 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransform and Entropy Coding in AV2
Jan 06, 2026AV2 is the successor to the AV1 royalty-free video coding standard developed by the Alliance for Open Media (AOMedia). Its primary objective is to deliver substantial compression gains and subjective quality improvements while maintaining low-complexity encoder and decoder operations. This paper describes the transform, quantization and entropy coding design in AV2, including redesigned transform kernels and data-driven transforms, expanded transform partitioning, and a mode & coefficient dependent transform signaling. AV2 introduces several new coding tools including Intra/Inter Secondary Transforms (IST), Trellis Coded Quantization (TCQ), Adaptive Transform Coding (ATC), Probability Adaptation Rate Adjustment (PARA), Forward Skip Coding (FSC), Cross Chroma Component Transforms (CCTX), Parity Hiding (PH) tools and improved lossless coding. These advances enable AV2 to deliver the highest quality video experience for video applications at a significantly reduced bitrate.
C2D-ISR: Optimizing Attention-based Image Super-resolution from Continuous to Discrete Scales
Mar 17, 2025In recent years, attention mechanisms have been exploited in single image super-resolution (SISR), achieving impressive reconstruction results. However, these advancements are still limited by the reliance on simple training strategies and network architectures designed for discrete up-sampling scales, which hinder the model's ability to effectively capture information across multiple scales. To address these limitations, we propose a novel framework, \textbf{C2D-ISR}, for optimizing attention-based image super-resolution models from both performance and complexity perspectives. Our approach is based on a two-stage training methodology and a hierarchical encoding mechanism. The new training methodology involves continuous-scale training for discrete scale models, enabling the learning of inter-scale correlations and multi-scale feature representation. In addition, we generalize the hierarchical encoding mechanism with existing attention-based network structures, which can achieve improved spatial feature fusion, cross-scale information aggregation, and more importantly, much faster inference. We have evaluated the C2D-ISR framework based on three efficient attention-based backbones, SwinIR-L, SRFormer-L and MambaIRv2-L, and demonstrated significant improvements over the other existing optimization framework, HiT, in terms of super-resolution performance (up to 0.2dB) and computational complexity reduction (up to 11%). The source code will be made publicly available at www.github.com.
HIIF: Hierarchical Encoding based Implicit Image Function for Continuous Super-resolution
Dec 04, 2024



Recent advances in implicit neural representations (INRs) have shown significant promise in modeling visual signals for various low-vision tasks including image super-resolution (ISR). INR-based ISR methods typically learn continuous representations, providing flexibility for generating high-resolution images at any desired scale from their low-resolution counterparts. However, existing INR-based ISR methods utilize multi-layer perceptrons for parameterization in the network; this does not take account of the hierarchical structure existing in local sampling points and hence constrains the representation capability. In this paper, we propose a new \textbf{H}ierarchical encoding based \textbf{I}mplicit \textbf{I}mage \textbf{F}unction for continuous image super-resolution, \textbf{HIIF}, which leverages a novel hierarchical positional encoding that enhances the local implicit representation, enabling it to capture fine details at multiple scales. Our approach also embeds a multi-head linear attention mechanism within the implicit attention network by taking additional non-local information into account. Our experiments show that, when integrated with different backbone encoders, HIIF outperforms the state-of-the-art continuous image super-resolution methods by up to 0.17dB in PSNR. The source code of HIIF will be made publicly available at \url{www.github.com}.
