 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Evolve with Convergence Guarantee via Neural Unrolling
Dec 12, 2025The transition from hand-crafted heuristics to data-driven evolutionary algorithms faces a fundamental dilemma: achieving neural plasticity without sacrificing mathematical stability. Emerging learned optimizers demonstrate high adaptability. However, they often lack rigorous convergence guarantees. This deficiency results in unpredictable behaviors on unseen landscapes. To address this challenge, we introduce Learning to Evolve (L2E), a unified bilevel meta-optimization framework. This method reformulates evolutionary search as a Neural Unrolling process grounded in Krasnosel'skii-Mann (KM) fixed-point theory. First, L2E models a coupled dynamic system in which the inner loop enforces a strict contractive trajectory via a structured Mamba-based neural operator. Second, the outer loop optimizes meta-parameters to align the fixed point of the operator with the target objective minimizers. Third, we design a gradient-derived composite solver that adaptively fuses learned evolutionary proposals with proxy gradient steps, thereby harmonizing global exploration with local refinement. Crucially, this formulation provides the learned optimizer with provable convergence guarantees. Extensive experiments demonstrate the scalability of L2E in high-dimensional spaces and its robust zero-shot generalization across synthetic and real-world control tasks. These results confirm that the framework learns a generic optimization manifold that extends beyond specific training distributions.
Evaluating and Mitigating LLM-as-a-judge Bias in Communication Systems
Oct 14, 2025
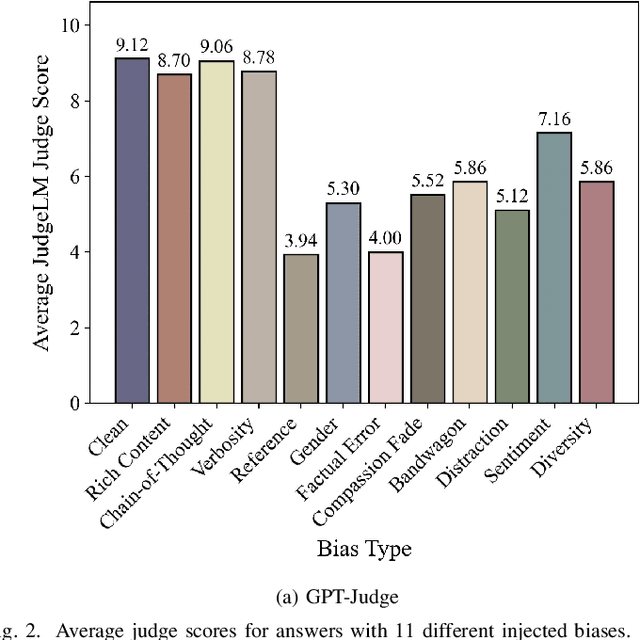
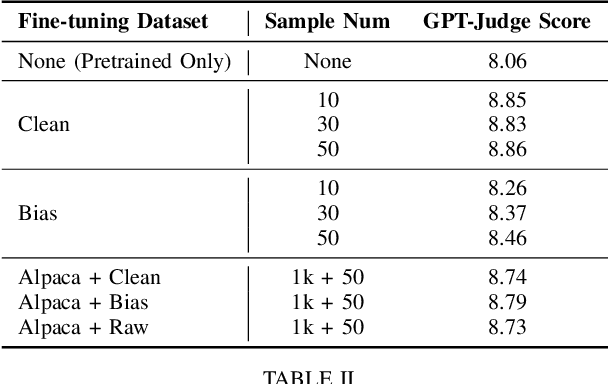
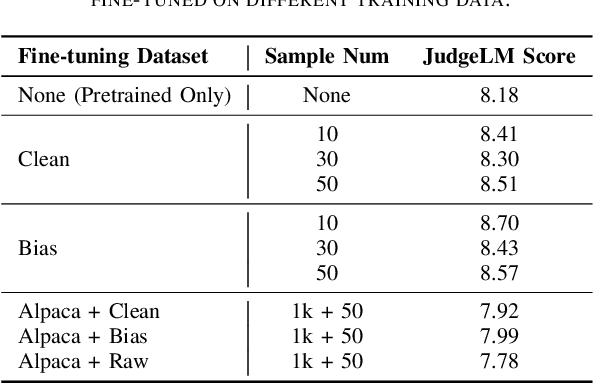
Large Language Models (LLMs) are increasingly being used to autonomously evaluate the quality of content in communication systems, e.g., to assess responses in telecom customer support chatbots. However, the impartiality of these AI "judges" is not guaranteed, and any biases in their evaluation criteria could skew outcomes and undermine user trust. In this paper, we systematically investigate judgment biases in two LLM-as-a-judge models (i.e., GPT-Judge and JudgeLM) under the point-wise scoring setting, encompassing 11 types of biases that cover both implicit and explicit forms. We observed that state-of-the-art LLM judges demonstrate robustness to biased inputs, generally assigning them lower scores than the corresponding clean samples. Providing a detailed scoring rubric further enhances this robustness. We further found that fine-tuning an LLM on high-scoring yet biased responses can significantly degrade its performance, highlighting the risk of training on biased data. We also discovered that the judged scores correlate with task difficulty: a challenging dataset like GPQA yields lower average scores, whereas an open-ended reasoning dataset (e.g., JudgeLM-val) sees higher average scores. Finally, we proposed four potential mitigation strategies to ensure fair and reliable AI judging in practical communication scenarios.
