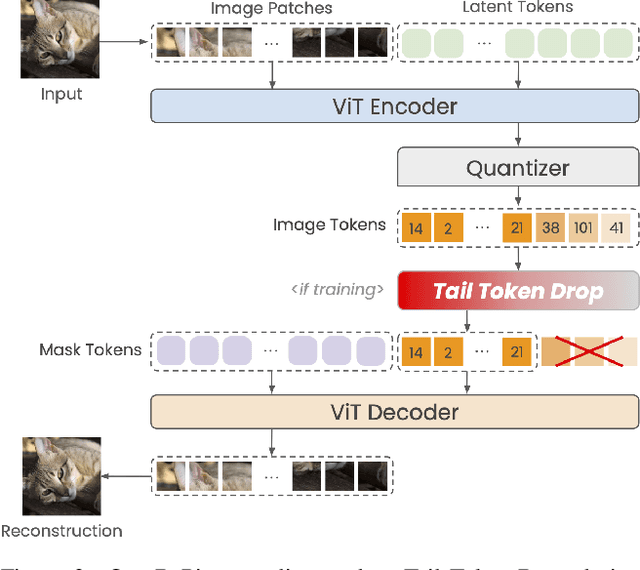
Current image tokenization methods require a large number of tokens to capture the information contained within images. Although the amount of information varies across images, most image tokenizers only support fixed-length tokenization, leading to inefficiency in token allocation. In this study, we introduce One-D-Piece, a discrete image tokenizer designed for variable-length tokenization, achieving quality-controllable mechanism. To enable variable compression rate, we introduce a simple but effective regularization mechanism named "Tail Token Drop" into discrete one-dimensional image tokenizers. This method encourages critical information to concentrate at the head of the token sequence, enabling support of variadic tokenization, while preserving state-of-the-art reconstruction quality. We evaluate our tokenizer across multiple reconstruction quality metrics and find that it delivers significantly better perceptual quality than existing quality-controllable compression methods, including JPEG and WebP, at smaller byte sizes. Furthermore, we assess our tokenizer on various downstream computer vision tasks, including image classification, object detection, semantic segmentation, and depth estimation, confirming its adaptability to numerous applications compared to other variable-rate methods. Our approach demonstrates the versatility of variable-length discrete image tokenization, establishing a new paradigm in both compression efficiency and reconstruction performance. Finally, we validate the effectiveness of tail token drop via detailed analysis of tokenizers.
CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
Aug 19, 2024



Autonomous driving, particularly navigating complex and unanticipated scenarios, demands sophisticated reasoning and planning capabilities. While Multi-modal Large Language Models (MLLMs) offer a promising avenue for this, their use has been largely confined to understanding complex environmental contexts or generating high-level driving commands, with few studies extending their application to end-to-end path planning. A major research bottleneck is the lack of large-scale annotated datasets encompassing vision, language, and action. To address this issue, we propose CoVLA (Comprehensive Vision-Language-Action) Dataset, an extensive dataset comprising real-world driving videos spanning more than 80 hours. This dataset leverages a novel, scalable approach based on automated data processing and a caption generation pipeline to generate accurate driving trajectories paired with detailed natural language descriptions of driving environments and maneuvers. This approach utilizes raw in-vehicle sensor data, allowing it to surpass existing datasets in scale and annotation richness. Using CoVLA, we investigate the driving capabilities of MLLMs that can handle vision, language, and action in a variety of driving scenarios. Our results illustrate the strong proficiency of our model in generating coherent language and action outputs, emphasizing the potential of Vision-Language-Action (VLA) models in the field of autonomous driving. This dataset establishes a framework for robust, interpretable, and data-driven autonomous driving systems by providing a comprehensive platform for training and evaluating VLA models, contributing to safer and more reliable self-driving vehicles. The dataset is released for academic purpose.
Heron-Bench: A Benchmark for Evaluating Vision Language Models in Japanese
Apr 11, 2024Vision Language Models (VLMs) have undergone a rapid evolution, giving rise to significant advancements in the realm of multimodal understanding tasks. However, the majority of these models are trained and evaluated on English-centric datasets, leaving a gap in the development and evaluation of VLMs for other languages, such as Japanese. This gap can be attributed to the lack of methodologies for constructing VLMs and the absence of benchmarks to accurately measure their performance. To address this issue, we introduce a novel benchmark, Japanese Heron-Bench, for evaluating Japanese capabilities of VLMs. The Japanese Heron-Bench consists of a variety of imagequestion answer pairs tailored to the Japanese context. Additionally, we present a baseline Japanese VLM that has been trained with Japanese visual instruction tuning datasets. Our Heron-Bench reveals the strengths and limitations of the proposed VLM across various ability dimensions. Furthermore, we clarify the capability gap between strong closed models like GPT-4V and the baseline model, providing valuable insights for future research in this domain. We release the benchmark dataset and training code to facilitate further developments in Japanese VLM research.
Machine-learning-enhanced quantum sensors for accurate magnetic field imaging
Feb 01, 2022Local detection of magnetic fields is crucial for characterizing nano- and micro-materials and has been implemented using various scanning techniques or even diamond quantum sensors. Diamond nanoparticles (nanodiamonds) offer an attractive opportunity to chieve high spatial resolution because they can easily be close to the target within a few 10 nm simply by attaching them to its surface. A physical model for such a randomly oriented nanodiamond ensemble (NDE) is available, but the complexity of actual experimental conditions still limits the accuracy of deducing magnetic fields. Here, we demonstrate magnetic field imaging with high accuracy of 1.8 $\mu$T combining NDE and machine learning without any physical models. We also discover the field direction dependence of the NDE signal, suggesting the potential application for vector magnetometry and improvement of the existing model. Our method further enriches the performance of NDE to achieve the accuracy to visualize mesoscopic current and magnetism in atomic-layer materials and to expand the applicability in arbitrarily shaped materials, including living organisms. This achievement will bridge machine learning and quantum sensing for accurate measurements.