RTSR: A Real-Time Super-Resolution Model for AV1 Compressed Content
Nov 20, 2024



Super-resolution (SR) is a key technique for improving the visual quality of video content by increasing its spatial resolution while reconstructing fine details. SR has been employed in many applications including video streaming, where compressed low-resolution content is typically transmitted to end users and then reconstructed with a higher resolution and enhanced quality. To support real-time playback, it is important to implement fast SR models while preserving reconstruction quality; however most existing solutions, in particular those based on complex deep neural networks, fail to do so. To address this issue, this paper proposes a low-complexity SR method, RTSR, designed to enhance the visual quality of compressed video content, focusing on resolution up-scaling from a) 360p to 1080p and from b) 540p to 4K. The proposed approach utilizes a CNN-based network architecture, which was optimized for AV1 (SVT)-encoded content at various quantization levels based on a dual-teacher knowledge distillation method. This method was submitted to the AIM 2024 Video Super-Resolution Challenge, specifically targeting the Efficient/Mobile Real-Time Video Super-Resolution competition. It achieved the best trade-off between complexity and coding performance (measured in PSNR, SSIM and VMAF) among all six submissions. The code will be available soon.
BVI-AOM: A New Training Dataset for Deep Video Compression Optimization
Aug 07, 2024Deep learning is now playing an important role in enhancing the performance of conventional hybrid video codecs. These learning-based methods typically require diverse and representative training material for optimization in order to achieve model generalization and optimal coding performance. However, existing datasets either offer limited content variability or come with restricted licensing terms constraining their use to research purposes only. To address these issues, we propose a new training dataset, named BVI-AOM, which contains 956 uncompressed sequences at various resolutions from 270p to 2160p, covering a wide range of content and texture types. The dataset comes with more flexible licensing terms and offers competitive performance when used as a training set for optimizing deep video coding tools. The experimental results demonstrate that when used as a training set to optimize two popular network architectures for two different coding tools, the proposed dataset leads to additional bitrate savings of up to 0.29 and 2.98 percentage points in terms of PSNR-Y and VMAF, respectively, compared to an existing training dataset, BVI-DVC, which has been widely used for deep video coding. The BVI-AOM dataset is available for download under this link: (TBD).
Banding vs. Quality: Perceptual Impact and Objective Assessment
Feb 22, 2022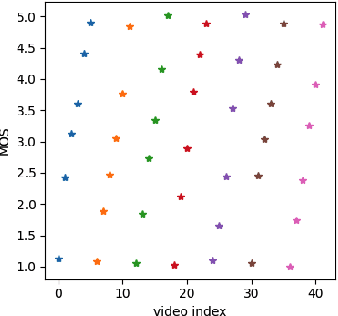
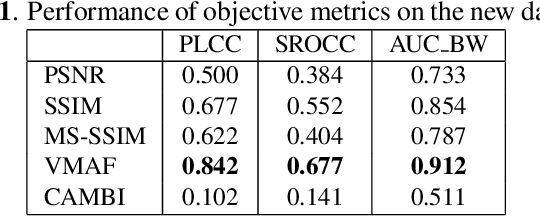
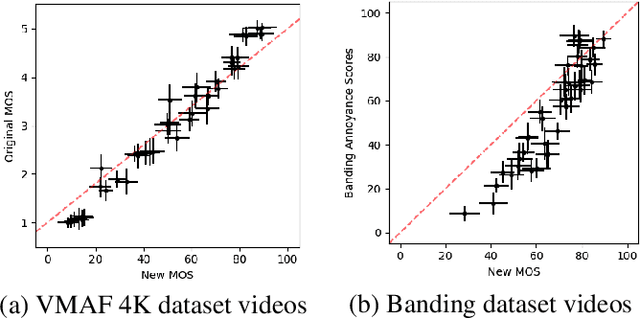
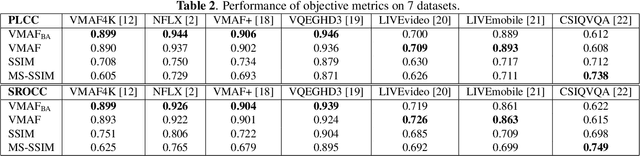
Staircase-like contours introduced to a video by quantization in flat areas, commonly known as banding, have been a long-standing problem in both video processing and quality assessment communities. The fact that even a relatively small change of the original pixel values can result in a strong impact on perceived quality makes banding especially difficult to be detected by objective quality metrics. In this paper, we study how banding annoyance compares to more commonly studied scaling and compression artifacts with respect to the overall perceptual quality. We further propose a simple combination of VMAF and the recently developed banding index, CAMBI, into a banding-aware video quality metric showing improved correlation with overall perceived quality.
