 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Source Soft Pseudo-Label Learning with Domain Similarity-based Weighting for Semantic Segmentation
Mar 02, 2023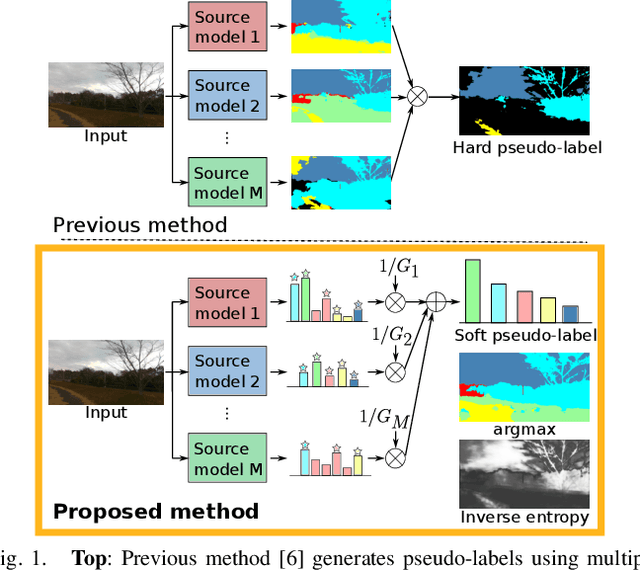


This paper describes a method of domain adaptive training for semantic segmentation using multiple source datasets that are not necessarily relevant to the target dataset. We propose a soft pseudo-label generation method by integrating predicted object probabilities from multiple source models. The prediction of each source model is weighted based on the estimated domain similarity between the source and the target datasets to emphasize contribution of a model trained on a source that is more similar to the target and generate reasonable pseudo-labels. We also propose a training method using the soft pseudo-labels considering their entropy to fully exploit information from the source datasets while suppressing the influence of possibly misclassified pixels. The experiments show comparative or better performance than our previous work and another existing multi-source domain adaptation method, and applicability to a variety of target environments.
Online Refinement of a Scene Recognition Model for Mobile Robots by Observing Human's Interaction with Environments
Aug 13, 2022