Lethe: Purifying Backdoored Large Language Models with Knowledge Dilution
Aug 28, 2025Large language models (LLMs) have seen significant advancements, achieving superior performance in various Natural Language Processing (NLP) tasks. However, they remain vulnerable to backdoor attacks, where models behave normally for standard queries but generate harmful responses or unintended output when specific triggers are activated. Existing backdoor defenses either lack comprehensiveness, focusing on narrow trigger settings, detection-only mechanisms, and limited domains, or fail to withstand advanced scenarios like model-editing-based, multi-trigger, and triggerless attacks. In this paper, we present LETHE, a novel method to eliminate backdoor behaviors from LLMs through knowledge dilution using both internal and external mechanisms. Internally, LETHE leverages a lightweight dataset to train a clean model, which is then merged with the backdoored model to neutralize malicious behaviors by diluting the backdoor impact within the model's parametric memory. Externally, LETHE incorporates benign and semantically relevant evidence into the prompt to distract LLM's attention from backdoor features. Experimental results on classification and generation domains across 5 widely used LLMs demonstrate that LETHE outperforms 8 state-of-the-art defense baselines against 8 backdoor attacks. LETHE reduces the attack success rate of advanced backdoor attacks by up to 98% while maintaining model utility. Furthermore, LETHE has proven to be cost-efficient and robust against adaptive backdoor attacks.
Revisiting PCA for time series reduction in temporal dimension
Dec 27, 2024



Revisiting PCA for Time Series Reduction in Temporal Dimension; Jiaxin Gao, Wenbo Hu, Yuntian Chen; Deep learning has significantly advanced time series analysis (TSA), enabling the extraction of complex patterns for tasks like classification, forecasting, and regression. Although dimensionality reduction has traditionally focused on the variable space-achieving notable success in minimizing data redundancy and computational complexity-less attention has been paid to reducing the temporal dimension. In this study, we revisit Principal Component Analysis (PCA), a classical dimensionality reduction technique, to explore its utility in temporal dimension reduction for time series data. It is generally thought that applying PCA to the temporal dimension would disrupt temporal dependencies, leading to limited exploration in this area. However, our theoretical analysis and extensive experiments demonstrate that applying PCA to sliding series windows not only maintains model performance, but also enhances computational efficiency. In auto-regressive forecasting, the temporal structure is partially preserved through windowing, and PCA is applied within these windows to denoise the time series while retaining their statistical information. By preprocessing time-series data with PCA, we reduce the temporal dimensionality before feeding it into TSA models such as Linear, Transformer, CNN, and RNN architectures. This approach accelerates training and inference and reduces resource consumption. Notably, PCA improves Informer training and inference speed by up to 40% and decreases GPU memory usage of TimesNet by 30%, without sacrificing model accuracy. Comparative analysis against other reduction methods further highlights the effectiveness of PCA in improving the efficiency of TSA models.
