 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Compact Autonomous Driving Perception with Balanced Learning and Multi-sensor Fusion
Jun 02, 2026We present a novel compact deep multi-task learning model to handle various autonomous driving perception tasks in one forward pass. The model performs multiple views of semantic segmentation, depth estimation, light detection and ranging (LiDAR) segmentation, and bird's eye view projection simultaneously without being supported by other models. We also provide an adaptive loss weighting algorithm to tackle the imbalanced learning issue that occurred due to plenty of given tasks. Through data pre-processing and intermediate sensor fusion techniques, the model can process and combine multiple input modalities retrieved from RGB cameras, dynamic vision sensors (DVS), and LiDAR placed at several positions on the ego vehicle. Therefore, a better understanding of a dynamically changing environment can be achieved. Based on the ablation study, the model variant trained with our proposed method achieves a better performance. Furthermore, a comparative study is also conducted to clarify its performance and effectiveness against the combination of some recent models. As a result, our model maintains better performance even with much fewer parameters. Hence, the model can inference faster with less GPU memory utilization. Moreover, the result tends to be consistent in 3 different CARLA simulation datasets and 1 real-world nuScenes-lidarseg dataset. To support future research, we share codes and other files publicly at https://github.com/oskarnatan/compact-perception.
DeepIPCv3: Event-Aware Multi-Modal Sensor Fusion for Sudden Pedestrian Crossing Avoidance
May 31, 2026Current end-to-end autonomous driving systems predominantly rely on frame-based sensors, which suffer from inherent perception latency and motion blur during highly dynamic encounters, specifically sudden pedestrian crossings. To address this critical safety vulnerability, we propose DeepIPCv3, a novel multi-modal autonomous navigation framework that synergizes the dense 3D spatial geometry of LiDAR point clouds with the microsecond-level asynchronous event streams of a Dynamic Vision Sensor (DVS). We introduce a Transformer-inspired cross-modal attention mechanism to dynamically correlate these distinct modalities, allowing the network to instantaneously prioritize high-speed dynamic updates without sacrificing structural scene awareness. The fused latent representations are then mapped to safe local waypoints and executable control commands via a hybrid policy network that blends heuristic trajectory tracking with direct neural predictions. Due to the severe physical risks associated with live testing of these sudden crossing scenarios, the framework is rigorously evaluated offline using a custom multi-modal dataset collected across both well-illuminated noon and challenging evening conditions. Extensive comparative and ablation studies demonstrate that DeepIPCv3 achieves state-of-the-art predictive performance. By effectively eliminating exposure failures and motion blur, the proposed LiDAR and DVS fusion yields the lowest trajectory and control command errors, enabling highly reactive, mathematically bounded evasive maneuvers regardless of ambient illumination. To support future research, we will release the codes to our GitHub repo at https://github.com/oskarnatan/DeepIPCv3.
Seq-DeepIPC: Sequential Sensing for End-to-End Control in Legged Robot Navigation
Oct 27, 2025We present Seq-DeepIPC, a sequential end-to-end perception-to-control model for legged robot navigation in realworld environments. Seq-DeepIPC advances intelligent sensing for autonomous legged navigation by tightly integrating multi-modal perception (RGB-D + GNSS) with temporal fusion and control. The model jointly predicts semantic segmentation and depth estimation, giving richer spatial features for planning and control. For efficient deployment on edge devices, we use EfficientNet-B0 as the encoder, reducing computation while maintaining accuracy. Heading estimation is simplified by removing the noisy IMU and instead computing the bearing angle directly from consecutive GNSS positions. We collected a larger and more diverse dataset that includes both road and grass terrains, and validated Seq-DeepIPC on a robot dog. Comparative and ablation studies show that sequential inputs improve perception and control in our models, while other baselines do not benefit. Seq-DeepIPC achieves competitive or better results with reasonable model size; although GNSS-only heading is less reliable near tall buildings, it is robust in open areas. Overall, Seq-DeepIPC extends end-to-end navigation beyond wheeled robots to more versatile and temporally-aware systems. To support future research, we will release the codes to our GitHub repository at https://github.com/oskarnatan/Seq-DeepIPC.
