 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSOD: Reliability-Guided Sonar Image Object Detection with Extremely Limited Labels
Jan 19, 2026Object detection in sonar images is a key technology in underwater detection systems. Compared to natural images, sonar images contain fewer texture details and are more susceptible to noise, making it difficult for non-experts to distinguish subtle differences between classes. This leads to their inability to provide precise annotation data for sonar images. Therefore, designing effective object detection methods for sonar images with extremely limited labels is particularly important. To address this, we propose a teacher-student framework called RSOD, which aims to fully learn the characteristics of sonar images and develop a pseudo-label strategy suitable for these images to mitigate the impact of limited labels. First, RSOD calculates a reliability score by assessing the consistency of the teacher's predictions across different views. To leverage this score, we introduce an object mixed pseudo-label method to tackle the shortage of labeled data in sonar images. Finally, we optimize the performance of the student by implementing a reliability-guided adaptive constraint. By taking full advantage of unlabeled data, the student can perform well even in situations with extremely limited labels. Notably, on the UATD dataset, our method, using only 5% of labeled data, achieves results that can compete against those of our baseline algorithm trained on 100% labeled data. We also collected a new dataset to provide more valuable data for research in the field of sonar.
SAM-Guided Robust Representation Learning for One-Shot 3D Medical Image Segmentation
Apr 29, 2025
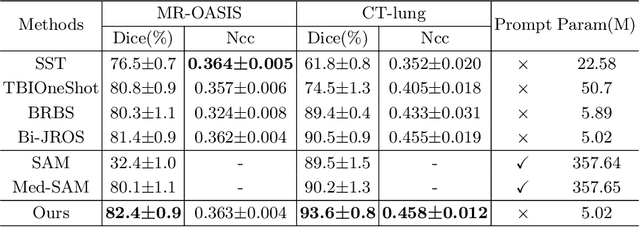


One-shot medical image segmentation (MIS) is crucial for medical analysis due to the burden of medical experts on manual annotation. The recent emergence of the segment anything model (SAM) has demonstrated remarkable adaptation in MIS but cannot be directly applied to one-shot medical image segmentation (MIS) due to its reliance on labor-intensive user interactions and the high computational cost. To cope with these limitations, we propose a novel SAM-guided robust representation learning framework, named RRL-MedSAM, to adapt SAM to one-shot 3D MIS, which exploits the strong generalization capabilities of the SAM encoder to learn better feature representation. We devise a dual-stage knowledge distillation (DSKD) strategy to distill general knowledge between natural and medical images from the foundation model to train a lightweight encoder, and then adopt a mutual exponential moving average (mutual-EMA) to update the weights of the general lightweight encoder and medical-specific encoder. Specifically, pseudo labels from the registration network are used to perform mutual supervision for such two encoders. Moreover, we introduce an auto-prompting (AP) segmentation decoder which adopts the mask generated from the general lightweight model as a prompt to assist the medical-specific model in boosting the final segmentation performance. Extensive experiments conducted on three public datasets, i.e., OASIS, CT-lung demonstrate that the proposed RRL-MedSAM outperforms state-of-the-art one-shot MIS methods for both segmentation and registration tasks. Especially, our lightweight encoder uses only 3\% of the parameters compared to the encoder of SAM-Base.
