 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepIPC: Deeply Integrated Perception and Control for Mobile Robot in Real Environments
Paper and Code
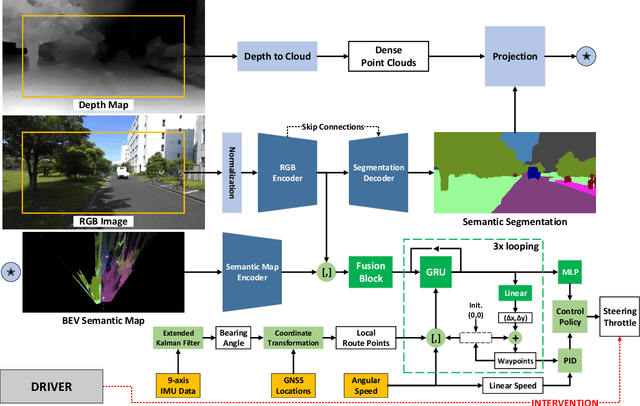
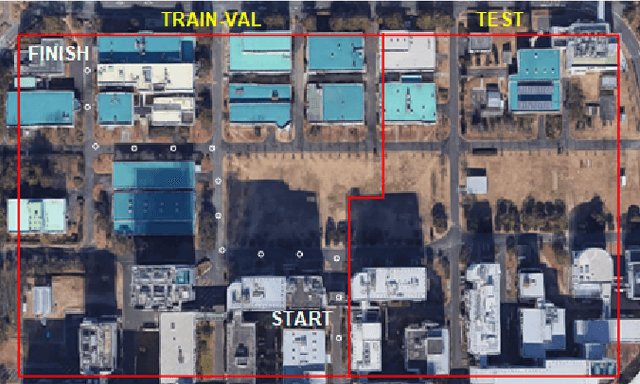
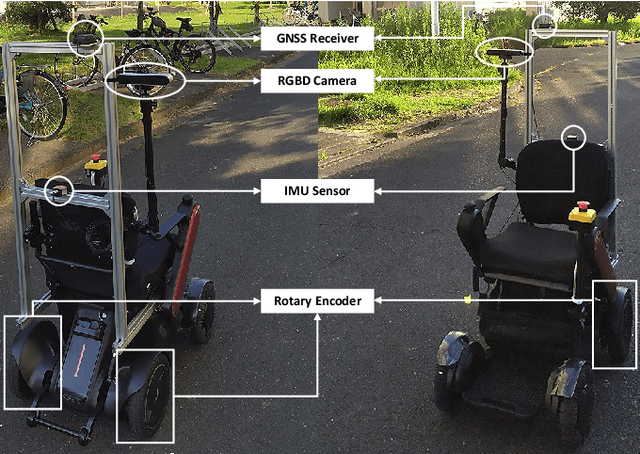

We propose DeepIPC, an end-to-end multi-task model that handles both perception and control tasks in driving a mobile robot autonomously. The model consists of two main parts, perception and controller modules. The perception module takes RGB image and depth map to perform semantic segmentation and bird's eye view (BEV) semantic mapping along with providing their encoded features. Meanwhile, the controller module processes these features with the measurement of GNSS locations and angular speed to estimate waypoints that come with latent features. Then, two different agents are used to translate waypoints and latent features into a set of navigational controls to drive the robot. The model is evaluated by predicting driving records and performing automated driving under various conditions in the real environment. Based on the experimental results, DeepIPC achieves the best drivability and multi-task performance even with fewer parameters compared to the other models.