 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Large Language Models for Decision Making in Autonomous Driving
Dec 11, 2023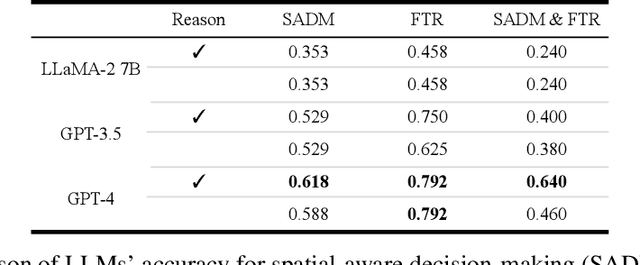



Various methods have been proposed for utilizing Large Language Models (LLMs) in autonomous driving. One strategy of using LLMs for autonomous driving involves inputting surrounding objects as text prompts to the LLMs, along with their coordinate and velocity information, and then outputting the subsequent movements of the vehicle. When using LLMs for such purposes, capabilities such as spatial recognition and planning are essential. In particular, two foundational capabilities are required: (1) spatial-aware decision making, which is the ability to recognize space from coordinate information and make decisions to avoid collisions, and (2) the ability to adhere to traffic rules. However, quantitative research has not been conducted on how accurately different types of LLMs can handle these problems. In this study, we quantitatively evaluated these two abilities of LLMs in the context of autonomous driving. Furthermore, to conduct a Proof of Concept (POC) for the feasibility of implementing these abilities in actual vehicles, we developed a system that uses LLMs to drive a vehicle.