 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Refinement Graph Neural Network for Antibody Sequence-Structure Co-design
Oct 15, 2021
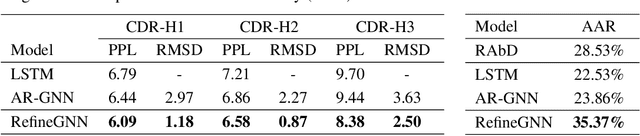
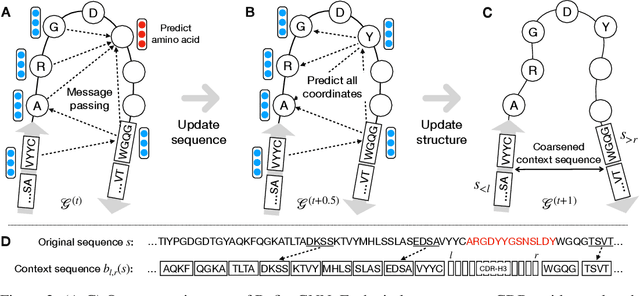

Antibodies are versatile proteins that bind to pathogens like viruses and stimulate the adaptive immune system. The specificity of antibody binding is determined by complementarity-determining regions (CDRs) at the tips of these Y-shaped proteins. In this paper, we propose a generative model to automatically design the CDRs of antibodies with enhanced binding specificity or neutralization capabilities. Previous generative approaches formulate protein design as a structure-conditioned sequence generation task, assuming the desired 3D structure is given a priori. In contrast, we propose to co-design the sequence and 3D structure of CDRs as graphs. Our model unravels a sequence autoregressively while iteratively refining its predicted global structure. The inferred structure in turn guides subsequent residue choices. For efficiency, we model the conditional dependence between residues inside and outside of a CDR in a coarse-grained manner. Our method achieves superior log-likelihood on the test set and outperforms previous baselines in designing antibodies capable of neutralizing the SARS-CoV-2 virus.
Autoregressive Knowledge Distillation through Imitation Learning
Sep 15, 2020
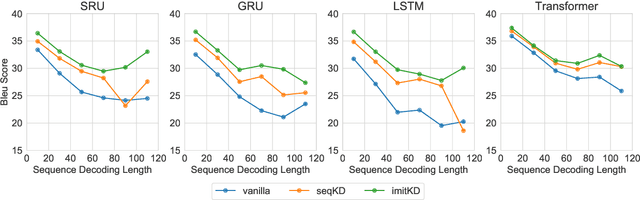
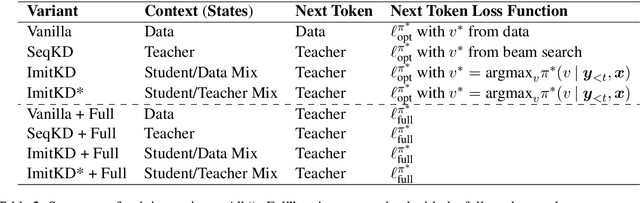
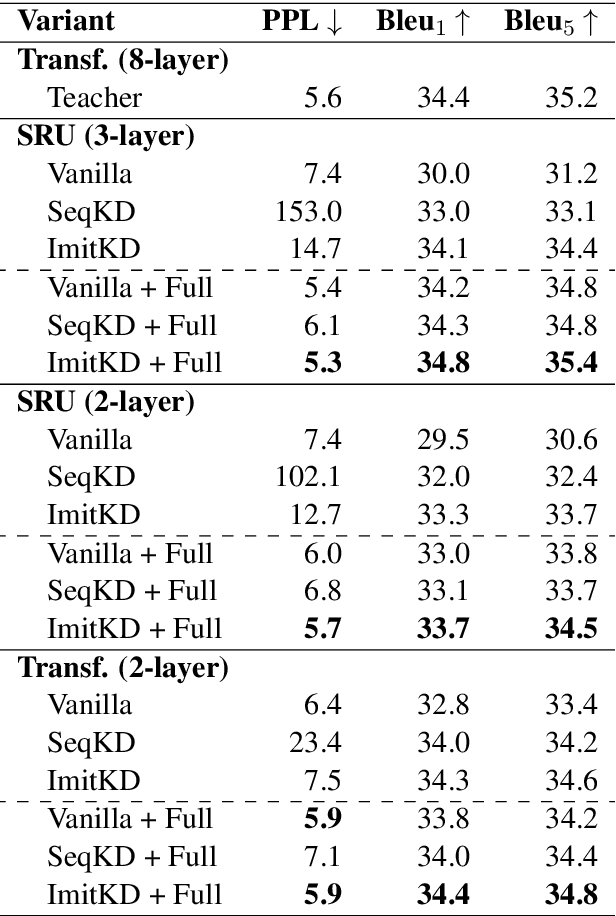
The performance of autoregressive models on natural language generation tasks has dramatically improved due to the adoption of deep, self-attentive architectures. However, these gains have come at the cost of hindering inference speed, making state-of-the-art models cumbersome to deploy in real-world, time-sensitive settings. We develop a compression technique for autoregressive models that is driven by an imitation learning perspective on knowledge distillation. The algorithm is designed to address the exposure bias problem. On prototypical language generation tasks such as translation and summarization, our method consistently outperforms other distillation algorithms, such as sequence-level knowledge distillation. Student models trained with our method attain 1.4 to 4.8 BLEU/ROUGE points higher than those trained from scratch, while increasing inference speed by up to 14 times in comparison to the teacher model.