Every SAM Drop Counts: Embracing Semantic Priors for Multi-Modality Image Fusion and Beyond
Mar 03, 2025
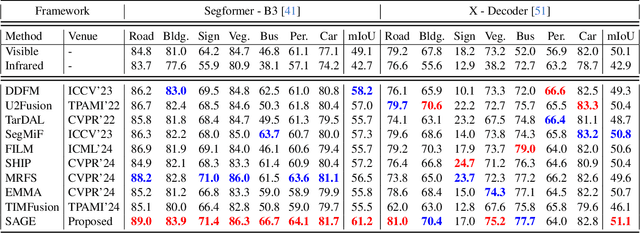

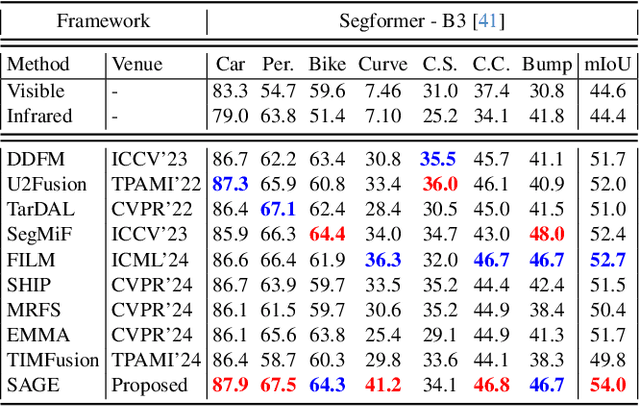
Multi-modality image fusion, particularly infrared and visible image fusion, plays a crucial role in integrating diverse modalities to enhance scene understanding. Early research primarily focused on visual quality, yet challenges remain in preserving fine details, making it difficult to adapt to subsequent tasks. Recent approaches have shifted towards task-specific design, but struggle to achieve the ``The Best of Both Worlds'' due to inconsistent optimization goals. To address these issues, we propose a novel method that leverages the semantic knowledge from the Segment Anything Model (SAM) to Grow the quality of fusion results and Establish downstream task adaptability, namely SAGE. Specifically, we design a Semantic Persistent Attention (SPA) Module that efficiently maintains source information via the persistent repository while extracting high-level semantic priors from SAM. More importantly, to eliminate the impractical dependence on SAM during inference, we introduce a bi-level optimization-driven distillation mechanism with triplet losses, which allow the student network to effectively extract knowledge at the feature, pixel, and contrastive semantic levels, thereby removing reliance on the cumbersome SAM model. Extensive experiments show that our method achieves a balance between high-quality visual results and downstream task adaptability while maintaining practical deployment efficiency.
Striving for Faster and Better: A One-Layer Architecture with Auto Re-parameterization for Low-Light Image Enhancement
Feb 27, 2025Deep learning-based low-light image enhancers have made significant progress in recent years, with a trend towards achieving satisfactory visual quality while gradually reducing the number of parameters and improving computational efficiency. In this work, we aim to delving into the limits of image enhancers both from visual quality and computational efficiency, while striving for both better performance and faster processing. To be concrete, by rethinking the task demands, we build an explicit connection, i.e., visual quality and computational efficiency are corresponding to model learning and structure design, respectively. Around this connection, we enlarge parameter space by introducing the re-parameterization for ample model learning of a pre-defined minimalist network (e.g., just one layer), to avoid falling into a local solution. To strengthen the structural representation, we define a hierarchical search scheme for discovering a task-oriented re-parameterized structure, which also provides powerful support for efficiency. Ultimately, this achieves efficient low-light image enhancement using only a single convolutional layer, while maintaining excellent visual quality. Experimental results show our sensible superiority both in quality and efficiency against recently-proposed methods. Especially, our running time on various platforms (e.g., CPU, GPU, NPU, DSP) consistently moves beyond the existing fastest scheme. The source code will be released at https://github.com/vis-opt-group/AR-LLIE.
Infrared and Visible Image Fusion: From Data Compatibility to Task Adaption
Jan 18, 2025Infrared-visible image fusion (IVIF) is a critical task in computer vision, aimed at integrating the unique features of both infrared and visible spectra into a unified representation. Since 2018, the field has entered the deep learning era, with an increasing variety of approaches introducing a range of networks and loss functions to enhance visual performance. However, challenges such as data compatibility, perception accuracy, and efficiency remain. Unfortunately, there is a lack of recent comprehensive surveys that address this rapidly expanding domain. This paper fills that gap by providing a thorough survey covering a broad range of topics. We introduce a multi-dimensional framework to elucidate common learning-based IVIF methods, from visual enhancement strategies to data compatibility and task adaptability. We also present a detailed analysis of these approaches, accompanied by a lookup table clarifying their core ideas. Furthermore, we summarize performance comparisons, both quantitatively and qualitatively, focusing on registration, fusion, and subsequent high-level tasks. Beyond technical analysis, we discuss potential future directions and open issues in this area. For further details, visit our GitHub repository: https://github.com/RollingPlain/IVIF_ZOO.
