 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating readily synthesizable small molecule fluorophore scaffolds with reinforcement learning
Jan 12, 2026Developing new fluorophores for advanced imaging techniques requires exploring new chemical space. While generative AI approaches have shown promise in designing novel dye scaffolds, prior efforts often produced synthetically intractable candidates due to a lack of reaction constraints. Here, we developed SyntheFluor-RL, a generative AI model that employs known reaction libraries and molecular building blocks to create readily synthesizable fluorescent molecule scaffolds via reinforcement learning. To guide the generation of fluorophores, SyntheFluor-RL employs a scoring function built on multiple graph neural networks (GNNs) that predict key photophysical properties, including photoluminescence quantum yield, absorption, and emission wavelengths. These outputs are dynamically weighted and combined with a computed pi-conjugation score to prioritize candidates with desirable optical characteristics and synthetic feasibility. SyntheFluor-RL generated 11,590 candidate molecules, which were filtered to 19 structures predicted to possess dye-like properties. Of the 19 molecules, 14 were synthesized and 13 were experimentally confirmed. The top three were characterized, with the lead compound featuring a benzothiadiazole chromophore and exhibiting strong fluorescence (PLQY = 0.62), a large Stokes shift (97 nm), and a long excited-state lifetime (11.5 ns). These results demonstrate the effectiveness of SyntheFluor-RL in the identification of synthetically accessible fluorophores for further development.
Predicting Drug Solubility Using Different Machine Learning Methods -- Linear Regression Model with Extracted Chemical Features vs Graph Convolutional Neural Network
Aug 23, 2023



Predicting the solubility of given molecules is an important task in the pharmaceutical industry, and consequently this is a well-studied topic. In this research, we revisited this problem with the advantage of modern computing resources. We applied two machine learning models, a linear regression model and a graph convolutional neural network model, on multiple experimental datasets. Both methods can make reasonable predictions while the GCNN model had the best performance. However, the current GCNN model is a black box, while feature importance analysis from the linear regression model offers more insights into the underlying chemical influences. Using the linear regression model, we show how each functional group affects the overall solubility. Ultimately, knowing how chemical structure influences chemical properties is crucial when designing new drugs. Future work should aim to combine the high performance of GCNNs with the interpretability of linear regression, unlocking new advances in next generation high throughput screening.
Monte Carlo Tree Search for Interpreting Stress in Natural Language
Apr 17, 2022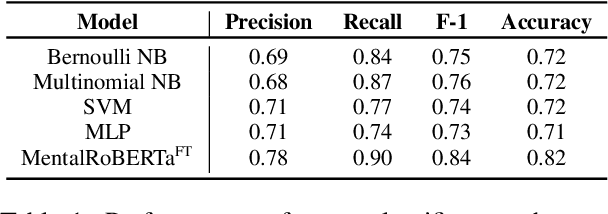


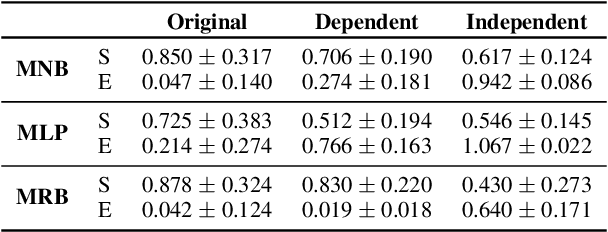
Natural language processing can facilitate the analysis of a person's mental state from text they have written. Previous studies have developed models that can predict whether a person is experiencing a mental health condition from social media posts with high accuracy. Yet, these models cannot explain why the person is experiencing a particular mental state. In this work, we present a new method for explaining a person's mental state from text using Monte Carlo tree search (MCTS). Our MCTS algorithm employs trained classification models to guide the search for key phrases that explain the writer's mental state in a concise, interpretable manner. Furthermore, our algorithm can find both explanations that depend on the particular context of the text (e.g., a recent breakup) and those that are context-independent. Using a dataset of Reddit posts that exhibit stress, we demonstrate the ability of our MCTS algorithm to identify interpretable explanations for a person's feeling of stress in both a context-dependent and context-independent manner.
