 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRIDE-QA: Visual Question Answering Dataset for Spatiotemporal Reasoning in Urban Driving Scenes
Aug 14, 2025Vision-Language Models (VLMs) have been applied to autonomous driving to support decision-making in complex real-world scenarios. However, their training on static, web-sourced image-text pairs fundamentally limits the precise spatiotemporal reasoning required to understand and predict dynamic traffic scenes. We address this critical gap with STRIDE-QA, a large-scale visual question answering (VQA) dataset for physically grounded reasoning from an ego-centric perspective. Constructed from 100 hours of multi-sensor driving data in Tokyo, capturing diverse and challenging conditions, STRIDE-QA is the largest VQA dataset for spatiotemporal reasoning in urban driving, offering 16 million QA pairs over 285K frames. Grounded by dense, automatically generated annotations including 3D bounding boxes, segmentation masks, and multi-object tracks, the dataset uniquely supports both object-centric and ego-centric reasoning through three novel QA tasks that require spatial localization and temporal prediction. Our benchmarks demonstrate that existing VLMs struggle significantly, achieving near-zero scores on prediction consistency. In contrast, VLMs fine-tuned on STRIDE-QA exhibit dramatic performance gains, achieving 55% success in spatial localization and 28% consistency in future motion prediction, compared to near-zero scores from general-purpose VLMs. Therefore, STRIDE-QA establishes a comprehensive foundation for developing more reliable VLMs for safety-critical autonomous systems.
ACT-Bench: Towards Action Controllable World Models for Autonomous Driving
Dec 06, 2024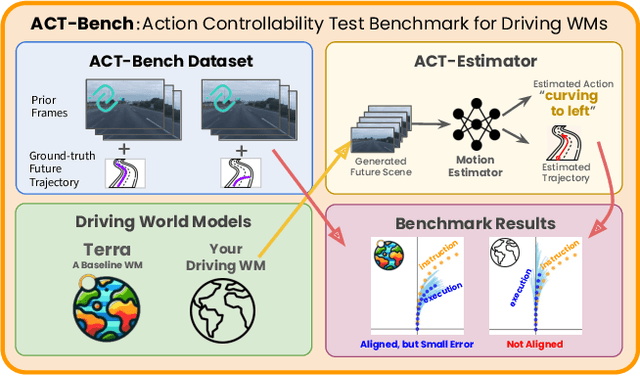



World models have emerged as promising neural simulators for autonomous driving, with the potential to supplement scarce real-world data and enable closed-loop evaluations. However, current research primarily evaluates these models based on visual realism or downstream task performance, with limited focus on fidelity to specific action instructions - a crucial property for generating targeted simulation scenes. Although some studies address action fidelity, their evaluations rely on closed-source mechanisms, limiting reproducibility. To address this gap, we develop an open-access evaluation framework, ACT-Bench, for quantifying action fidelity, along with a baseline world model, Terra. Our benchmarking framework includes a large-scale dataset pairing short context videos from nuScenes with corresponding future trajectory data, which provides conditional input for generating future video frames and enables evaluation of action fidelity for executed motions. Furthermore, Terra is trained on multiple large-scale trajectory-annotated datasets to enhance action fidelity. Leveraging this framework, we demonstrate that the state-of-the-art model does not fully adhere to given instructions, while Terra achieves improved action fidelity. All components of our benchmark framework will be made publicly available to support future research.