Combining Ontological Knowledge and Large Language Model for User-Friendly Service Robots
Oct 22, 2024


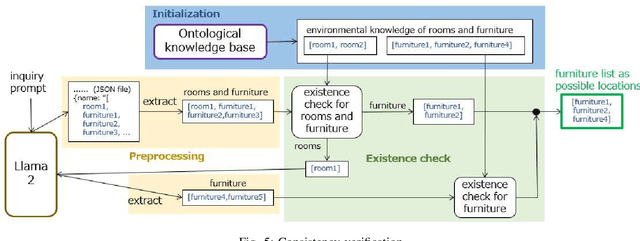
Lifestyle support through robotics is an increasingly promising field, with expectations for robots to take over or assist with chores like floor cleaning, table setting and clearing, and fetching items. The growth of AI, particularly foundation models, such as large language models (LLMs) and visual language models (VLMs), is significantly shaping this sector. LLMs, by facilitating natural interactions and providing vast general knowledge, are proving invaluable for robotic tasks. This paper zeroes in on the benefits of LLMs for "bring-me" tasks, where robots fetch specific items for users, often based on vague instructions. Our previous efforts utilized an ontology extended to handle environmental data to decipher such vagueness, but faced limitations when unresolvable ambiguities required user intervention for clarity. Here, we enhance our approach by integrating LLMs for providing additional commonsense knowledge, pairing it with ontological data to mitigate the issue of hallucinations and reduce the need for user queries, thus improving system usability. We present a system that merges these knowledge bases and assess its efficacy on "bring-me" tasks, aiming to provide a more seamless and efficient robotic assistance experience.
Natural Language as Polices: Reasoning for Coordinate-Level Embodied Control with LLMs
Mar 20, 2024



We demonstrate experimental results with LLMs that address robotics action planning problems. Recently, LLMs have been applied in robotics action planning, particularly using a code generation approach that converts complex high-level instructions into mid-level policy codes. In contrast, our approach acquires text descriptions of the task and scene objects, then formulates action planning through natural language reasoning, and outputs coordinate level control commands, thus reducing the necessity for intermediate representation code as policies. Our approach is evaluated on a multi-modal prompt simulation benchmark, demonstrating that our prompt engineering experiments with natural language reasoning significantly enhance success rates compared to its absence. Furthermore, our approach illustrates the potential for natural language descriptions to transfer robotics skills from known tasks to previously unseen tasks.
DeepIPCv2: LiDAR-powered Robust Environmental Perception and Navigational Control for Autonomous Vehicle
Jul 31, 2023



We present DeepIPCv2, an autonomous driving model that perceives the environment using a LiDAR sensor for more robust drivability, especially when driving under poor illumination conditions where everything is not clearly visible. DeepIPCv2 takes a set of LiDAR point clouds as the main perception input. Since point clouds are not affected by illumination changes, they can provide a clear observation of the surroundings no matter what the condition is. This results in a better scene understanding and stable features provided by the perception module to support the controller module in estimating navigational control properly. To evaluate its performance, we conduct several tests by deploying the model to predict a set of driving records and perform real automated driving under three different conditions. We also conduct ablation and comparative studies with some recent models to justify its performance. Based on the experimental results, DeepIPCv2 shows a robust performance by achieving the best drivability in all driving scenarios. Furthermore, we will upload the codes to https://github.com/oskarnatan/DeepIPCv2.