VMAF-based Bitrate Ladder Estimation for Adaptive Streaming
Mar 12, 2021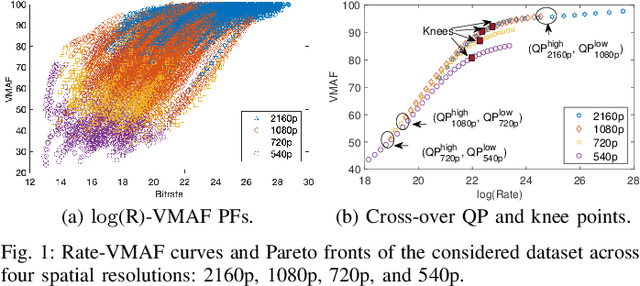
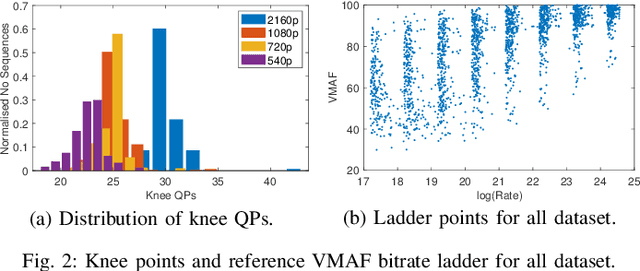
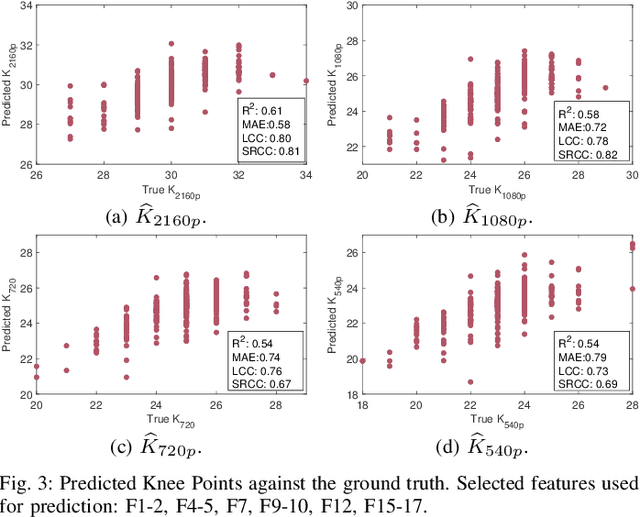
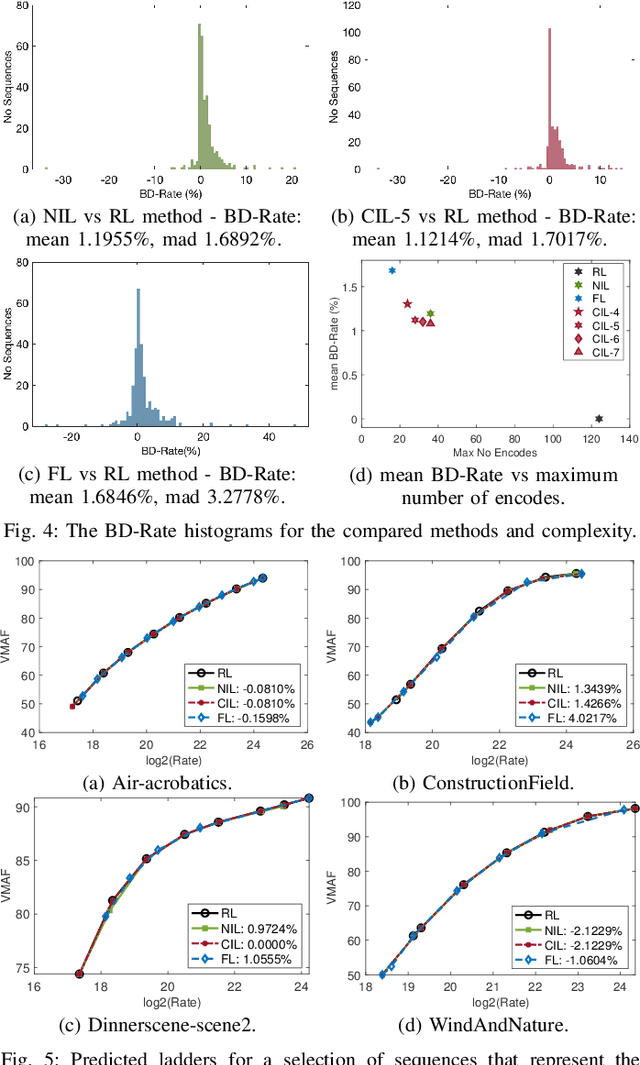
In HTTP Adaptive Streaming, video content is conventionally encoded by adapting its spatial resolution and quantization level to best match the prevailing network state and display characteristics. It is well known that the traditional solution, of using a fixed bitrate ladder, does not result in the highest quality of experience for the user. Hence, in this paper, we consider a content-driven approach for estimating the bitrate ladder, based on spatio-temporal features extracted from the uncompressed content. The method implements a content-driven interpolation. It uses the extracted features to train a machine learning model to infer the curvature points of the Rate-VMAF curves in order to guide a set of initial encodings. We employ the VMAF quality metric as a means of perceptually conditioning the estimation. When compared to exhaustive encoding that produces the reference ladder, the estimated ladder is composed by 74.3% of identical Rate-VMAF points with the reference ladder. The proposed method offers a significant reduction of the number of encodes required, 77.4%, at a small average Bj{\o}ntegaard Delta Rate cost, 1.12%.