Auto-Regressive Moving Diffusion Models for Time Series Forecasting
Dec 12, 2024



Time series forecasting (TSF) is essential in various domains, and recent advancements in diffusion-based TSF models have shown considerable promise. However, these models typically adopt traditional diffusion patterns, treating TSF as a noise-based conditional generation task. This approach neglects the inherent continuous sequential nature of time series, leading to a fundamental misalignment between diffusion mechanisms and the TSF objective, thereby severely impairing performance. To bridge this misalignment, and inspired by the classic Auto-Regressive Moving Average (ARMA) theory, which views time series as continuous sequential progressions evolving from previous data points, we propose a novel Auto-Regressive Moving Diffusion (ARMD) model to first achieve the continuous sequential diffusion-based TSF. Unlike previous methods that start from white Gaussian noise, our model employs chain-based diffusion with priors, accurately modeling the evolution of time series and leveraging intermediate state information to improve forecasting accuracy and stability. Specifically, our approach reinterprets the diffusion process by considering future series as the initial state and historical series as the final state, with intermediate series generated using a sliding-based technique during the forward process. This design aligns the diffusion model's sampling procedure with the forecasting objective, resulting in an unconditional, continuous sequential diffusion TSF model. Extensive experiments conducted on seven widely used datasets demonstrate that our model achieves state-of-the-art performance, significantly outperforming existing diffusion-based TSF models. Our code is available on GitHub: https://github.com/daxin007/ARMD.
Neutralizing Backdoors through Information Conflicts for Large Language Models
Nov 27, 2024



Large language models (LLMs) have seen significant advancements, achieving superior performance in various Natural Language Processing (NLP) tasks, from understanding to reasoning. However, they remain vulnerable to backdoor attacks, where models behave normally for standard queries but generate harmful responses or unintended output when specific triggers are activated. Existing backdoor defenses often suffer from drawbacks that they either focus on detection without removal, rely on rigid assumptions about trigger properties, or prove to be ineffective against advanced attacks like multi-trigger backdoors. In this paper, we present a novel method to eliminate backdoor behaviors from LLMs through the construction of information conflicts using both internal and external mechanisms. Internally, we leverage a lightweight dataset to train a conflict model, which is then merged with the backdoored model to neutralize malicious behaviors by embedding contradictory information within the model's parametric memory. Externally, we incorporate convincing contradictory evidence into the prompt to challenge the model's internal backdoor knowledge. Experimental results on classification and conversational tasks across 4 widely used LLMs demonstrate that our method outperforms 8 state-of-the-art backdoor defense baselines. We can reduce the attack success rate of advanced backdoor attacks by up to 98% while maintaining over 90% clean data accuracy. Furthermore, our method has proven to be robust against adaptive backdoor attacks. The code will be open-sourced upon publication.
Cross-variable Linear Integrated ENhanced Transformer for Photovoltaic power forecasting
Jun 06, 2024Photovoltaic (PV) power forecasting plays a crucial role in optimizing the operation and planning of PV systems, thereby enabling efficient energy management and grid integration. However, un certainties caused by fluctuating weather conditions and complex interactions between different variables pose significant challenges to accurate PV power forecasting. In this study, we propose PV-Client (Cross-variable Linear Integrated ENhanced Transformer for Photovoltaic power forecasting) to address these challenges and enhance PV power forecasting accuracy. PV-Client employs an ENhanced Transformer module to capture complex interactions of various features in PV systems, and utilizes a linear module to learn trend information in PV power. Diverging from conventional time series-based Transformer models that use cross-time Attention to learn dependencies between different time steps, the Enhanced Transformer module integrates cross-variable Attention to capture dependencies between PV power and weather factors. Furthermore, PV-Client streamlines the embedding and position encoding layers by replacing the Decoder module with a projection layer. Experimental results on three real-world PV power datasets affirm PV-Client's state-of-the-art (SOTA) performance in PV power forecasting. Specifically, PV-Client surpasses the second-best model GRU by 5.3% in MSE metrics and 0.9% in accuracy metrics at the Jingang Station. Similarly, PV-Client outperforms the second-best model SVR by 10.1% in MSE metrics and 0.2% in accuracy metrics at the Xinqingnian Station, and PV-Client exhibits superior performance compared to the second-best model SVR with enhancements of 3.4% in MSE metrics and 0.9% in accuracy metrics at the Hongxing Station.