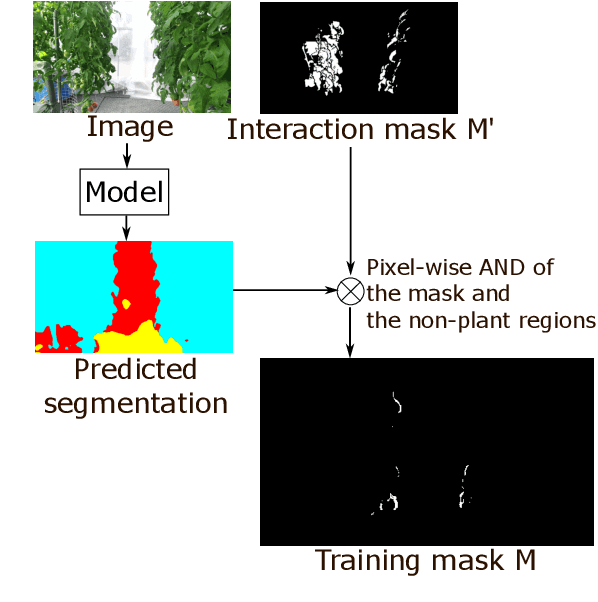

This paper describes a method of online refinement of a scene recognition model for robot navigation considering traversable plants, flexible plant parts which a robot can push aside while moving. In scene recognition systems that consider traversable plants growing out to the paths, misclassification may lead the robot to getting stuck due to the traversable plants recognized as obstacles. Yet, misclassification is inevitable in any estimation methods. In this work, we propose a framework that allows for refining a semantic segmentation model on the fly during the robot's operation. We introduce a few-shot segmentation based on weight imprinting for online model refinement without fine-tuning. Training data are collected via observation of a human's interaction with the plant parts. We propose novel robust weight imprinting to mitigate the effect of noise included in the masks generated by the interaction. The proposed method was evaluated through experiments using real-world data and shown to outperform an ordinary weight imprinting and provide competitive results to fine-tuning with model distillation while requiring less computational cost.
Semantic-aware plant traversability estimation in plant-rich environments for agricultural mobile robots
Aug 02, 2021
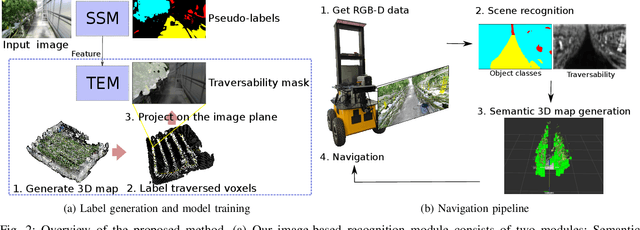

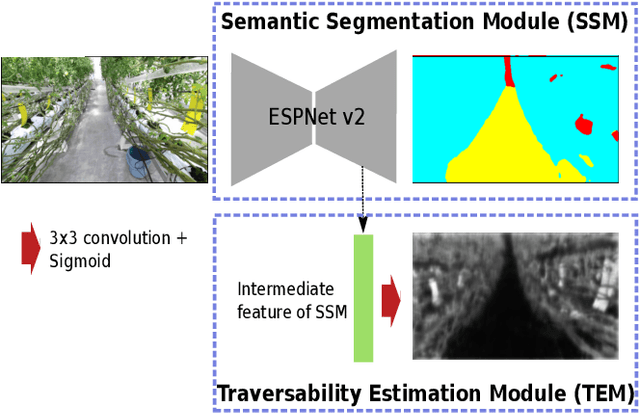
This paper describes a method of estimating the traversability of plant parts covering a path and navigating through them in greenhouses for agricultural mobile robots. Conventional mobile robots rely on scene recognition methods that consider only the presence of objects. Those methods, therefore, cannot recognize paths covered by flexible plants as traversable. In this paper, we present a novel framework of the scene recognition based on image-based semantic segmentation for robot navigation that takes into account the traversable plants covering the paths. In addition, for easily creating training data of the traversability estimation model, we propose a method of generating labels of traversable regions in the images, which we call Traversability masks, based on the robot's traversal experience during the data acquisition phase. It is often difficult for humans to distinguish the traversable plant parts on the images. Our method enables consistent and automatic labeling of those image regions based on the fact of the traversals. We conducted a real world experiment and confirmed that the robot with the proposed recognition method successfully navigated in plant-rich environments.
Multi-source Pseudo-label Learning of Semantic Segmentation for the Scene Recognition of Agricultural Mobile Robots
Feb 12, 2021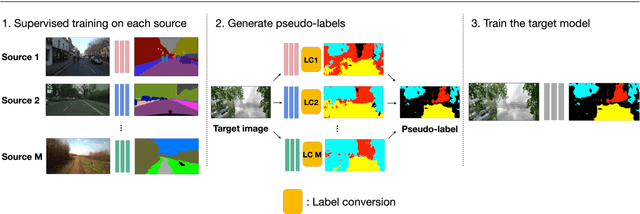
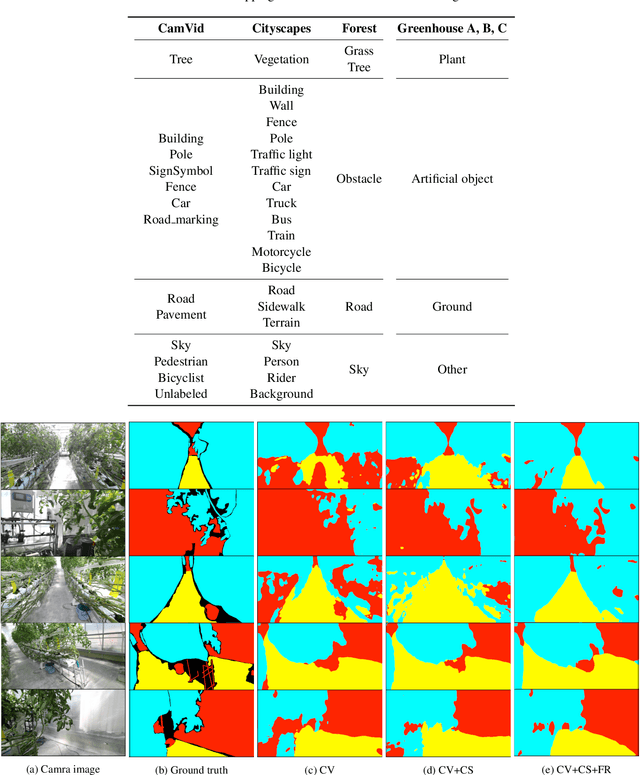