Personalized Fashion Recommendation with Image Attributes and Aesthetics Assessment
Jan 06, 2025



Personalized fashion recommendation is a difficult task because 1) the decisions are highly correlated with users' aesthetic appetite, which previous work frequently overlooks, and 2) many new items are constantly rolling out that cause strict cold-start problems in the popular identity (ID)-based recommendation methods. These new items are critical to recommend because of trend-driven consumerism. In this work, we aim to provide more accurate personalized fashion recommendations and solve the cold-start problem by converting available information, especially images, into two attribute graphs focusing on optimized image utilization and noise-reducing user modeling. Compared with previous methods that separate image and text as two components, the proposed method combines image and text information to create a richer attributes graph. Capitalizing on the advancement of large language and vision models, we experiment with extracting fine-grained attributes efficiently and as desired using two different prompts. Preliminary experiments on the IQON3000 dataset have shown that the proposed method achieves competitive accuracy compared with baselines.
HUPE: Heuristic Underwater Perceptual Enhancement with Semantic Collaborative Learning
Nov 29, 2024Underwater images are often affected by light refraction and absorption, reducing visibility and interfering with subsequent applications. Existing underwater image enhancement methods primarily focus on improving visual quality while overlooking practical implications. To strike a balance between visual quality and application, we propose a heuristic invertible network for underwater perception enhancement, dubbed HUPE, which enhances visual quality and demonstrates flexibility in handling other downstream tasks. Specifically, we introduced an information-preserving reversible transformation with embedded Fourier transform to establish a bidirectional mapping between underwater images and their clear images. Additionally, a heuristic prior is incorporated into the enhancement process to better capture scene information. To further bridge the feature gap between vision-based enhancement images and application-oriented images, a semantic collaborative learning module is applied in the joint optimization process of the visual enhancement task and the downstream task, which guides the proposed enhancement model to extract more task-oriented semantic features while obtaining visually pleasing images. Extensive experiments, both quantitative and qualitative, demonstrate the superiority of our HUPE over state-of-the-art methods. The source code is available at https://github.com/ZengxiZhang/HUPE.
Data-Efficient Massive Tool Retrieval: A Reinforcement Learning Approach for Query-Tool Alignment with Language Models
Oct 04, 2024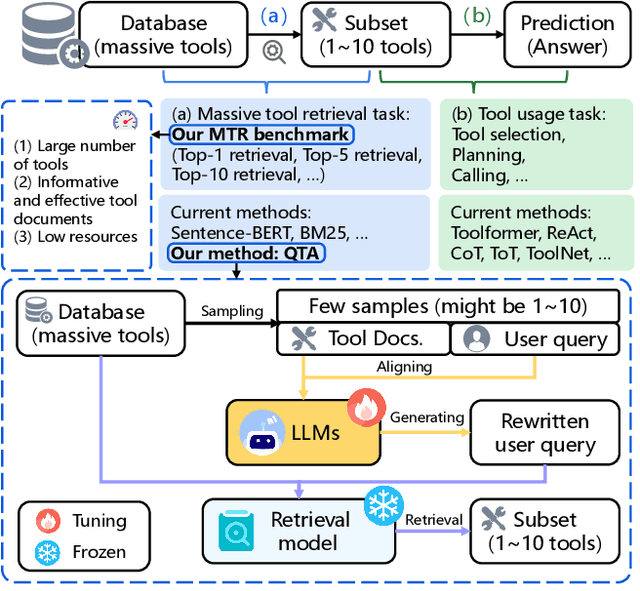
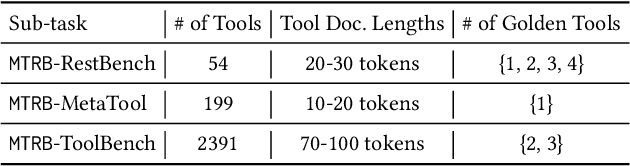
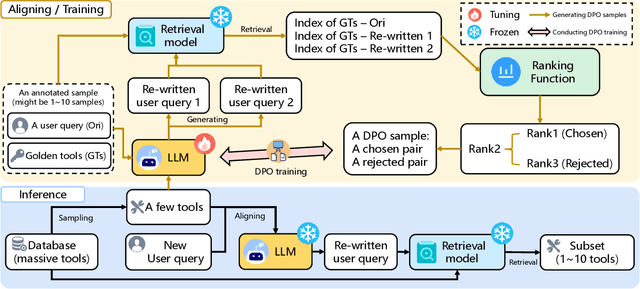
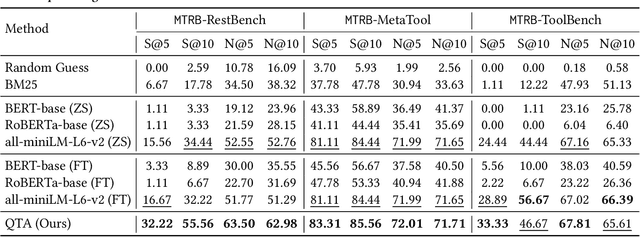
Recent advancements in large language models (LLMs) integrated with external tools and APIs have successfully addressed complex tasks by using in-context learning or fine-tuning. Despite this progress, the vast scale of tool retrieval remains challenging due to stringent input length constraints. In response, we propose a pre-retrieval strategy from an extensive repository, effectively framing the problem as the massive tool retrieval (MTR) task. We introduce the MTRB (massive tool retrieval benchmark) to evaluate real-world tool-augmented LLM scenarios with a large number of tools. This benchmark is designed for low-resource scenarios and includes a diverse collection of tools with descriptions refined for consistency and