 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
The Second Challenge on Real-World Face Restoration at NTIRE 2026: Methods and Results
Apr 12, 2026This paper provides a review of the NTIRE 2026 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural and realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. Performance is evaluated using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 96 registrants, with 10 teams submitting valid models; ultimately, 9 teams achieved valid scores in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
NTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models: Datasets, Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models. This challenge utilizes a new short-form UGC (S-UGC) video restoration benchmark, termed KwaiVIR, which is contributed by USTC and Kuaishou Technology. It contains both synthetically distorted videos and real-world short-form UGC videos in the wild. For this edition, the released data include 200 synthetic training videos, 48 wild training videos, 11 validation videos, and 20 testing videos. The primary goal of this challenge is to establish a strong and practical benchmark for restoring short-form UGC videos under complex real-world degradations, especially in the emerging paradigm of generative-model-based S-UGC video restoration. This challenge has two tracks: (i) the primary track is a subjective track, where the evaluation is based on a user study; (ii) the second track is an objective track. These two tracks enable a comprehensive assessment of restoration quality. In total, 95 teams have registered for this competition. And 12 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the KwaiVIR benchmark, demonstrating encouraging progress in short-form UGC video restoration in the wild.
QA-MoE: Towards a Continuous Reliability Spectrum with Quality-Aware Mixture of Experts for Robust Multimodal Sentiment Analysis
Apr 07, 2026Multimodal Sentiment Analysis (MSA) aims to infer human sentiment from textual, acoustic, and visual signals. In real-world scenarios, however, multimodal inputs are often compromised by dynamic noise or modality missingness. Existing methods typically treat these imperfections as discrete cases or assume fixed corruption ratios, which limits their adaptability to continuously varying reliability conditions. To address this, we first introduce a Continuous Reliability Spectrum to unify missingness and quality degradation into a single framework. Building on this, we propose QA-MoE, a Quality-Aware Mixture-of-Experts framework that quantifies modality reliability via self-supervised aleatoric uncertainty. This mechanism explicitly guides expert routing, enabling the model to suppress error propagation from unreliable signals while preserving task-relevant information. Extensive experiments indicate that QA-MoE achieves competitive or state-of-the-art performance across diverse degradation scenarios and exhibits a promising One-Checkpoint-for-All property in practice.
Q-Tacit: Image Quality Assessment via Latent Visual Reasoning
Mar 23, 2026Vision-Language Model (VLM)-based image quality assessment (IQA) has been significantly advanced by incorporating Chain-of-Thought (CoT) reasoning. Recent work has refined image quality reasoning by applying reinforcement learning (RL) and leveraging active visual tools. However, such strategies are typically language-centric, with visual information being treated as static preconditions. Quality-related visual cues often cannot be abstracted into text in extenso due to the gap between discrete textual tokens and quality perception space, which in turn restricts the reasoning effectiveness for visually intensive IQA tasks. In this paper, we revisit this by asking the question, "Is natural language the ideal space for quality reasoning?" and, as a consequence, we propose Q-Tacit, a new paradigm that elicits VLMs to reason beyond natural language in the latent quality space. Our approach follows a synergistic two-stage process: (i) injecting structural visual quality priors into the latent space, and (ii) calibrating latent reasoning trajectories to improve quality assessment ability. Extensive experiments demonstrate that Q-Tacit can effectively perform quality reasoning with significantly fewer tokens than previous reasoning-based methods, while achieving strong overall performance. This paper validates the proposition that language is not the only compact representation suitable for visual quality, opening possibilities for further exploration of effective latent reasoning paradigms for IQA. Source code will be released to support future research.
QuarkMedBench: A Real-World Scenario Driven Benchmark for Evaluating Large Language Models
Mar 14, 2026While Large Language Models (LLMs) excel on standardized medical exams, high scores often fail to translate to high-quality responses for real-world medical queries. Current evaluations rely heavily on multiple-choice questions, failing to capture the unstructured, ambiguous, and long-tail complexities inherent in genuine user inquiries. To bridge this gap, we introduce QuarkMedBench, an ecologically valid benchmark tailored for real-world medical LLM assessment. We compiled a massive dataset spanning Clinical Care, Wellness Health, and Professional Inquiry, comprising 20,821 single-turn queries and 3,853 multi-turn sessions. To objectively evaluate open-ended answers, we propose an automated scoring framework that integrates multi-model consensus with evidence-based retrieval to dynamically generate 220,617 fine-grained scoring rubrics (~9.8 per query). During evaluation, hierarchical weighting and safety constraints structurally quantify medical accuracy, key-point coverage, and risk interception, effectively mitigating the high costs and subjectivity of human grading. Experimental results demonstrate that the generated rubrics achieve a 91.8% concordance rate with clinical expert blind audits, establishing highly dependable medical reliability. Crucially, baseline evaluations on this benchmark reveal significant performance disparities among state-of-the-art models when navigating real-world clinical nuances, highlighting the limitations of conventional exam-based metrics. Ultimately, QuarkMedBench establishes a rigorous, reproducible yardstick for measuring LLM performance on complex health issues, while its framework inherently supports dynamic knowledge updates to prevent benchmark obsolescence.