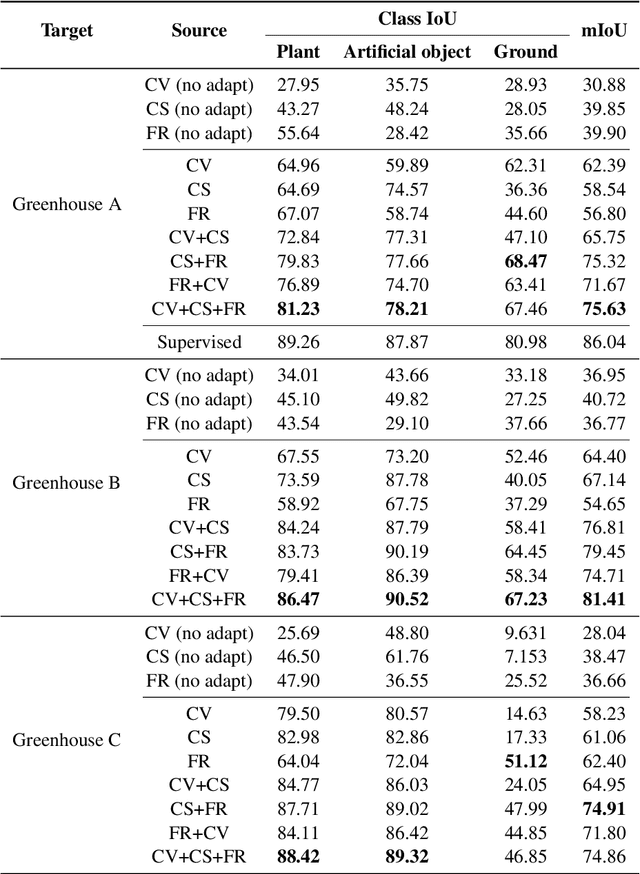
This paper describes a novel method of training a semantic segmentation model for environment recognition of agricultural mobile robots by unsupervised domain adaptation exploiting publicly available datasets of outdoor scenes that are different from our target environments i.e., greenhouses. In conventional semantic segmentation methods, the labels are given by manual annotation, which is a tedious and time-consuming task. A method to work around the necessity of the manual annotation is unsupervised domain adaptation (UDA) that transfer knowledge from labeled source datasets to unlabeled target datasets. Most of the UDA methods of semantic segmentation are validated by tasks of adaptation from non-photorealistic synthetic images of urban scenes to real ones. However, the effectiveness of the methods is not well studied in the case of adaptation to other types of environments, such as greenhouses. In addition, it is not always possible to prepare appropriate source datasets for such environments. In this paper, we adopt an existing training method of UDA to a task of training a model for greenhouse images. We propose to use multiple publicly available datasets of outdoor images as source datasets, and also propose a simple yet effective method of generating pseudo-labels by transferring knowledge from the source datasets that have different appearance and a label set from the target datasets. We demonstrate in experiments that by combining our proposed method of pseudo-label generation with the existing training method, the performance was improved by up to 14.3% of mIoU compared to the best score of the single-source training.