 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-D-Piece: Image Tokenizer Meets Quality-Controllable Compression
Jan 17, 2025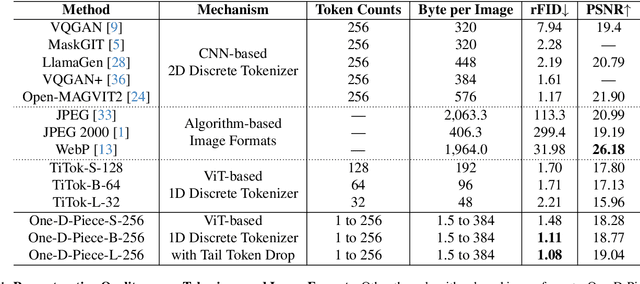

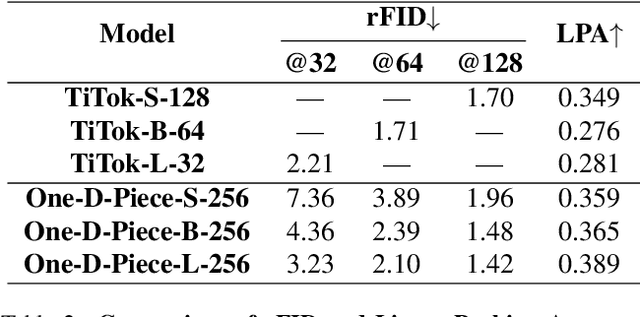
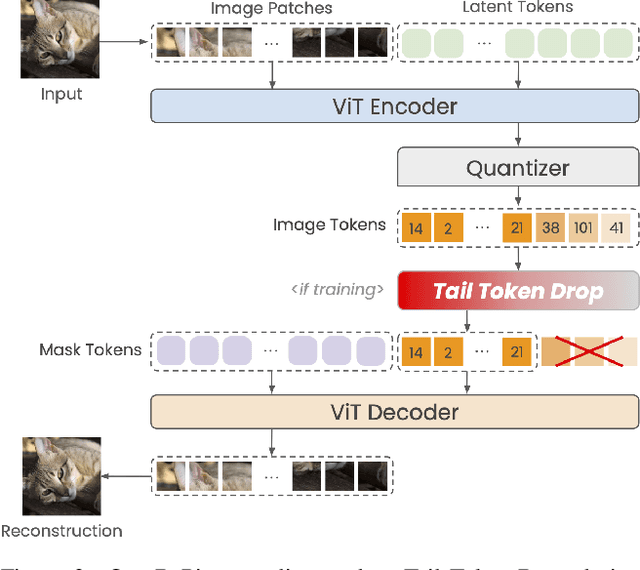
Current image tokenization methods require a large number of tokens to capture the information contained within images. Although the amount of information varies across images, most image tokenizers only support fixed-length tokenization, leading to inefficiency in token allocation. In this study, we introduce One-D-Piece, a discrete image tokenizer designed for variable-length tokenization, achieving quality-controllable mechanism. To enable variable compression rate, we introduce a simple but effective regularization mechanism named "Tail Token Drop" into discrete one-dimensional image tokenizers. This method encourages critical information to concentrate at the head of the token sequence, enabling support of variadic tokenization, while preserving state-of-the-art reconstruction quality. We evaluate our tokenizer across multiple reconstruction quality metrics and find that it delivers significantly better perceptual quality than existing quality-controllable compression methods, including JPEG and WebP, at smaller byte sizes. Furthermore, we assess our tokenizer on various downstream computer vision tasks, including image classification, object detection, semantic segmentation, and depth estimation, confirming its adaptability to numerous applications compared to other variable-rate methods. Our approach demonstrates the versatility of variable-length discrete image tokenization, establishing a new paradigm in both compression efficiency and reconstruction performance. Finally, we validate the effectiveness of tail token drop via detailed analysis of tokenizers.
ACT-Bench: Towards Action Controllable World Models for Autonomous Driving
Dec 06, 2024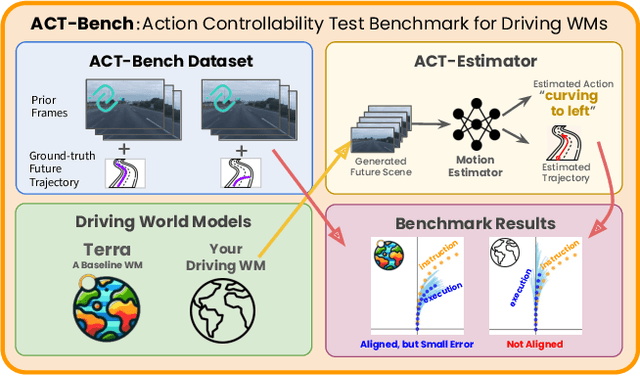



World models have emerged as promising neural simulators for autonomous driving, with the potential to supplement scarce real-world data and enable closed-loop evaluations. However, current research primarily evaluates these models based on visual realism or downstream task performance, with limited focus on fidelity to specific action instructions - a crucial property for generating targeted simulation scenes. Although some studies address action fidelity, their evaluations rely on closed-source mechanisms, limiting reproducibility. To address this gap, we develop an open-access evaluation framework, ACT-Bench, for quantifying action fidelity, along with a baseline world model, Terra. Our benchmarking framework includes a large-scale dataset pairing short context videos from nuScenes with corresponding future trajectory data, which provides conditional input for generating future video frames and enables evaluation of action fidelity for executed motions. Furthermore, Terra is trained on multiple large-scale trajectory-annotated datasets to enhance action fidelity. Leveraging this framework, we demonstrate that the state-of-the-art model does not fully adhere to given instructions, while Terra achieves improved action fidelity. All components of our benchmark framework will be made publicly available to support future research.
CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
Aug 19, 2024



Autonomous driving, particularly navigating complex and unanticipated scenarios, demands sophisticated reasoning and planning capabilities. While Multi-modal Large Language Models (MLLMs) offer a promising avenue for this, their use has been largely confined to understanding complex environmental contexts or generating high-level driving commands, with few studies extending their application to end-to-end path planning. A major research bottleneck is the lack of large-scale annotated datasets encompassing vision, language, and action. To address this issue, we propose CoVLA (Comprehensive Vision-Language-Action) Dataset, an extensive dataset comprising real-world driving videos spanning more than 80 hours. This dataset leverages a novel, scalable approach based on automated data processing and a caption generation pipeline to generate accurate driving trajectories paired with detailed natural language descriptions of driving environments and maneuvers. This approach utilizes raw in-vehicle sensor data, allowing it to surpass existing datasets in scale and annotation richness. Using CoVLA, we investigate the driving capabilities of MLLMs that can handle vision, language, and action in a variety of driving scenarios. Our results illustrate the strong proficiency of our model in generating coherent language and action outputs, emphasizing the potential of Vision-Language-Action (VLA) models in the field of autonomous driving. This dataset establishes a framework for robust, interpretable, and data-driven autonomous driving systems by providing a comprehensive platform for training and evaluating VLA models, contributing to safer and more reliable self-driving vehicles. The dataset is released for academic purpose.