 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Large Language Models for Decision Making in Autonomous Driving
Dec 11, 2023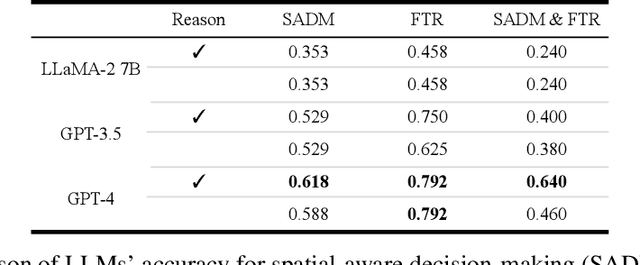



Various methods have been proposed for utilizing Large Language Models (LLMs) in autonomous driving. One strategy of using LLMs for autonomous driving involves inputting surrounding objects as text prompts to the LLMs, along with their coordinate and velocity information, and then outputting the subsequent movements of the vehicle. When using LLMs for such purposes, capabilities such as spatial recognition and planning are essential. In particular, two foundational capabilities are required: (1) spatial-aware decision making, which is the ability to recognize space from coordinate information and make decisions to avoid collisions, and (2) the ability to adhere to traffic rules. However, quantitative research has not been conducted on how accurately different types of LLMs can handle these problems. In this study, we quantitatively evaluated these two abilities of LLMs in the context of autonomous driving. Furthermore, to conduct a Proof of Concept (POC) for the feasibility of implementing these abilities in actual vehicles, we developed a system that uses LLMs to drive a vehicle.
Queueing Analysis of GPU-Based Inference Servers with Dynamic Batching: A Closed-Form Characterization
Dec 13, 2019



GPU-accelerated computing is a key technology to realize high-speed inference servers using deep neural networks (DNNs). An important characteristic of GPU-based inference is that the computational efficiency, in terms of the processing speed and energy consumption, drastically increases by processing multiple jobs together in a batch. In this paper, we formulate GPU-based inference servers as a batch service queueing model with batch-size dependent processing times. We first show that the energy efficiency of the server monotonically increases with the arrival rate of inference jobs, which suggests that it is energy-efficient to operate the inference server under a utilization level as high as possible within a latency requirement of inference jobs. We then derive a closed-form upper bound for the mean latency, which provides a simple characterization of the latency performance. Through simulation and numerical experiments, we show that the exact value of the mean latency is well approximated by this upper bound.