Rationalizing Text Matching: Learning Sparse Alignments via Optimal Transport
May 27, 2020

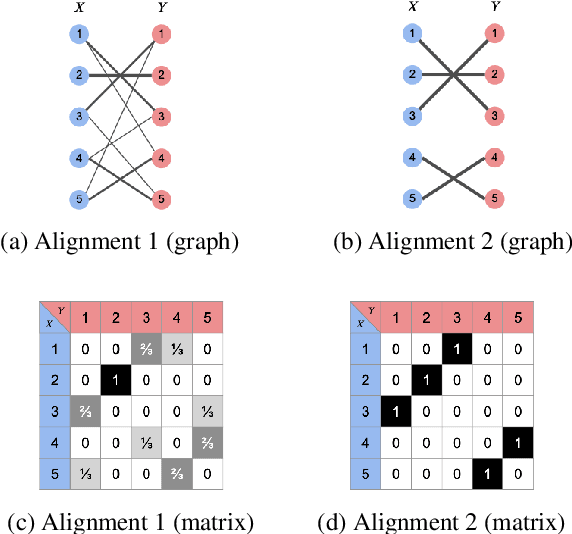
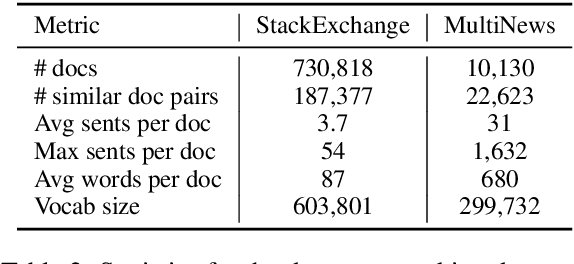
Selecting input features of top relevance has become a popular method for building self-explaining models. In this work, we extend this selective rationalization approach to text matching, where the goal is to jointly select and align text pieces, such as tokens or sentences, as a justification for the downstream prediction. Our approach employs optimal transport (OT) to find a minimal cost alignment between the inputs. However, directly applying OT often produces dense and therefore uninterpretable alignments. To overcome this limitation, we introduce novel constrained variants of the OT problem that result in highly sparse alignments with controllable sparsity. Our model is end-to-end differentiable using the Sinkhorn algorithm for OT and can be trained without any alignment annotations. We evaluate our model on the StackExchange, MultiNews, e-SNLI, and MultiRC datasets. Our model achieves very sparse rationale selections with high fidelity while preserving prediction accuracy compared to strong attention baseline models.