Multi-Source Soft Pseudo-Label Learning with Domain Similarity-based Weighting for Semantic Segmentation
Mar 02, 2023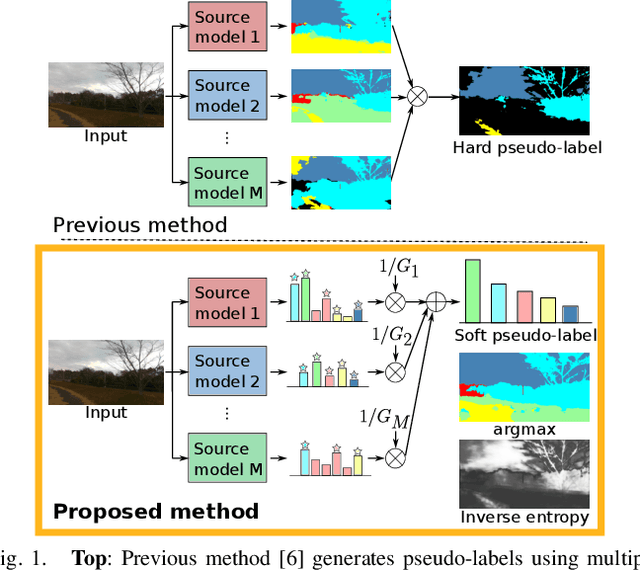
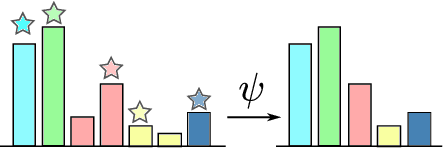


This paper describes a method of domain adaptive training for semantic segmentation using multiple source datasets that are not necessarily relevant to the target dataset. We propose a soft pseudo-label generation method by integrating predicted object probabilities from multiple source models. The prediction of each source model is weighted based on the estimated domain similarity between the source and the target datasets to emphasize contribution of a model trained on a source that is more similar to the target and generate reasonable pseudo-labels. We also propose a training method using the soft pseudo-labels considering their entropy to fully exploit information from the source datasets while suppressing the influence of possibly misclassified pixels. The experiments show comparative or better performance than our previous work and another existing multi-source domain adaptation method, and applicability to a variety of target environments.
Online Refinement of a Scene Recognition Model for Mobile Robots by Observing Human's Interaction with Environments
Aug 13, 2022

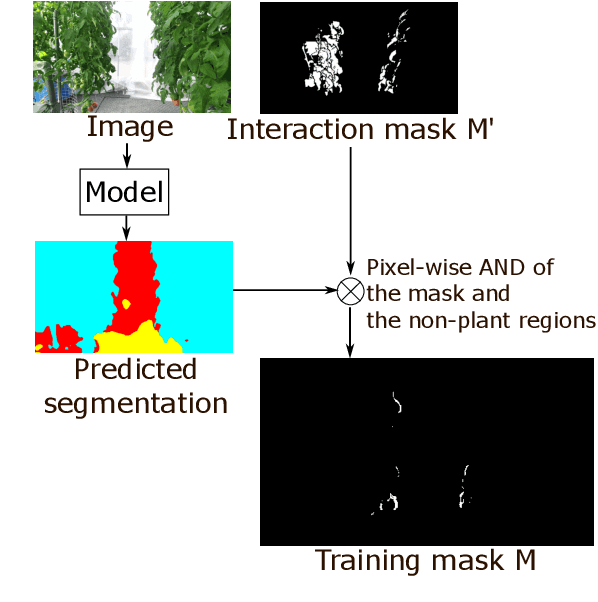

This paper describes a method of online refinement of a scene recognition model for robot navigation considering traversable plants, flexible plant parts which a robot can push aside while moving. In scene recognition systems that consider traversable plants growing out to the paths, misclassification may lead the robot to getting stuck due to the traversable plants recognized as obstacles. Yet, misclassification is inevitable in any estimation methods. In this work, we propose a framework that allows for refining a semantic segmentation model on the fly during the robot's operation. We introduce a few-shot segmentation based on weight imprinting for online model refinement without fine-tuning. Training data are collected via observation of a human's interaction with the plant parts. We propose novel robust weight imprinting to mitigate the effect of noise included in the masks generated by the interaction. The proposed method was evaluated through experiments using real-world data and shown to outperform an ordinary weight imprinting and provide competitive results to fine-tuning with model distillation while requiring less computational cost.