Multi-task Learning with Attention for End-to-end Autonomous Driving
Apr 21, 2021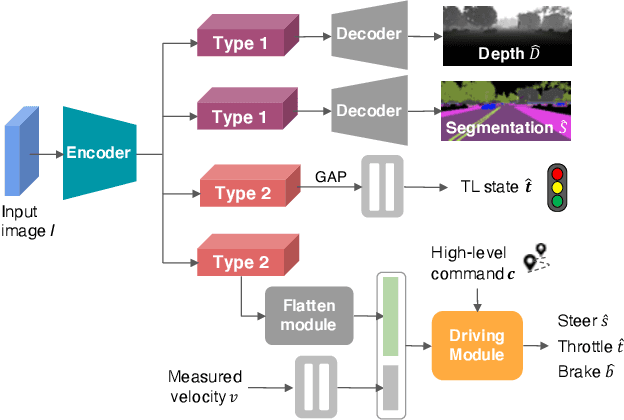
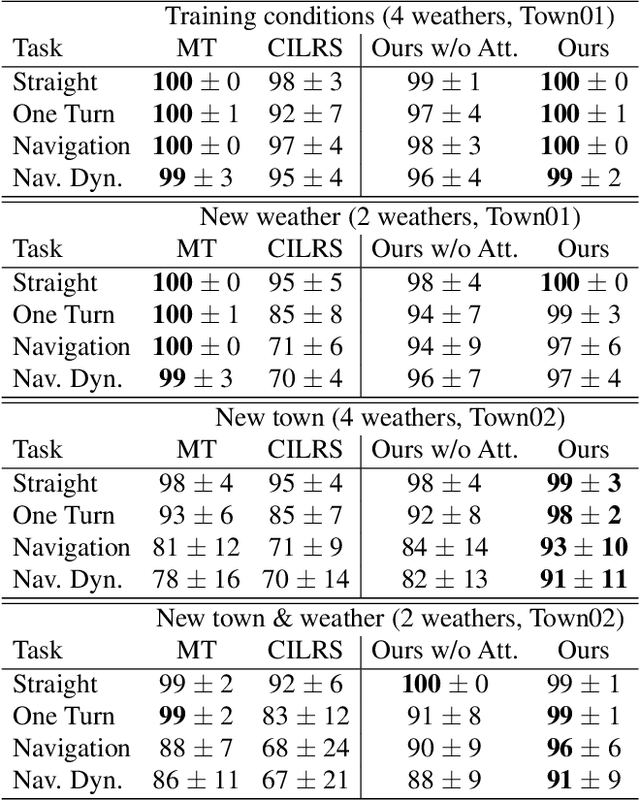
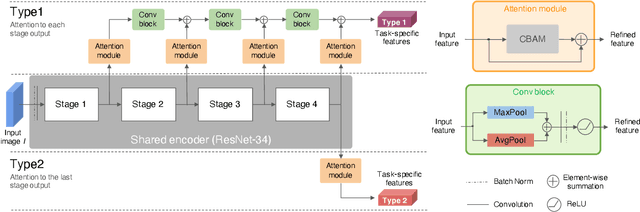
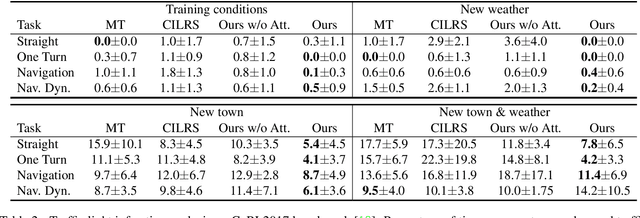
Autonomous driving systems need to handle complex scenarios such as lane following, avoiding collisions, taking turns, and responding to traffic signals. In recent years, approaches based on end-to-end behavioral cloning have demonstrated remarkable performance in point-to-point navigational scenarios, using a realistic simulator and standard benchmarks. Offline imitation learning is readily available, as it does not require expensive hand annotation or interaction with the target environment, but it is difficult to obtain a reliable system. In addition, existing methods have not specifically addressed the learning of reaction for traffic lights, which are a rare occurrence in the training datasets. Inspired by the previous work on multi-task learning and attention modeling, we propose a novel multi-task attention-aware network in the conditional imitation learning (CIL) framework. This does not only improve the success rate of standard benchmarks, but also the ability to react to traffic lights, which we show with standard benchmarks.