Uncertainty Quantification Using Neural Networks for Molecular Property Prediction
May 20, 2020



Uncertainty quantification (UQ) is an important component of molecular property prediction, particularly for drug discovery applications where model predictions direct experimental design and where unanticipated imprecision wastes valuable time and resources. The need for UQ is especially acute for neural models, which are becoming increasingly standard yet are challenging to interpret. While several approaches to UQ have been proposed in the literature, there is no clear consensus on the comparative performance of these models. In this paper, we study this question in the context of regression tasks. We systematically evaluate several methods on five benchmark datasets using multiple complementary performance metrics. Our experiments show that none of the methods we tested is unequivocally superior to all others, and none produces a particularly reliable ranking of errors across multiple datasets. While we believe these results show that existing UQ methods are not sufficient for all common use-cases and demonstrate the benefits of further research, we conclude with a practical recommendation as to which existing techniques seem to perform well relative to others.
Improving Molecular Design by Stochastic Iterative Target Augmentation
Feb 11, 2020
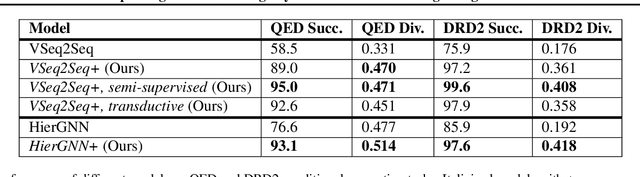


Generative models in molecular design tend to be richly parameterized, data-hungry neural models, as they must create complex structured objects as outputs. Estimating such models from data may be challenging due to the lack of sufficient training data. In this paper, we propose a surprisingly effective self-training approach for iteratively creating additional molecular targets. We first pre-train the generative model together with a simple property predictor. The property predictor is then used as a likelihood model for filtering candidate structures from the generative model. Additional targets are iteratively produced and used in the course of stochastic EM iterations to maximize the log-likelihood