ASAPP-ASR: Multistream CNN and Self-Attentive SRU for SOTA Speech Recognition
May 21, 2020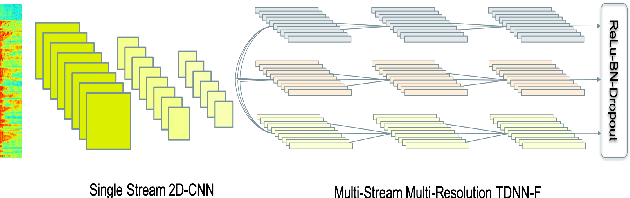
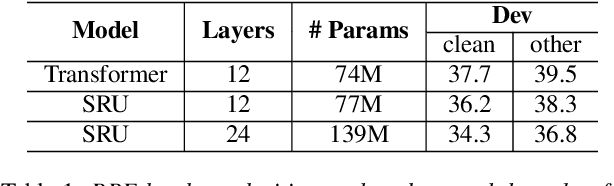
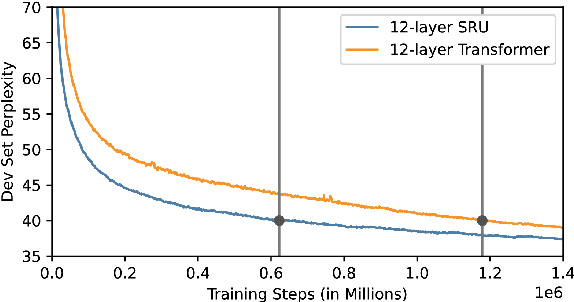
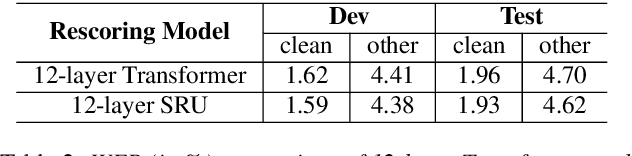
In this paper we present state-of-the-art (SOTA) performance on the LibriSpeech corpus with two novel neural network architectures, a multistream CNN for acoustic modeling and a self-attentive simple recurrent unit (SRU) for language modeling. In the hybrid ASR framework, the multistream CNN acoustic model processes an input of speech frames in multiple parallel pipelines where each stream has a unique dilation rate for diversity. Trained with the SpecAugment data augmentation method, it achieves relative word error rate (WER) improvements of 4% on test-clean and 14% on test-other. We further improve the performance via N-best rescoring using a 24-layer self-attentive SRU language model, achieving WERs of 1.75% on test-clean and 4.46% on test-other.
