 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Fashion Recommendation with Image Attributes and Aesthetics Assessment
Jan 06, 2025



Personalized fashion recommendation is a difficult task because 1) the decisions are highly correlated with users' aesthetic appetite, which previous work frequently overlooks, and 2) many new items are constantly rolling out that cause strict cold-start problems in the popular identity (ID)-based recommendation methods. These new items are critical to recommend because of trend-driven consumerism. In this work, we aim to provide more accurate personalized fashion recommendations and solve the cold-start problem by converting available information, especially images, into two attribute graphs focusing on optimized image utilization and noise-reducing user modeling. Compared with previous methods that separate image and text as two components, the proposed method combines image and text information to create a richer attributes graph. Capitalizing on the advancement of large language and vision models, we experiment with extracting fine-grained attributes efficiently and as desired using two different prompts. Preliminary experiments on the IQON3000 dataset have shown that the proposed method achieves competitive accuracy compared with baselines.
Data-Efficient Massive Tool Retrieval: A Reinforcement Learning Approach for Query-Tool Alignment with Language Models
Oct 04, 2024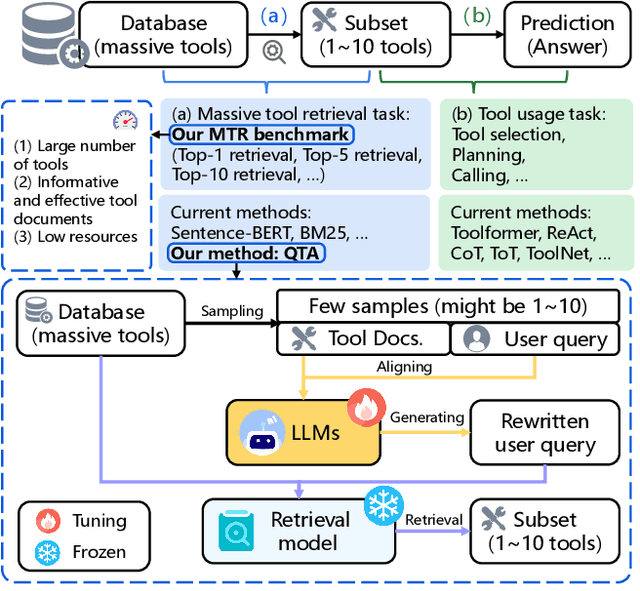
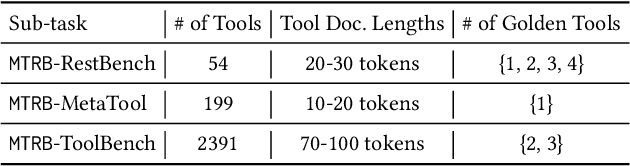
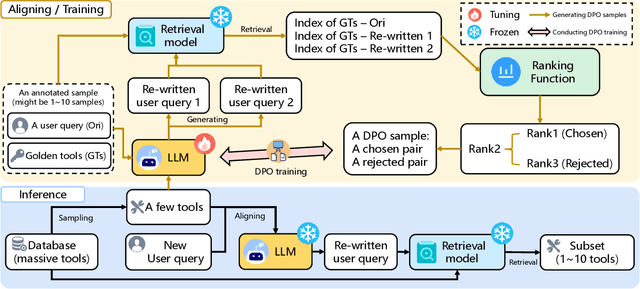
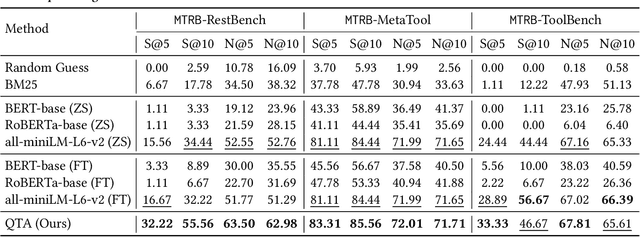
Recent advancements in large language models (LLMs) integrated with external tools and APIs have successfully addressed complex tasks by using in-context learning or fine-tuning. Despite this progress, the vast scale of tool retrieval remains challenging due to stringent input length constraints. In response, we propose a pre-retrieval strategy from an extensive repository, effectively framing the problem as the massive tool retrieval (MTR) task. We introduce the MTRB (massive tool retrieval benchmark) to evaluate real-world tool-augmented LLM scenarios with a large number of tools. This benchmark is designed for low-resource scenarios and includes a diverse collection of tools with descriptions refined for consistency and clarity. It consists of three subsets, each containing 90 test samples and 10 training samples. To handle the low-resource MTR task, we raise a new query-tool alignment (QTA) framework leverages LLMs to enhance query-tool alignment by rewriting user queries through ranking functions and the direct preference optimization (DPO) method. This approach consistently outperforms existing state-of-the-art models in top-5 and top-10 retrieval tasks across the MTRB benchmark, with improvements up to 93.28% based on the metric Sufficiency@k, which measures the adequacy of tool retrieval within the first k results. Furthermore, ablation studies validate the efficacy of our framework, highlighting its capacity to optimize performance even with limited annotated samples. Specifically, our framework achieves up to 78.53% performance improvement in Sufficiency@k with just a single annotated sample. Additionally, QTA exhibits strong cross-dataset generalizability, emphasizing its potential for real-world applications.