that the candidate structures are accepted. A simple rejection (re-weighting) sampler suffices to draw posterior samples since the generative model is already reasonable after pre-training. We demonstrate significant gains over strong baselines for both unconditional and conditional molecular design. In particular, our approach outperforms the previous state-of-the-art in conditional molecular design by over 10% in absolute gain.
Deep Learning for Automated Classification and Characterization of Amorphous Materials
Sep 10, 2019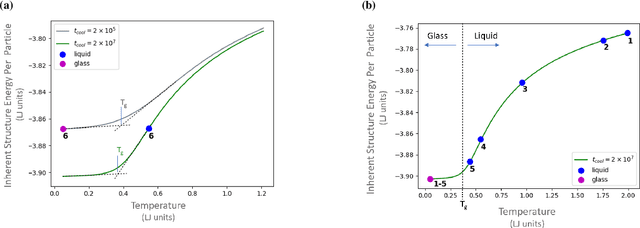
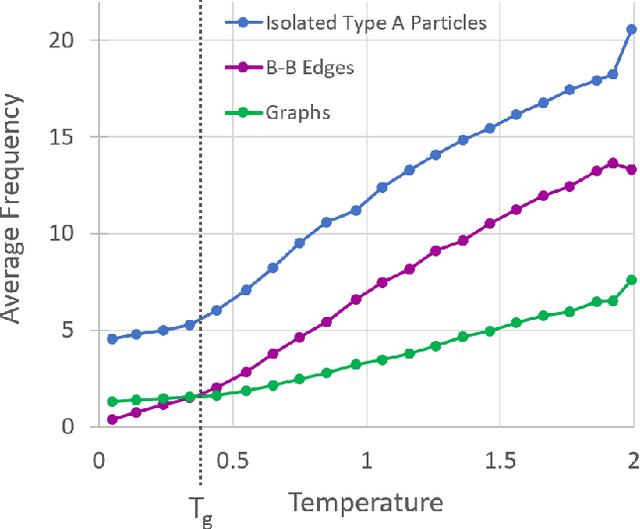
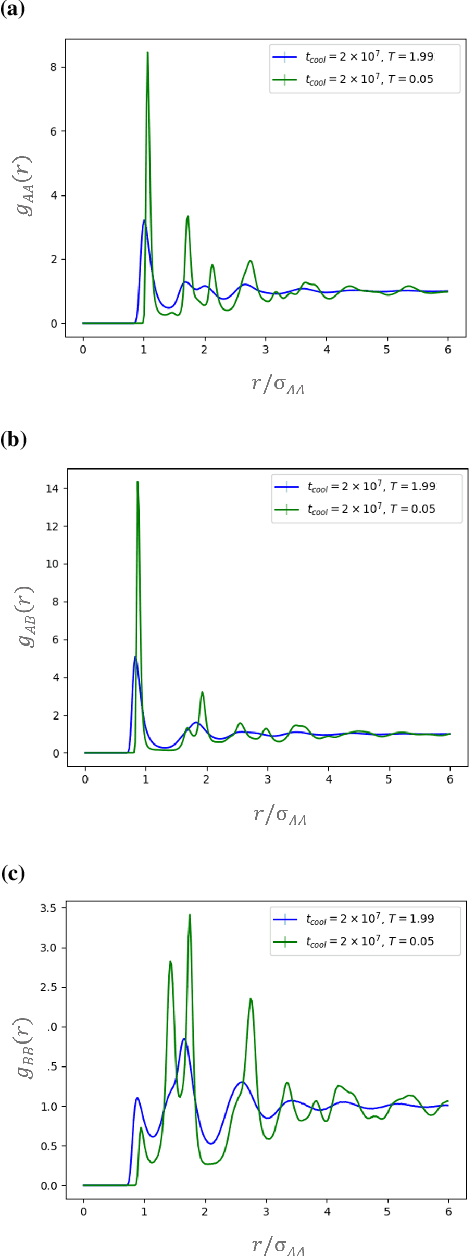
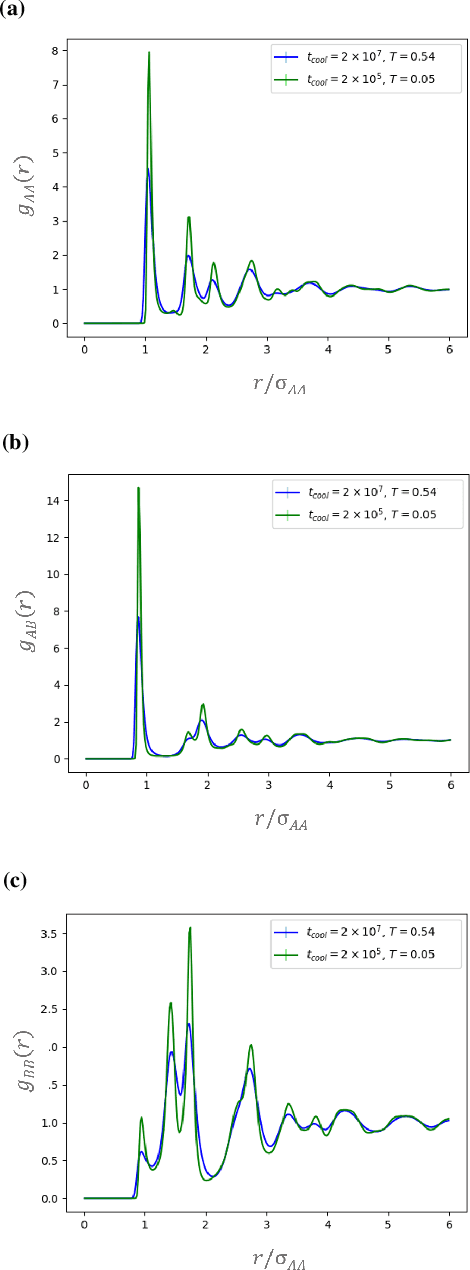
It is difficult to quantify structure-property relationships and to identify structural features of complex materials. The characterization of amorphous materials is especially challenging because their lack of long-range order makes it difficult to define structural metrics. In this work, we apply deep learning algorithms to accurately classify amorphous materials and characterize their structural features. Specifically, we show that convolutional neural networks and message passing neural networks can classify two-dimensional liquids and liquid-cooled glasses from molecular dynamics simulations with greater than 0.98 AUC, with no a priori assumptions about local particle relationships, even when the liquids and glasses are prepared at the same inherent structure energy. Furthermore, we demonstrate that message passing neural networks surpass convolutional neural networks in this context in both accuracy and interpretability. We extract a clear interpretation of how message passing neural networks evaluate liquid and glass structures by using a self-attention mechanism. Using this interpretation, we derive three novel structural metrics that accurately characterize glass formation. The methods presented here provide us with a procedure to identify important structural features in materials that could be missed by standard techniques and give us a unique insight into how these neural networks process data.