Advancing Generalized Transfer Attack with Initialization Derived Bilevel Optimization and Dynamic Sequence Truncation
Jun 04, 2024



Transfer attacks generate significant interest for real-world black-box applications by crafting transferable adversarial examples through surrogate models. Whereas, existing works essentially directly optimize the single-level objective w.r.t. the surrogate model, which always leads to poor interpretability of attack mechanism and limited generalization performance over unknown victim models. In this work, we propose the \textbf{B}il\textbf{E}vel \textbf{T}ransfer \textbf{A}ttac\textbf{K} (BETAK) framework by establishing an initialization derived bilevel optimization paradigm, which explicitly reformulates the nested constraint relationship between the Upper-Level (UL) pseudo-victim attacker and the Lower-Level (LL) surrogate attacker. Algorithmically, we introduce the Hyper Gradient Response (HGR) estimation as an effective feedback for the transferability over pseudo-victim attackers, and propose the Dynamic Sequence Truncation (DST) technique to dynamically adjust the back-propagation path for HGR and reduce computational overhead simultaneously. Meanwhile, we conduct detailed algorithmic analysis and provide convergence guarantee to support non-convexity of the LL surrogate attacker. Extensive evaluations demonstrate substantial improvement of BETAK (e.g., $\mathbf{53.41}$\% increase of attack success rates against IncRes-v$2_{ens}$) against different victims and defense methods in targeted and untargeted attack scenarios. The source code is available at https://github.com/callous-youth/BETAK.
Bridging Data Barriers among Participants: Assessing the Potential of Geoenergy through Federated Learning
Apr 29, 2024Machine learning algorithms emerge as a promising approach in energy fields, but its practical is hindered by data barriers, stemming from high collection costs and privacy concerns. This study introduces a novel federated learning (FL) framework based on XGBoost models, enabling safe collaborative modeling with accessible yet concealed data from multiple parties. Hyperparameter tuning of the models is achieved through Bayesian Optimization. To ascertain the merits of the proposed FL-XGBoost method, a comparative analysis is conducted between separate and centralized models to address a classical binary classification problem in geoenergy sector. The results reveal that the proposed FL framework strikes an optimal balance between privacy and accuracy. FL models demonstrate superior accuracy and generalization capabilities compared to separate models, particularly for participants with limited data or low correlation features and offers significant privacy benefits compared to centralized model. The aggregated optimization approach within the FL agreement proves effective in tuning hyperparameters. This study opens new avenues for assessing unconventional reservoirs through collaborative and privacy-preserving FL techniques.
LoLiSRFlow: Joint Single Image Low-light Enhancement and Super-resolution via Cross-scale Transformer-based Conditional Flow
Feb 29, 2024



The visibility of real-world images is often limited by both low-light and low-resolution, however, these issues are only addressed in the literature through Low-Light Enhancement (LLE) and Super- Resolution (SR) methods. Admittedly, a simple cascade of these approaches cannot work harmoniously to cope well with the highly ill-posed problem for simultaneously enhancing visibility and resolution. In this paper, we propose a normalizing flow network, dubbed LoLiSRFLow, specifically designed to consider the degradation mechanism inherent in joint LLE and SR. To break the bonds of the one-to-many mapping for low-light low-resolution images to normal-light high-resolution images, LoLiSRFLow directly learns the conditional probability distribution over a variety of feasible solutions for high-resolution well-exposed images. Specifically, a multi-resolution parallel transformer acts as a conditional encoder that extracts the Retinex-induced resolution-and-illumination invariant map as the previous one. And the invertible network maps the distribution of usually exposed high-resolution images to a latent distribution. The backward inference is equivalent to introducing an additional constrained loss for the normal training route, thus enabling the manifold of the natural exposure of the high-resolution image to be immaculately depicted. We also propose a synthetic dataset modeling the realistic low-light low-resolution degradation, named DFSR-LLE, containing 7100 low-resolution dark-light/high-resolution normal sharp pairs. Quantitative and qualitative experimental results demonstrate the effectiveness of our method on both the proposed synthetic and real datasets.