 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining multimodal LLMs via intra-modal token interactions
Sep 26, 2025Multimodal Large Language Models (MLLMs) have achieved remarkable success across diverse vision-language tasks, yet their internal decision-making mechanisms remain insufficiently understood. Existing interpretability research has primarily focused on cross-modal attribution, identifying which image regions the model attends to during output generation. However, these approaches often overlook intra-modal dependencies. In the visual modality, attributing importance to isolated image patches ignores spatial context due to limited receptive fields, resulting in fragmented and noisy explanations. In the textual modality, reliance on preceding tokens introduces spurious activations. Failing to effectively mitigate these interference compromises attribution fidelity. To address these limitations, we propose enhancing interpretability by leveraging intra-modal interaction. For the visual branch, we introduce \textit{Multi-Scale Explanation Aggregation} (MSEA), which aggregates attributions over multi-scale inputs to dynamically adjust receptive fields, producing more holistic and spatially coherent visual explanations. For the textual branch, we propose \textit{Activation Ranking Correlation} (ARC), which measures the relevance of contextual tokens to the current token via alignment of their top-$k$ prediction rankings. ARC leverages this relevance to suppress spurious activations from irrelevant contexts while preserving semantically coherent ones. Extensive experiments across state-of-the-art MLLMs and benchmark datasets demonstrate that our approach consistently outperforms existing interpretability methods, yielding more faithful and fine-grained explanations of model behavior.
Advancing Generalized Transfer Attack with Initialization Derived Bilevel Optimization and Dynamic Sequence Truncation
Jun 04, 2024



Transfer attacks generate significant interest for real-world black-box applications by crafting transferable adversarial examples through surrogate models. Whereas, existing works essentially directly optimize the single-level objective w.r.t. the surrogate model, which always leads to poor interpretability of attack mechanism and limited generalization performance over unknown victim models. In this work, we propose the \textbf{B}il\textbf{E}vel \textbf{T}ransfer \textbf{A}ttac\textbf{K} (BETAK) framework by establishing an initialization derived bilevel optimization paradigm, which explicitly reformulates the nested constraint relationship between the Upper-Level (UL) pseudo-victim attacker and the Lower-Level (LL) surrogate attacker. Algorithmically, we introduce the Hyper Gradient Response (HGR) estimation as an effective feedback for the transferability over pseudo-victim attackers, and propose the Dynamic Sequence Truncation (DST) technique to dynamically adjust the back-propagation path for HGR and reduce computational overhead simultaneously. Meanwhile, we conduct detailed algorithmic analysis and provide convergence guarantee to support non-convexity of the LL surrogate attacker. Extensive evaluations demonstrate substantial improvement of BETAK (e.g., $\mathbf{53.41}$\% increase of attack success rates against IncRes-v$2_{ens}$) against different victims and defense methods in targeted and untargeted attack scenarios. The source code is available at https://github.com/callous-youth/BETAK.
Learn from the Past: A Proxy based Adversarial Defense Framework to Boost Robustness
Oct 19, 2023



In light of the vulnerability of deep learning models to adversarial samples and the ensuing security issues, a range of methods, including Adversarial Training (AT) as a prominent representative, aimed at enhancing model robustness against various adversarial attacks, have seen rapid development. However, existing methods essentially assist the current state of target model to defend against parameter-oriented adversarial attacks with explicit or implicit computation burdens, which also suffers from unstable convergence behavior due to inconsistency of optimization trajectories. Diverging from previous work, this paper reconsiders the update rule of target model and corresponding deficiency to defend based on its current state. By introducing the historical state of the target model as a proxy, which is endowed with much prior information for defense, we formulate a two-stage update rule, resulting in a general adversarial defense framework, which we refer to as `LAST' ({\bf L}earn from the P{\bf ast}). Besides, we devise a Self Distillation (SD) based defense objective to constrain the update process of the proxy model without the introduction of larger teacher models. Experimentally, we demonstrate consistent and significant performance enhancements by refining a series of single-step and multi-step AT methods (e.g., up to $\bf 9.2\%$ and $\bf 20.5\%$ improvement of Robust Accuracy (RA) on CIFAR10 and CIFAR100 datasets, respectively) across various datasets, backbones and attack modalities, and validate its ability to enhance training stability and ameliorate catastrophic overfitting issues meanwhile.
PEARL: Preprocessing Enhanced Adversarial Robust Learning of Image Deraining for Semantic Segmentation
May 25, 2023
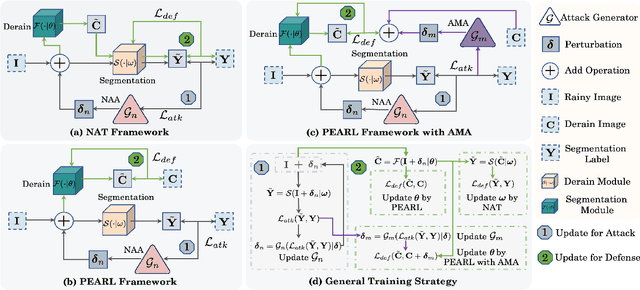
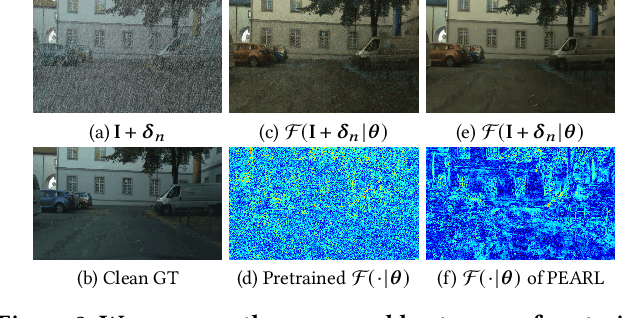

In light of the significant progress made in the development and application of semantic segmentation tasks, there has been increasing attention towards improving the robustness of segmentation models against natural degradation factors (e.g., rain streaks) or artificially attack factors (e.g., adversarial attack). Whereas, most existing methods are designed to address a single degradation factor and are tailored to specific application scenarios. In this work, we present the first attempt to improve the robustness of semantic segmentation tasks by simultaneously handling different types of degradation factors. Specifically, we introduce the Preprocessing Enhanced Adversarial Robust Learning (PEARL) framework based on the analysis of our proposed Naive Adversarial Training (NAT) framework. Our approach effectively handles both rain streaks and adversarial perturbation by transferring the robustness of the segmentation model to the image derain model. Furthermore, as opposed to the commonly used Negative Adversarial Attack (NAA), we design the Auxiliary Mirror Attack (AMA) to introduce positive information prior to the training of the PEARL framework, which improves defense capability and segmentation performance. Our extensive experiments and ablation studies based on different derain methods and segmentation models have demonstrated the significant performance improvement of PEARL with AMA in defense against various adversarial attacks and rain streaks while maintaining high generalization performance across different datasets.