DeepIPC: Deeply Integrated Perception and Control for Mobile Robot in Real Environments
Aug 02, 2022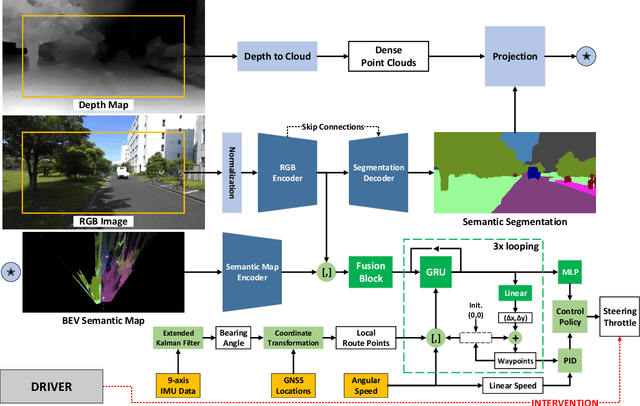
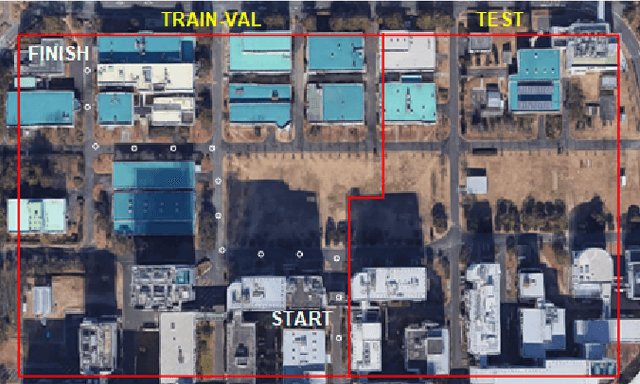
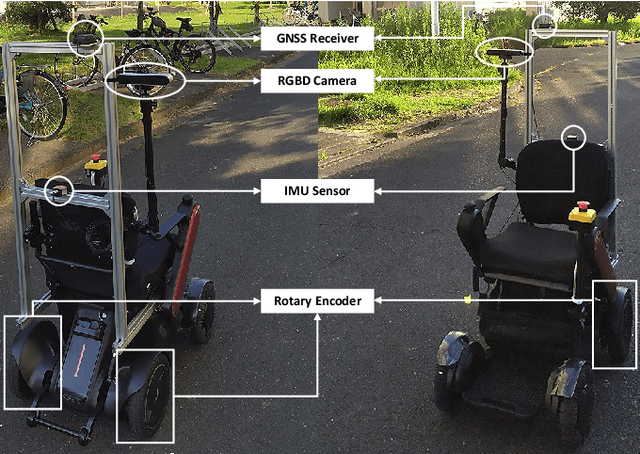

We propose DeepIPC, an end-to-end multi-task model that handles both perception and control tasks in driving a mobile robot autonomously. The model consists of two main parts, perception and controller modules. The perception module takes RGB image and depth map to perform semantic segmentation and bird's eye view (BEV) semantic mapping along with providing their encoded features. Meanwhile, the controller module processes these features with the measurement of GNSS locations and angular speed to estimate waypoints that come with latent features. Then, two different agents are used to translate waypoints and latent features into a set of navigational controls to drive the robot. The model is evaluated by predicting driving records and performing automated driving under various conditions in the real environment. Based on the experimental results, DeepIPC achieves the best drivability and multi-task performance even with fewer parameters compared to the other models.