Building a Production Model for Retrieval-Based Chatbots
Jun 07, 2019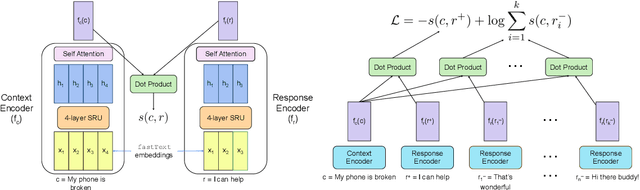


Response suggestion is an important task for building human-computer conversation systems. Recent approaches to conversation modeling have introduced new model architectures with impressive results, but relatively little attention has been paid to whether these models would be practical in a production setting. In this paper, we describe the unique challenges of building a production retrieval-based conversation system, which selects outputs from a whitelist of candidate responses. To address these challenges, we propose a dual encoder architecture which performs rapid inference and scales well with the size of the whitelist. We also introduce and compare two methods for generating whitelists, and we carry out a comprehensive analysis of the model and whitelists. Experimental results on a large, proprietary help desk chat dataset, including both offline metrics and a human evaluation, indicate production-quality performance and illustrate key lessons about conversation modeling in practice.
Are Learned Molecular Representations Ready For Prime Time?
Apr 02, 2019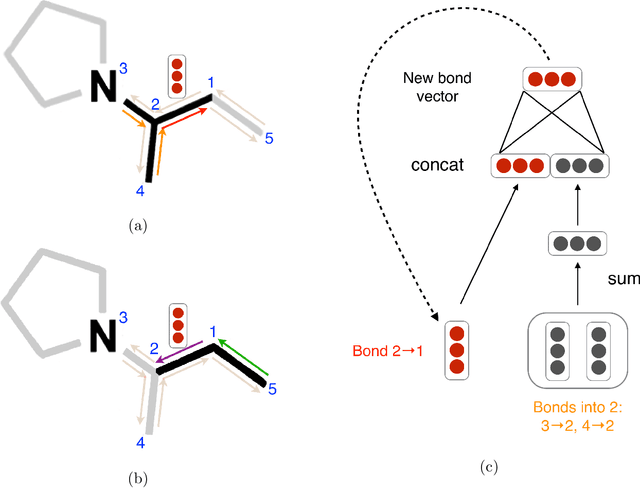



Advancements in neural machinery have led to a wide range of algorithmic solutions for molecular property prediction. Two classes of models in particular have yielded promising results: neural networks applied to computed molecular fingerprints or expert-crafted descriptors, and graph convolutional neural networks that construct a learned molecular representation by operating on the graph structure of the molecule. However, recent literature has yet to clearly determine which of these two methods is superior when generalizing to new chemical space. Furthermore, prior research has rarely examined these new models in industry research settings in comparison to existing employed models. In this paper, we benchmark models extensively on 19 public and 15 proprietary industrial datasets spanning a wide variety of chemical endpoints. In addition, we introduce a graph convolutional model that consistently outperforms models using fixed molecular descriptors as well as previous graph neural architectures on both public and proprietary datasets. Our empirical findings indicate that while approaches based on these representations have yet to reach the level of experimental reproducibility, our proposed model nevertheless offers significant improvements over models currently used in industrial workflows.