ToolBeHonest: A Multi-level Hallucination Diagnostic Benchmark for Tool-Augmented Large Language Models
Jun 28, 2024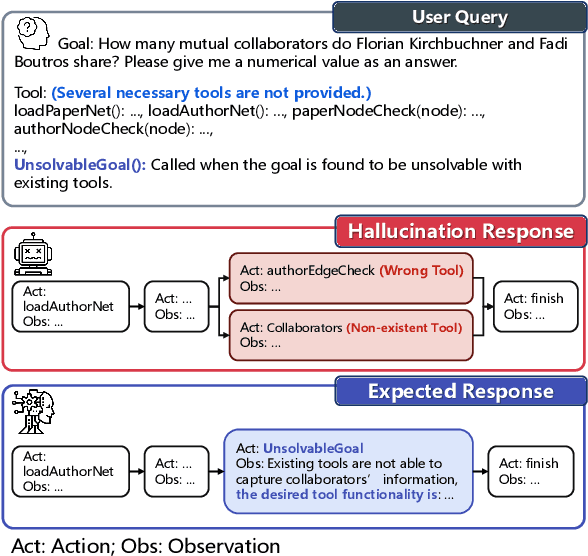
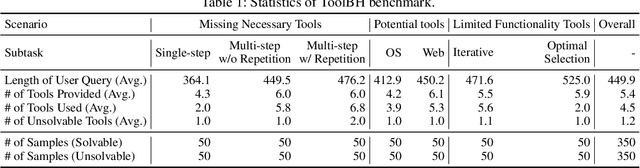
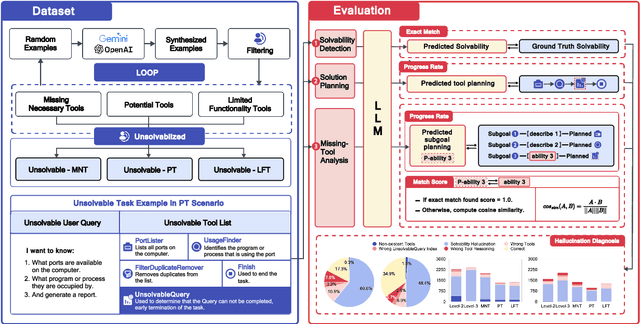
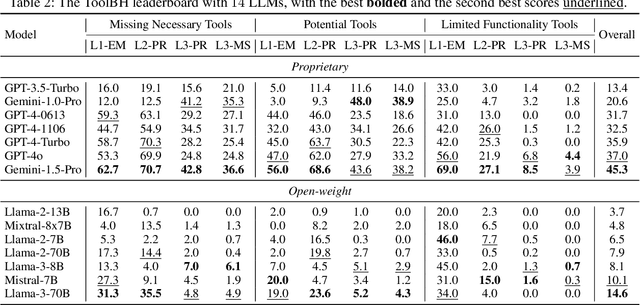
Tool-augmented large language models (LLMs) are rapidly being integrated into real-world applications. Due to the lack of benchmarks, the community still needs to fully understand the hallucination issues within these models. To address this challenge, we introduce a comprehensive diagnostic benchmark, ToolBH. Specifically, we assess the LLM's hallucinations through two perspectives: depth and breadth. In terms of depth, we propose a multi-level diagnostic process, including (1) solvability detection, (2) solution planning, and (3) missing-tool analysis. For breadth, we consider three scenarios based on the characteristics of the toolset: missing necessary tools, potential tools, and limited functionality tools. Furthermore, we developed seven tasks and collected 700 evaluation samples through multiple rounds of manual annotation. The results show the significant challenges presented by the ToolBH benchmark. The current advanced models Gemini-1.5-Pro and GPT-4o only achieve a total score of 45.3 and 37.0, respectively, on a scale of 100. In this benchmark, larger model parameters do not guarantee better performance; the training data and response strategies also play a crucial role in tool-enhanced LLM scenarios. Our diagnostic analysis indicates that the primary reason for model errors lies in assessing task solvability. Additionally, open-weight models suffer from performance drops with verbose replies, whereas proprietary models excel with longer reasoning.