Fully End-to-end Autonomous Driving with Semantic Depth Cloud Mapping and Multi-Agent
Apr 12, 2022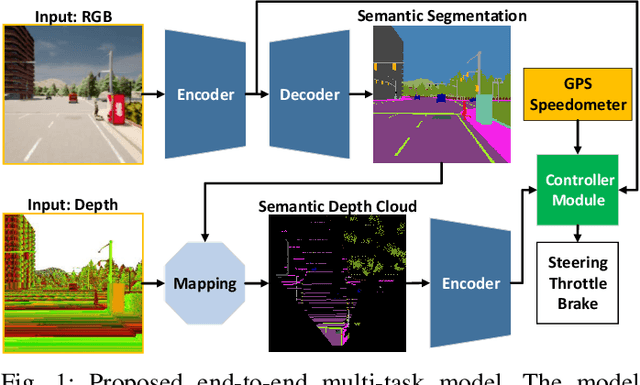
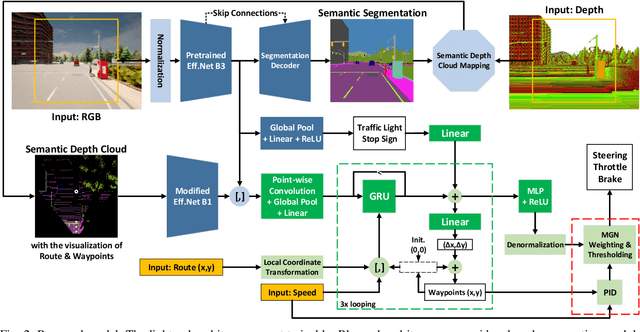
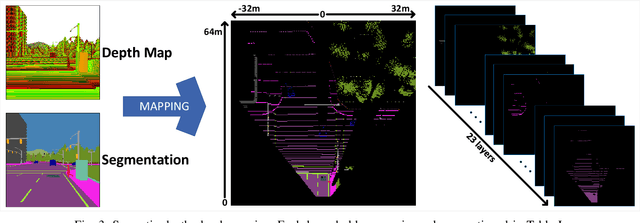
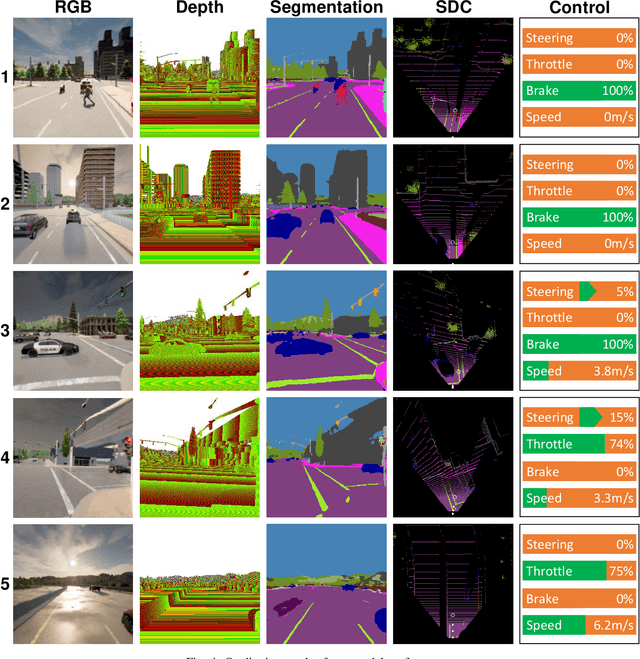
Focusing on the task of point-to-point navigation for an autonomous driving vehicle, we propose a novel deep learning model trained with end-to-end and multi-task learning manners to perform both perception and control tasks simultaneously. The model is used to drive the ego vehicle safely by following a sequence of routes defined by the global planner. The perception part of the model is used to encode high-dimensional observation data provided by an RGBD camera while performing semantic segmentation, semantic depth cloud (SDC) mapping, and traffic light state and stop sign prediction. Then, the control part decodes the encoded features along with additional information provided by GPS and speedometer to predict waypoints that come with a latent feature space. Furthermore, two agents are employed to process these outputs and make a control policy that determines the level of steering, throttle, and brake as the final action. The model is evaluated on CARLA simulator with various scenarios made of normal-adversarial situations and different weathers to mimic real-world conditions. In addition, we do a comparative study with some recent models to justify the performance in multiple aspects of driving. Moreover, we also conduct an ablation study on SDC mapping and multi-agent to understand their roles and behavior. As a result, our model achieves the highest driving score even with fewer parameters and computation load. To support future studies, we share our codes at https://github.com/oskarnatan/end-to-end-driving.