SAM3-LiteText: An Anatomical Study of the SAM3 Text Encoder for Efficient Vision-Language Segmentation
Feb 12, 2026Vision-language segmentation models such as SAM3 enable flexible, prompt-driven visual grounding, but inherit large, general-purpose text encoders originally designed for open-ended language understanding. In practice, segmentation prompts are short, structured, and semantically constrained, leading to substantial over-provisioning in text encoder capacity and persistent computational and memory overhead. In this paper, we perform a large-scale anatomical analysis of text prompting in vision-language segmentation, covering 404,796 real prompts across multiple benchmarks. Our analysis reveals severe redundancy: most context windows are underutilized, vocabulary usage is highly sparse, and text embeddings lie on low-dimensional manifold despite high-dimensional representations. Motivated by these findings, we propose SAM3-LiteText, a lightweight text encoding framework that replaces the original SAM3 text encoder with a compact MobileCLIP student that is optimized by knowledge distillation. Extensive experiments on image and video segmentation benchmarks show that SAM3-LiteText reduces text encoder parameters by up to 88%, substantially reducing static memory footprint, while maintaining segmentation performance comparable to the original model. Code: https://github.com/SimonZeng7108/efficientsam3/tree/sam3_litetext.
SCRIBE: Structured Mid-Level Supervision for Tool-Using Language Models
Jan 07, 2026Training reliable tool-augmented agents remains a significant challenge, largely due to the difficulty of credit assignment in multi-step reasoning. While process-level reward models offer a promising direction, existing LLM-based judges often produce noisy and inconsistent signals because they lack fine-grained, task-specific rubrics to distinguish high-level planning from low-level execution. In this work, we introduce SCRIBE (Skill-Conditioned Reward with Intermediate Behavioral Evaluation), a reinforcement learning framework that intervenes at a novel mid-level abstraction. SCRIBE grounds reward modeling in a curated library of skill prototypes, transforming open-ended LLM evaluation into a constrained verification problem. By routing each subgoal to a corresponding prototype, the reward model is equipped with precise, structured rubrics that substantially reduce reward variance. Experimental results show that SCRIBE achieves state-of-the-art performance across a range of reasoning and tool-use benchmarks. In particular, it improves the AIME25 accuracy of a Qwen3-4B model from 43.3% to 63.3%, and significantly increases success rates in complex multi-turn tool interactions. Further analysis of training dynamics reveals a co-evolution across abstraction levels, where mastery of mid-level skills consistently precedes the emergence of effective high-level planning behaviors. Finally, we demonstrate that SCRIBE is additive to low-level tool optimizations, providing a scalable and complementary pathway toward more autonomous and reliable tool-using agents.
Omni2Sound: Towards Unified Video-Text-to-Audio Generation
Jan 06, 2026Training a unified model integrating video-to-audio (V2A), text-to-audio (T2A), and joint video-text-to-audio (VT2A) generation offers significant application flexibility, yet faces two unexplored foundational challenges: (1) the scarcity of high-quality audio captions with tight A-V-T alignment, leading to severe semantic conflict between multimodal conditions, and (2) cross-task and intra-task competition, manifesting as an adverse V2A-T2A performance trade-off and modality bias in the VT2A task. First, to address data scarcity, we introduce SoundAtlas, a large-scale dataset (470k pairs) that significantly outperforms existing benchmarks and even human experts in quality. Powered by a novel agentic pipeline, it integrates Vision-to-Language Compression to mitigate visual bias of MLLMs, a Junior-Senior Agent Handoff for a 5 times cost reduction, and rigorous Post-hoc Filtering to ensure fidelity. Consequently, SoundAtlas delivers semantically rich and temporally detailed captions with tight V-A-T alignment. Second, we propose Omni2Sound, a unified VT2A diffusion model supporting flexible input modalities. To resolve the inherent cross-task and intra-task competition, we design a three-stage multi-task progressive training schedule that converts cross-task competition into joint optimization and mitigates modality bias in the VT2A task, maintaining both audio-visual alignment and off-screen audio generation faithfulness. Finally, we construct VGGSound-Omni, a comprehensive benchmark for unified evaluation, including challenging off-screen tracks. With a standard DiT backbone, Omni2Sound achieves unified SOTA performance across all three tasks within a single model, demonstrating strong generalization across benchmarks with heterogeneous input conditions. The project page is at https://swapforward.github.io/Omni2Sound.
