 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACT-Bench: Towards Action Controllable World Models for Autonomous Driving
Paper and Code
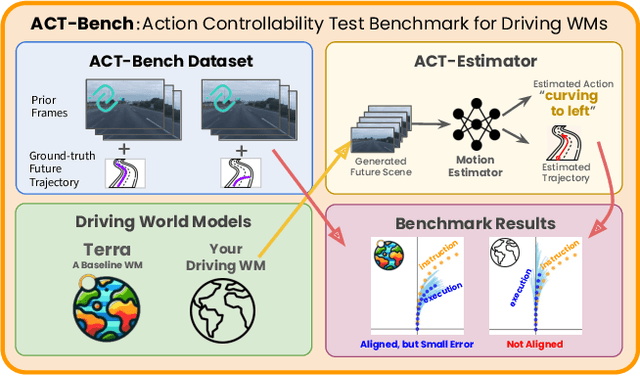



World models have emerged as promising neural simulators for autonomous driving, with the potential to supplement scarce real-world data and enable closed-loop evaluations. However, current research primarily evaluates these models based on visual realism or downstream task performance, with limited focus on fidelity to specific action instructions - a crucial property for generating targeted simulation scenes. Although some studies address action fidelity, their evaluations rely on closed-source mechanisms, limiting reproducibility. To address this gap, we develop an open-access evaluation framework, ACT-Bench, for quantifying action fidelity, along with a baseline world model, Terra. Our benchmarking framework includes a large-scale dataset pairing short context videos from nuScenes with corresponding future trajectory data, which provides conditional input for generating future video frames and enables evaluation of action fidelity for executed motions. Furthermore, Terra is trained on multiple large-scale trajectory-annotated datasets to enhance action fidelity. Leveraging this framework, we demonstrate that the state-of-the-art model does not fully adhere to given instructions, while Terra achieves improved action fidelity. All components of our benchmark framework will be made publicly available to support future research.