VMAF-based Bitrate Ladder Estimation for Adaptive Streaming
Mar 12, 2021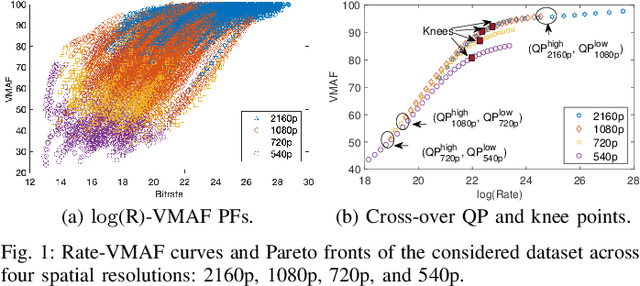
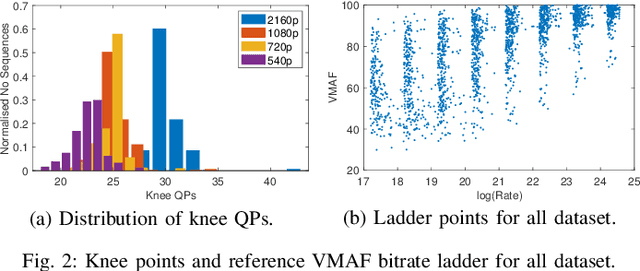
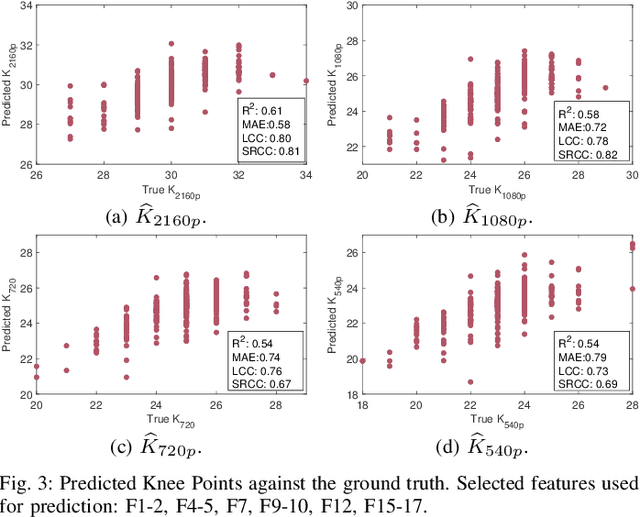
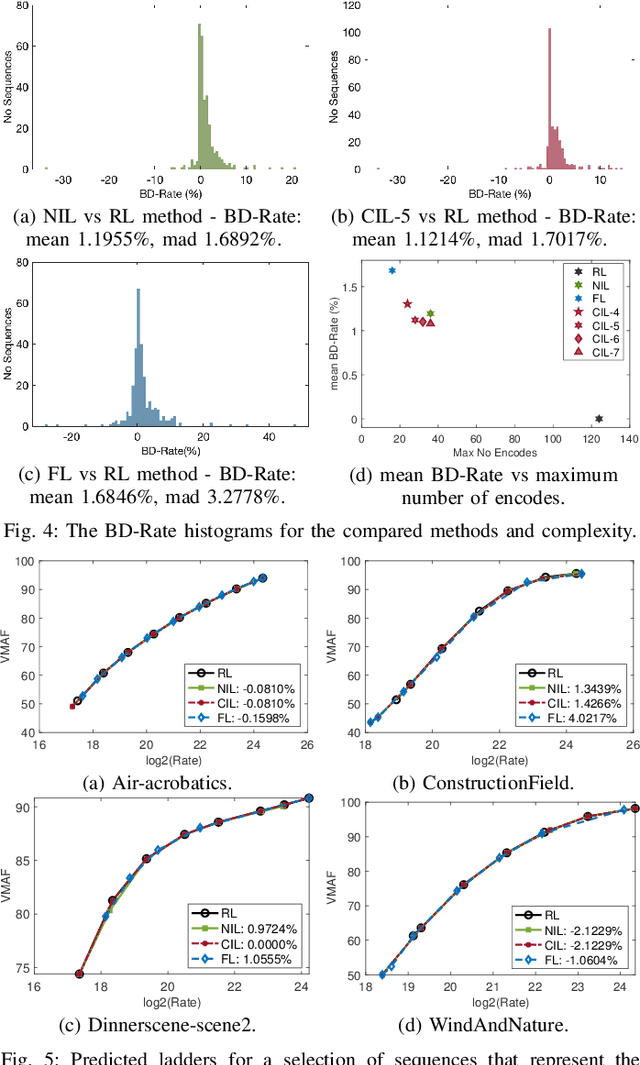
In HTTP Adaptive Streaming, video content is conventionally encoded by adapting its spatial resolution and quantization level to best match the prevailing network state and display characteristics. It is well known that the traditional solution, of using a fixed bitrate ladder, does not result in the highest quality of experience for the user. Hence, in this paper, we consider a content-driven approach for estimating the bitrate ladder, based on spatio-temporal features extracted from the uncompressed content. The method implements a content-driven interpolation. It uses the extracted features to train a machine learning model to infer the curvature points of the Rate-VMAF curves in order to guide a set of initial encodings. We employ the VMAF quality metric as a means of perceptually conditioning the estimation. When compared to exhaustive encoding that produces the reference ladder, the estimated ladder is composed by 74.3% of identical Rate-VMAF points with the reference ladder. The proposed method offers a significant reduction of the number of encodes required, 77.4%, at a small average Bj{\o}ntegaard Delta Rate cost, 1.12%.
Efficient Bitrate Ladder Construction for Content-Optimized Adaptive Video Streaming
Feb 08, 2021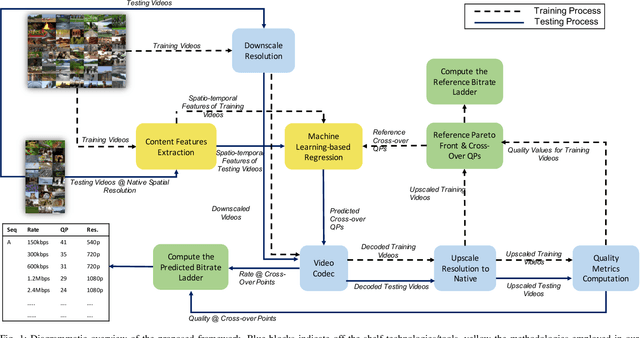
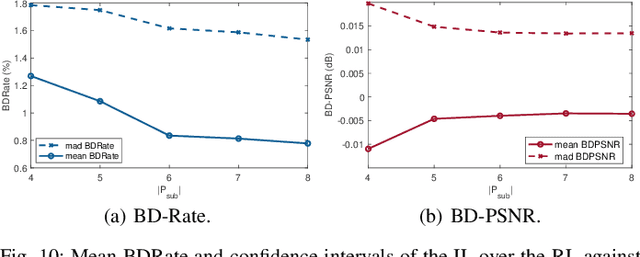

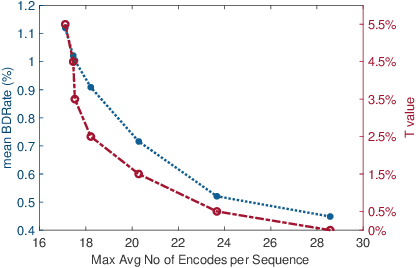
One of the challenges faced by many video providers is the heterogeneity of network specifications, user requirements, and content compression performance. The universal solution of a fixed bitrate ladder is inadequate in ensuring a high quality of user experience without re-buffering or introducing annoying compression artifacts. However, a content-tailored solution, based on extensively encoding across all resolutions and over a wide quality range is highly expensive in terms of computational, financial, and energy costs. Inspired by this, we propose an approach that exploits machine learning to predict a content-optimized bitrate ladder. The method extracts spatio-temporal features from the uncompressed content, trains machine-learning models to predict the Pareto front parameters, and, based on that, builds the ladder within a defined bitrate range. The method has the benefit of significantly reducing the number of encodes required per sequence. The presented results, based on 100 HEVC-encoded sequences, demonstrate a reduction in the number of encodes required when compared to an exhaustive search and an interpolation-based method, by 89.06% and 61.46%, respectively, at the cost of an average Bj{\o}ntegaard Delta Rate difference of 1.78% compared to the exhaustive approach. Finally, a hybrid method is introduced that selects either the proposed or the interpolation-based method depending on the sequence features. This results in an overall 83.83% reduction of required encodings at the cost of an average Bj{\o}ntegaard Delta Rate difference of 1.26%.