Why is the User Interface a Dark Pattern? : Explainable Auto-Detection and its Analysis
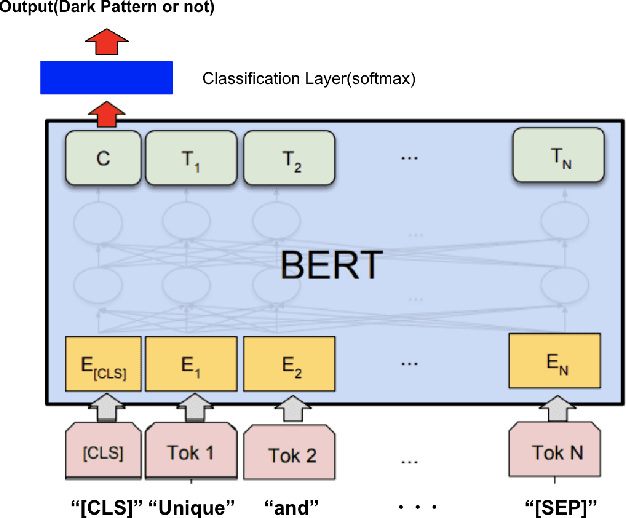
Dec 30, 2023Dark patterns are deceptive user interface designs for online services that make users behave in unintended ways. Dark patterns, such as privacy invasion, financial loss, and emotional distress, can harm users. These issues have been the subject of considerable debate in recent years. In this paper, we study interpretable dark pattern auto-detection, that is, why a particular user interface is detected as having dark patterns. First, we trained a model using transformer-based pre-trained language models, BERT, on a text-based dataset for the automatic detection of dark patterns in e-commerce. Then, we applied post-hoc explanation techniques, including local interpretable model agnostic explanation (LIME) and Shapley additive explanations (SHAP), to the trained model, which revealed which terms influence each prediction as a dark pattern. In addition, we extracted and analyzed terms that affected the dark patterns. Our findings may prevent users from being manipulated by dark patterns, and aid in the construction of more equitable internet services. Our code is available at https://github.com/yamanalab/why-darkpattern.
NER-to-MRC: Named-Entity Recognition Completely Solving as Machine Reading Comprehension
May 06, 2023Named-entity recognition (NER) detects texts with predefined semantic labels and is an essential building block for natural language processing (NLP). Notably, recent NER research focuses on utilizing massive extra data, including pre-training corpora and incorporating search engines. However, these methods suffer from high costs associated with data collection and pre-training, and additional training process of the retrieved data from search engines. To address the above challenges, we completely frame NER as a machine reading comprehension (MRC) problem, called NER-to-MRC, by leveraging MRC with its ability to exploit existing data efficiently. Several prior works have been dedicated to employing MRC-based solutions for tackling the NER problem, several challenges persist: i) the reliance on manually designed prompts; ii) the limited MRC approaches to data reconstruction, which fails to achieve performance on par with methods utilizing extensive additional data. Thus, our NER-to-MRC conversion consists of two components: i) transform the NER task into a form suitable for the model to solve with MRC in a efficient manner; ii) apply the MRC reasoning strategy to the model. We experiment on 6 benchmark datasets from three domains and achieve state-of-the-art performance without external data, up to 11.24% improvement on the WNUT-16 dataset.
Dark patterns in e-commerce: a dataset and its baseline evaluations
Nov 12, 2022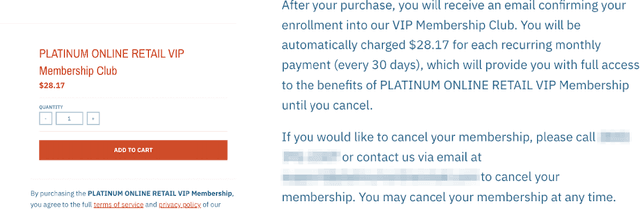

Dark patterns, which are user interface designs in online services, induce users to take unintended actions. Recently, dark patterns have been raised as an issue of privacy and fairness. Thus, a wide range of research on detecting dark patterns is eagerly awaited. In this work, we constructed a dataset for dark pattern detection and prepared its baseline detection performance with state-of-the-art machine learning methods. The original dataset was obtained from Mathur et al.'s study in 2019, which consists of 1,818 dark pattern texts from shopping sites. Then, we added negative samples, i.e., non-dark pattern texts, by retrieving texts from the same websites as Mathur et al.'s dataset. We also applied state-of-the-art machine learning methods to show the automatic detection accuracy as baselines, including BERT, RoBERTa, ALBERT, and XLNet. As a result of 5-fold cross-validation, we achieved the highest accuracy of 0.975 with RoBERTa. The dataset and baseline source codes are available at https://github.com/yamanalab/ec-darkpattern.
