 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy is the User Interface a Dark Pattern? : Explainable Auto-Detection and its Analysis
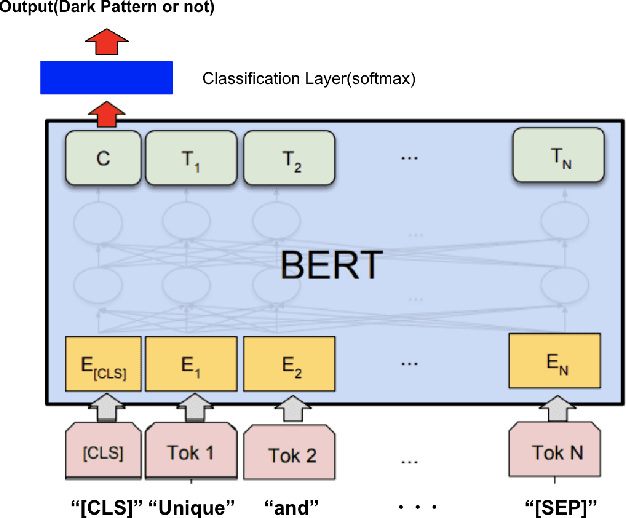
Dec 30, 2023Dark patterns are deceptive user interface designs for online services that make users behave in unintended ways. Dark patterns, such as privacy invasion, financial loss, and emotional distress, can harm users. These issues have been the subject of considerable debate in recent years. In this paper, we study interpretable dark pattern auto-detection, that is, why a particular user interface is detected as having dark patterns. First, we trained a model using transformer-based pre-trained language models, BERT, on a text-based dataset for the automatic detection of dark patterns in e-commerce. Then, we applied post-hoc explanation techniques, including local interpretable model agnostic explanation (LIME) and Shapley additive explanations (SHAP), to the trained model, which revealed which terms influence each prediction as a dark pattern. In addition, we extracted and analyzed terms that affected the dark patterns. Our findings may prevent users from being manipulated by dark patterns, and aid in the construction of more equitable internet services. Our code is available at https://github.com/yamanalab/why-darkpattern.
NuScenes-MQA: Integrated Evaluation of Captions and QA for Autonomous Driving Datasets using Markup Annotations
Dec 11, 2023Visual Question Answering (VQA) is one of the most important tasks in autonomous driving, which requires accurate recognition and complex situation evaluations. However, datasets annotated in a QA format, which guarantees precise language generation and scene recognition from driving scenes, have not been established yet. In this work, we introduce Markup-QA, a novel dataset annotation technique in which QAs are enclosed within markups. This approach facilitates the simultaneous evaluation of a model's capabilities in sentence generation and VQA. Moreover, using this annotation methodology, we designed the NuScenes-MQA dataset. This dataset empowers the development of vision language models, especially for autonomous driving tasks, by focusing on both descriptive capabilities and precise QA. The dataset is available at https://github.com/turingmotors/NuScenes-MQA.
Dark patterns in e-commerce: a dataset and its baseline evaluations
Nov 12, 2022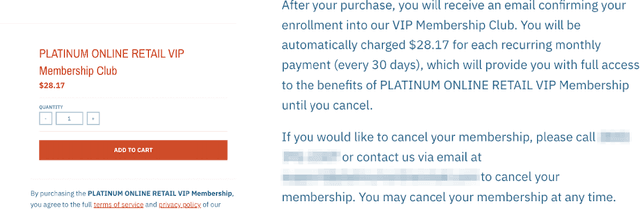

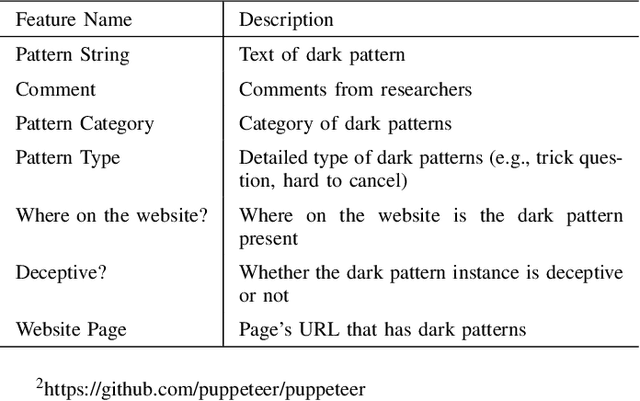
Dark patterns, which are user interface designs in online services, induce users to take unintended actions. Recently, dark patterns have been raised as an issue of privacy and fairness. Thus, a wide range of research on detecting dark patterns is eagerly awaited. In this work, we constructed a dataset for dark pattern detection and prepared its baseline detection performance with state-of-the-art machine learning methods. The original dataset was obtained from Mathur et al.'s study in 2019, which consists of 1,818 dark pattern texts from shopping sites. Then, we added negative samples, i.e., non-dark pattern texts, by retrieving texts from the same websites as Mathur et al.'s dataset. We also applied state-of-the-art machine learning methods to show the automatic detection accuracy as baselines, including BERT, RoBERTa, ALBERT, and XLNet. As a result of 5-fold cross-validation, we achieved the highest accuracy of 0.975 with RoBERTa. The dataset and baseline source codes are available at https://github.com/yamanalab/ec-darkpattern.