CAMBI: Contrast-aware Multiscale Banding Index
Jan 29, 2021
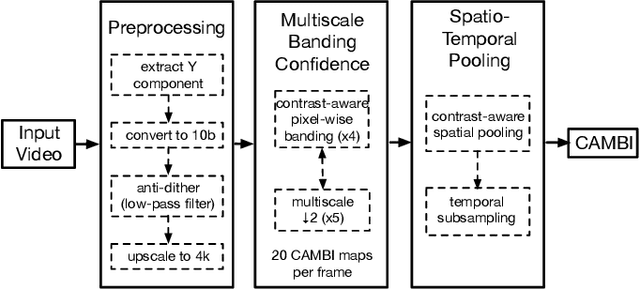
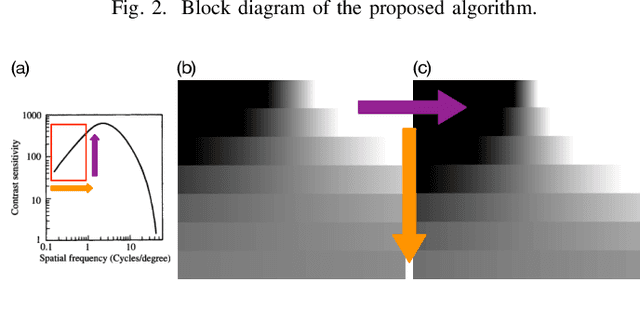
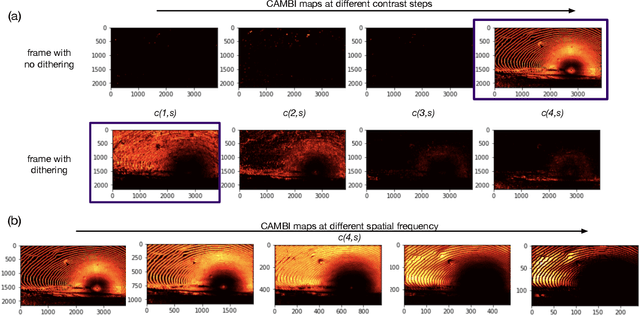
Banding artifacts are artificially-introduced contours arising from the quantization of a smooth region in a video. Despite the advent of recent higher quality video systems with more efficient codecs, these artifacts remain conspicuous, especially on larger displays. In this work, a comprehensive subjective study is performed to understand the dependence of the banding visibility on encoding parameters and dithering. We subsequently develop a simple and intuitive no-reference banding index called CAMBI (Contrast-aware Multiscale Banding Index) which uses insights from Contrast Sensitivity Function in the Human Visual System to predict banding visibility. CAMBI correlates well with subjective perception of banding while using only a few visually-motivated hyperparameters.