Metric Learning for Dynamic Text Classification
Nov 04, 2019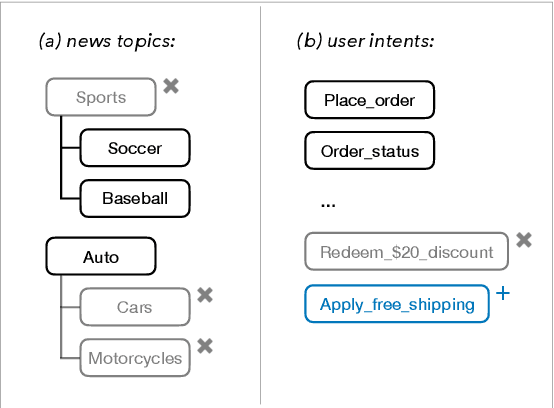
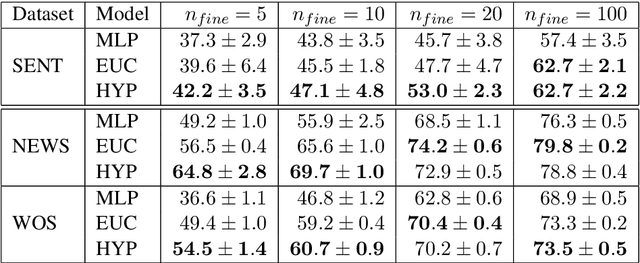
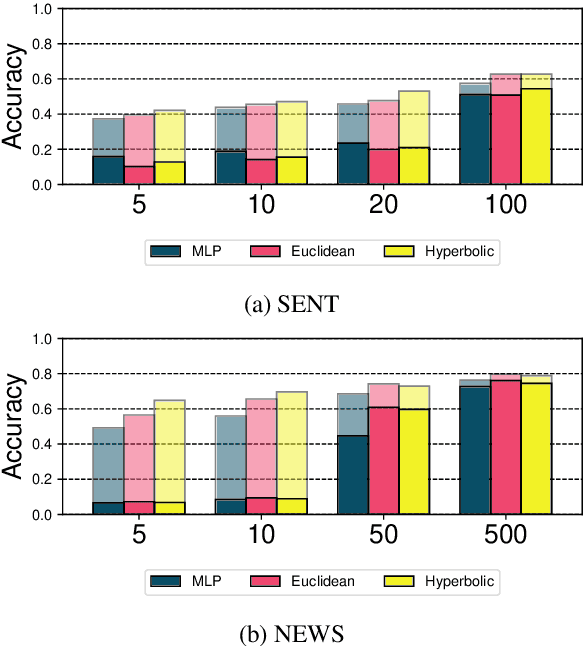
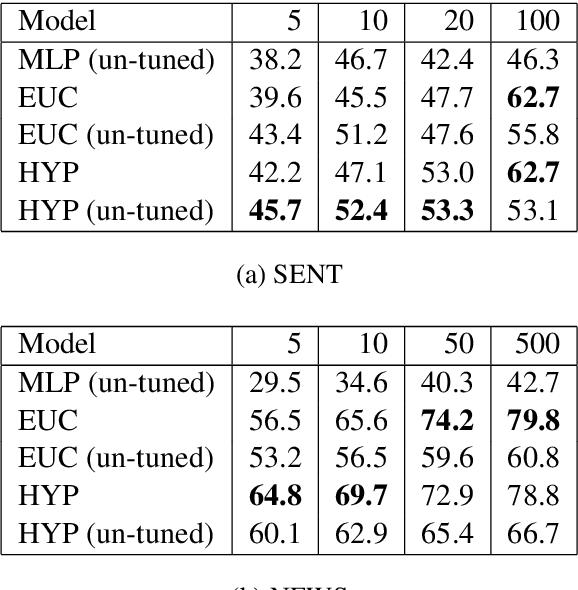
Traditional text classifiers are limited to predicting over a fixed set of labels. However, in many real-world applications the label set is frequently changing. For example, in intent classification, new intents may be added over time while others are removed. We propose to address the problem of dynamic text classification by replacing the traditional, fixed-size output layer with a learned, semantically meaningful metric space. Here the distances between textual inputs are optimized to perform nearest-neighbor classification across overlapping label sets. Changing the label set does not involve removing parameters, but rather simply adding or removing support points in the metric space. Then the learned metric can be fine-tuned with only a few additional training examples. We demonstrate that this simple strategy is robust to changes in the label space. Furthermore, our results show that learning a non-Euclidean metric can improve performance in the low data regime, suggesting that further work on metric spaces may benefit low-resource research.