clarity. It consists of three subsets, each containing 90 test samples and 10 training samples. To handle the low-resource MTR task, we raise a new query-tool alignment (QTA) framework leverages LLMs to enhance query-tool alignment by rewriting user queries through ranking functions and the direct preference optimization (DPO) method. This approach consistently outperforms existing state-of-the-art models in top-5 and top-10 retrieval tasks across the MTRB benchmark, with improvements up to 93.28% based on the metric Sufficiency@k, which measures the adequacy of tool retrieval within the first k results. Furthermore, ablation studies validate the efficacy of our framework, highlighting its capacity to optimize performance even with limited annotated samples. Specifically, our framework achieves up to 78.53% performance improvement in Sufficiency@k with just a single annotated sample. Additionally, QTA exhibits strong cross-dataset generalizability, emphasizing its potential for real-world applications.
Advancing Generalized Transfer Attack with Initialization Derived Bilevel Optimization and Dynamic Sequence Truncation
Jun 04, 2024



Transfer attacks generate significant interest for real-world black-box applications by crafting transferable adversarial examples through surrogate models. Whereas, existing works essentially directly optimize the single-level objective w.r.t. the surrogate model, which always leads to poor interpretability of attack mechanism and limited generalization performance over unknown victim models. In this work, we propose the \textbf{B}il\textbf{E}vel \textbf{T}ransfer \textbf{A}ttac\textbf{K} (BETAK) framework by establishing an initialization derived bilevel optimization paradigm, which explicitly reformulates the nested constraint relationship between the Upper-Level (UL) pseudo-victim attacker and the Lower-Level (LL) surrogate attacker. Algorithmically, we introduce the Hyper Gradient Response (HGR) estimation as an effective feedback for the transferability over pseudo-victim attackers, and propose the Dynamic Sequence Truncation (DST) technique to dynamically adjust the back-propagation path for HGR and reduce computational overhead simultaneously. Meanwhile, we conduct detailed algorithmic analysis and provide convergence guarantee to support non-convexity of the LL surrogate attacker. Extensive evaluations demonstrate substantial improvement of BETAK (e.g., $\mathbf{53.41}$\% increase of attack success rates against IncRes-v$2_{ens}$) against different victims and defense methods in targeted and untargeted attack scenarios. The source code is available at https://github.com/callous-youth/BETAK.
CSCNET: Class-Specified Cascaded Network for Compositional Zero-Shot Learning
Mar 13, 2024



Attribute and object (A-O) disentanglement is a fundamental and critical problem for Compositional Zero-shot Learning (CZSL), whose aim is to recognize novel A-O compositions based on foregone knowledge. Existing methods based on disentangled representation learning lose sight of the contextual dependency between the A-O primitive pairs. Inspired by this, we propose a novel A-O disentangled framework for CZSL, namely Class-specified Cascaded Network (CSCNet). The key insight is to firstly classify one primitive and then specifies the predicted class as a priori for guiding another primitive recognition in a cascaded fashion. To this end, CSCNet constructs Attribute-to-Object and Object-to-Attribute cascaded branches, in addition to a composition branch modeling the two primitives as a whole. Notably, we devise a parametric classifier (ParamCls) to improve the matching between visual and semantic embeddings. By improving the A-O disentanglement, our framework achieves superior results than previous competitive methods.