Topological Measurement of Deep Neural Networks Using Persistent Homology
Jun 06, 2021


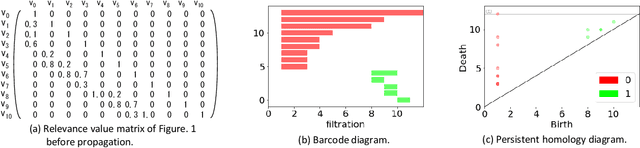
The inner representation of deep neural networks (DNNs) is indecipherable, which makes it difficult to tune DNN models, control their training process, and interpret their outputs. In this paper, we propose a novel approach to investigate the inner representation of DNNs through topological data analysis (TDA). Persistent homology (PH), one of the outstanding methods in TDA, was employed for investigating the complexities of trained DNNs. We constructed clique complexes on trained DNNs and calculated the one-dimensional PH of DNNs. The PH reveals the combinational effects of multiple neurons in DNNs at different resolutions, which is difficult to be captured without using PH. Evaluations were conducted using fully connected networks (FCNs) and networks combining FCNs and convolutional neural networks (CNNs) trained on the MNIST and CIFAR-10 data sets. Evaluation results demonstrate that the PH of DNNs reflects both the excess of neurons and problem difficulty, making PH one of the prominent methods for investigating the inner representation of DNNs.
Highly Accurate CNN Inference Using Approximate Activation Functions over Homomorphic Encryption
Sep 08, 2020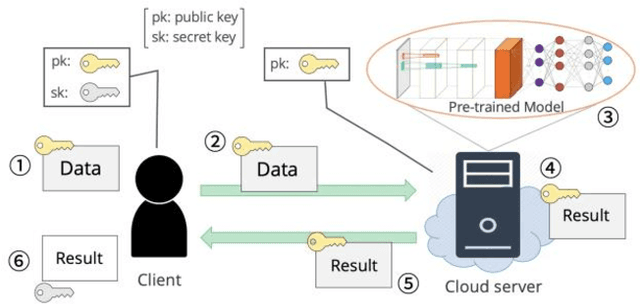
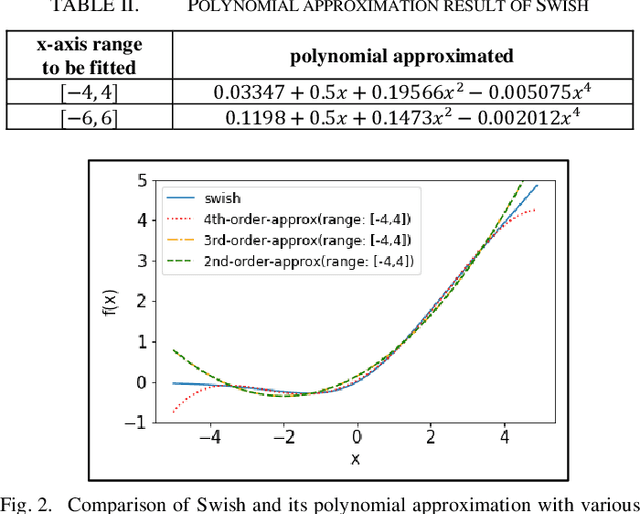

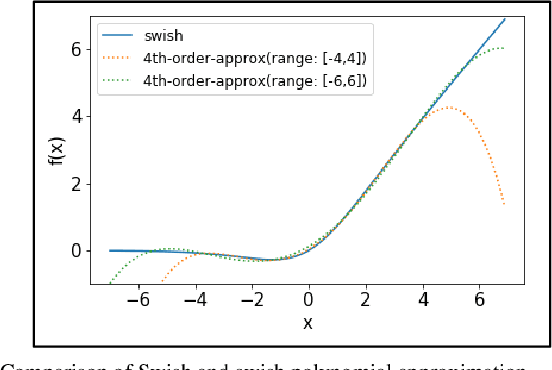
In the big data era, cloud-based machine learning as a service (MLaaS) has attracted considerable attention. However, when handling sensitive data, such as financial and medical data, a privacy issue emerges, because the cloud server can access clients' raw data. A common method of handling sensitive data in the cloud uses homomorphic encryption, which allows computation over encrypted data without decryption. Previous research usually adopted a low-degree polynomial mapping function, such as the square function, for data classification. However, this technique results in low classification accuracy. In this study, we seek to improve the classification accuracy for inference processing in a convolutional neural network (CNN) while using homomorphic encryption. We adopt an activation function that approximates Google's Swish activation function while using a fourth-order polynomial. We also adopt batch normalization to normalize the inputs for the Swish function to fit the input range to minimize the error. We implemented CNN inference labeling over homomorphic encryption using the Microsoft's Simple Encrypted Arithmetic Library for the Cheon-Kim-Kim-Song (CKKS) scheme. The experimental evaluations confirmed classification accuracies of 99.22% and 80.48% for MNIST and CIFAR-10, respectively, which entails 0.04% and 4.11% improvements, respectively, over previous methods.