Structured Pruning of Large Language Models
Oct 10, 2019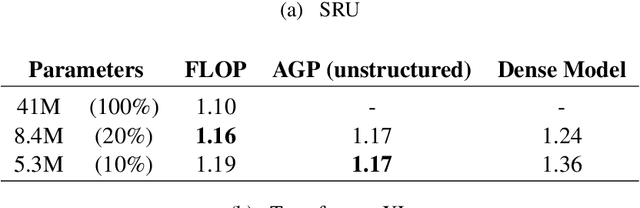
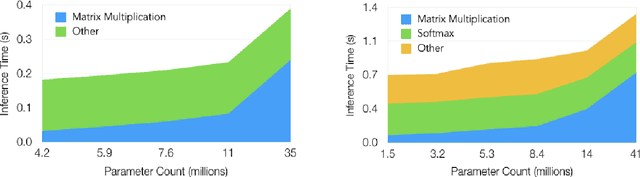
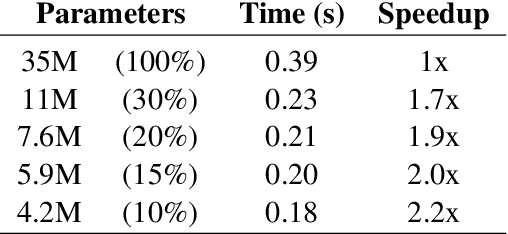
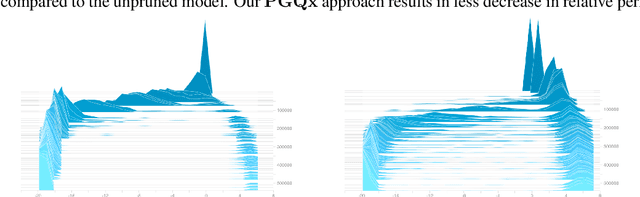
Large language models have recently achieved state of the art performance across a wide variety of natural language tasks. Meanwhile, the size of these models and their latency have significantly increased, which makes their usage costly, and raises an interesting question: do language models need to be large? We study this question through the lens of model compression. We present a novel, structured pruning approach based on low rank factorization and augmented Lagrangian L0 norm regularization. Our structured approach achieves significant inference speedups while matching or outperforming our unstructured pruning baseline at various sparsity levels. We apply our method to state of the art models on the enwiki8 dataset and obtain a 1.19 perplexity score with just 5M parameters, vastly outperforming a model of the same size trained from scratch. We also demonstrate that our method can be applied to language model fine-tuning by pruning the BERT model on several downstream classification benchmarks.
Building a Production Model for Retrieval-Based Chatbots
Jun 07, 2019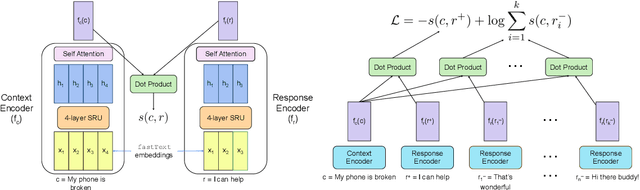
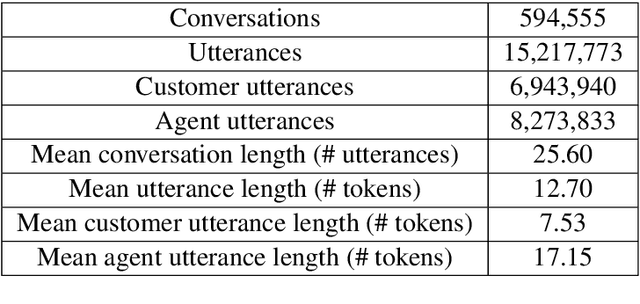


Response suggestion is an important task for building human-computer conversation systems. Recent approaches to conversation modeling have introduced new model architectures with impressive results, but relatively little attention has been paid to whether these models would be practical in a production setting. In this paper, we describe the unique challenges of building a production retrieval-based conversation system, which selects outputs from a whitelist of candidate responses. To address these challenges, we propose a dual encoder architecture which performs rapid inference and scales well with the size of the whitelist. We also introduce and compare two methods for generating whitelists, and we carry out a comprehensive analysis of the model and whitelists. Experimental results on a large, proprietary help desk chat dataset, including both offline metrics and a human evaluation, indicate production-quality performance and illustrate key lessons about conversation modeling in practice.