GFix: Perceptually Enhanced Gaussian Splatting Video Compression
Nov 10, 2025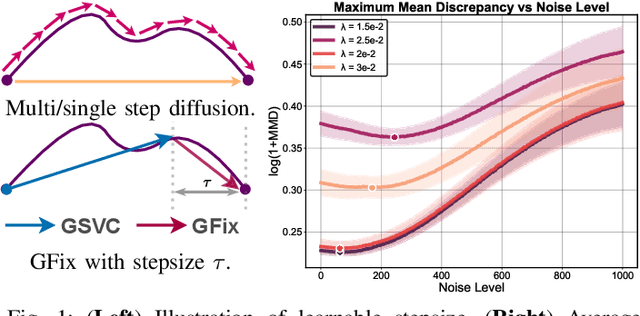
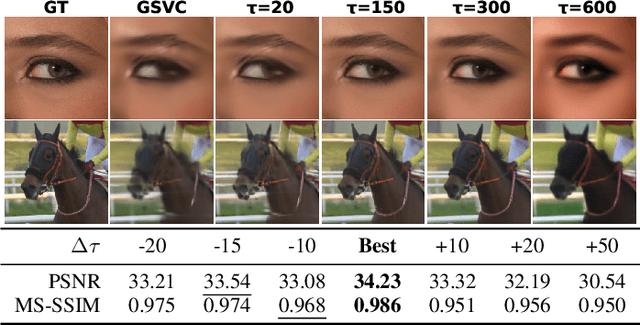
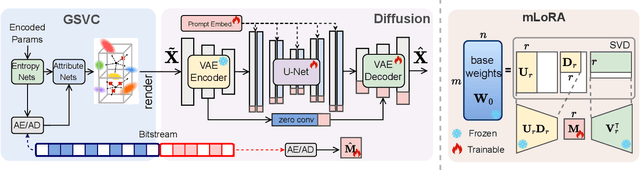
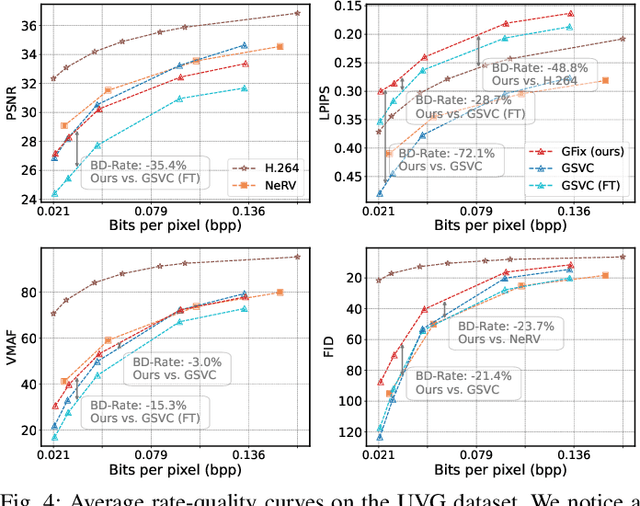
3D Gaussian Splatting (3DGS) enhances 3D scene reconstruction through explicit representation and fast rendering, demonstrating potential benefits for various low-level vision tasks, including video compression. However, existing 3DGS-based video codecs generally exhibit more noticeable visual artifacts and relatively low compression ratios. In this paper, we specifically target the perceptual enhancement of 3DGS-based video compression, based on the assumption that artifacts from 3DGS rendering and quantization resemble noisy latents sampled during diffusion training. Building on this premise, we propose a content-adaptive framework, GFix, comprising a streamlined, single-step diffusion model that serves as an off-the-shelf neural enhancer. Moreover, to increase compression efficiency, We propose a modulated LoRA scheme that freezes the low-rank decompositions and modulates the intermediate hidden states, thereby achieving efficient adaptation of the diffusion backbone with highly compressible updates. Experimental results show that GFix delivers strong perceptual quality enhancement, outperforming GSVC with up to 72.1% BD-rate savings in LPIPS and 21.4% in FID.