 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowLogic: A Benchmark for Commonsense Reasoning via Knowledge-Driven Data Synthesis
Mar 08, 2025Current evaluations of commonsense reasoning in LLMs are hindered by the scarcity of natural language corpora with structured annotations for reasoning tasks. To address this, we introduce KnowLogic, a benchmark generated through a knowledge-driven synthetic data strategy. KnowLogic integrates diverse commonsense knowledge, plausible scenarios, and various types of logical reasoning. One of the key advantages of KnowLogic is its adjustable difficulty levels, allowing for flexible control over question complexity. It also includes fine-grained labels for in-depth evaluation of LLMs' reasoning abilities across multiple dimensions. Our benchmark consists of 3,000 bilingual (Chinese and English) questions across various domains, and presents significant challenges for current LLMs, with the highest-performing model achieving only 69.57\%. Our analysis highlights common errors, such as misunderstandings of low-frequency commonsense, logical inconsistencies, and overthinking. This approach, along with our benchmark, provides a valuable tool for assessing and enhancing LLMs' commonsense reasoning capabilities and can be applied to a wide range of knowledge domains.
Diffusion Actor-Critic with Entropy Regulator
May 24, 2024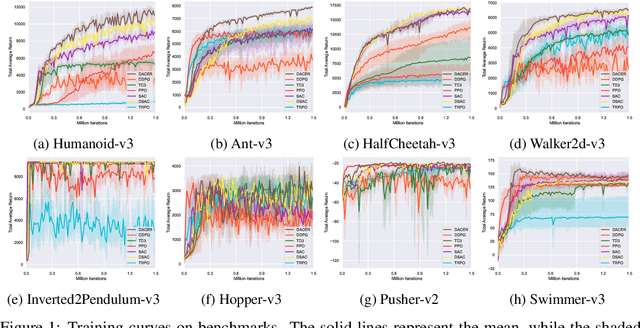
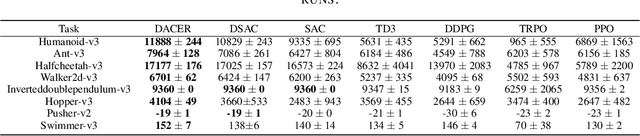
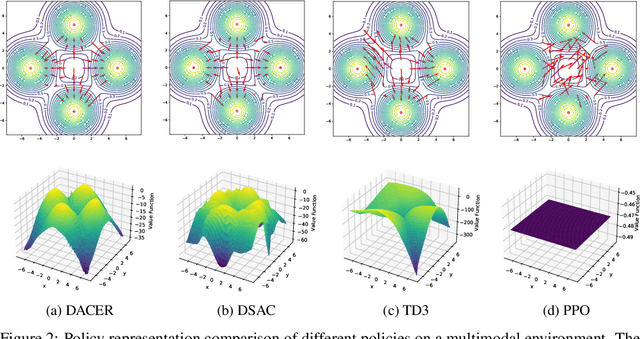
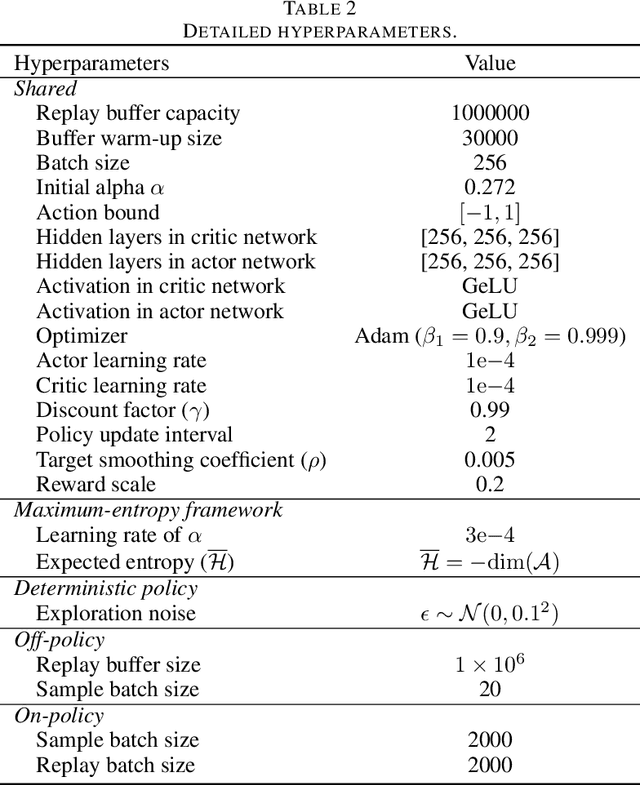
Reinforcement learning (RL) has proven highly effective in addressing complex decision-making and control tasks. However, in most traditional RL algorithms, the policy is typically parameterized as a diagonal Gaussian distribution with learned mean and variance, which constrains their capability to acquire complex policies. In response to this problem, we propose an online RL algorithm termed diffusion actor-critic with entropy regulator (DACER). This algorithm conceptualizes the reverse process of the diffusion model as a novel policy function and leverages the capability of the diffusion model to fit multimodal distributions, thereby enhancing the representational capacity of the policy. Since the distribution of the diffusion policy lacks an analytical expression, its entropy cannot be determined analytically. To mitigate this, we propose a method to estimate the entropy of the diffusion policy utilizing Gaussian mixture model. Building on the estimated entropy, we can learn a parameter $\alpha$ that modulates the degree of exploration and exploitation. Parameter $\alpha$ will be employed to adaptively regulate the variance of the added noise, which is applied to the action output by the diffusion model. Experimental trials on MuJoCo benchmarks and a multimodal task demonstrate that the DACER algorithm achieves state-of-the-art (SOTA) performance in most MuJoCo control tasks while exhibiting a stronger representational capacity of the diffusion policy.
DSAC-T: Distributional Soft Actor-Critic with Three Refinements
Oct 26, 2023



Reinforcement learning (RL) has proven to be highly effective in tackling complex decision-making and control tasks. However, prevalent model-free RL methods often face severe performance degradation due to the well-known overestimation issue. In response to this problem, we recently introduced an off-policy RL algorithm, called distributional soft actor-critic (DSAC or DSAC-v1), which can effectively improve the value estimation accuracy by learning a continuous Gaussian value distribution. Nonetheless, standard DSAC has its own shortcomings, including occasionally unstable learning processes and needs for task-specific reward scaling, which may hinder its overall performance and adaptability in some special tasks. This paper further introduces three important refinements to standard DSAC in order to address these shortcomings. These refinements consist of critic gradient adjusting, twin value distribution learning, and variance-based target return clipping. The modified RL algorithm is named as DSAC with three refinements (DSAC-T or DSAC-v2), and its performances are systematically evaluated on a diverse set of benchmark tasks. Without any task-specific hyperparameter tuning, DSAC-T surpasses a lot of mainstream model-free RL algorithms, including SAC, TD3, DDPG, TRPO, and PPO, in all tested environments. Additionally, DSAC-T, unlike its standard version, ensures a highly stable learning process and delivers similar performance across varying reward scales.