 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGistScore: Learning Better Representations for In-Context Example Selection with Gist Bottlenecks
Nov 16, 2023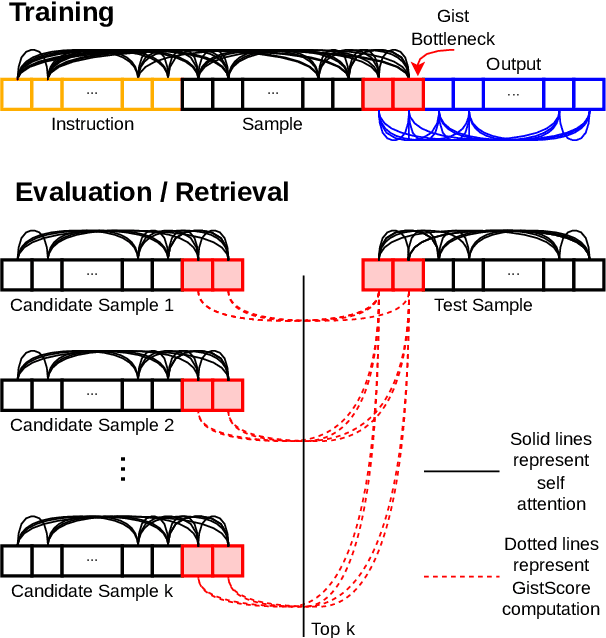
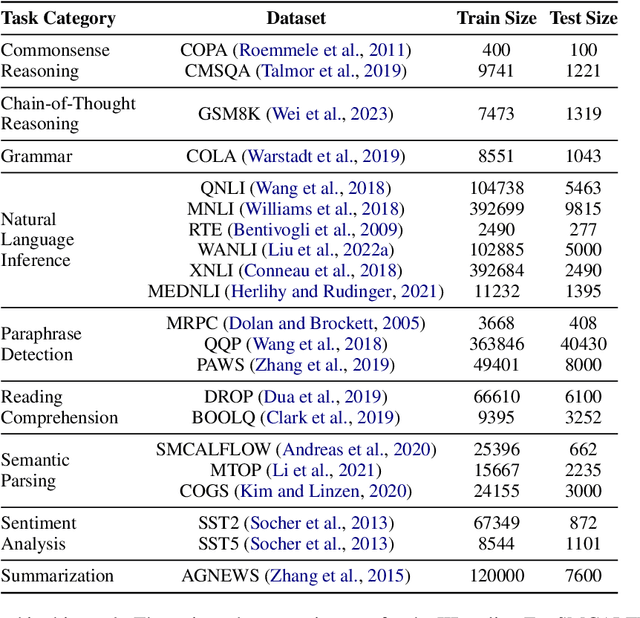
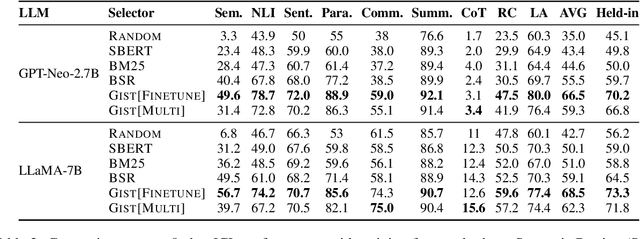
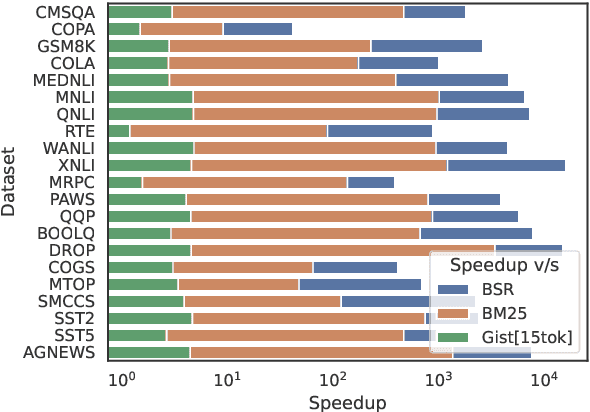
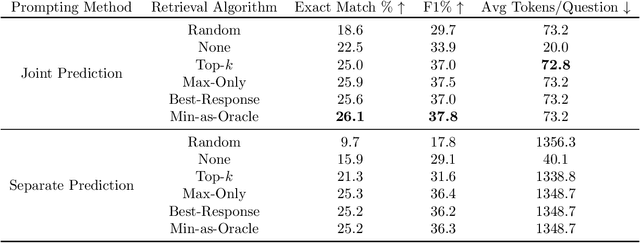
Large language models (LLMs) have the ability to perform in-context learning (ICL) of new tasks by conditioning on prompts comprising a few task examples. This work studies the problem of selecting the best examples given a candidate pool to improve ICL performance on given a test input. Existing approaches either require training with feedback from a much larger LLM or are computationally expensive. We propose a novel metric, GistScore, based on Example Gisting, a novel approach for training example retrievers for ICL using an attention bottleneck via Gisting, a recent technique for compressing task instructions. To tradeoff performance with ease of use, we experiment with both fine-tuning gist models on each dataset and multi-task training a single model on a large collection of datasets. On 21 diverse datasets spanning 9 tasks, we show that our fine-tuned models get state-of-the-art ICL performance with 20% absolute average gain over off-the-shelf retrievers and 7% over the best prior methods. Our multi-task model generalizes well out-of-the-box to new task categories, datasets, and prompt templates with retrieval speeds that are consistently thousands of times faster than the best prior training-free method.
On the Effectiveness of Offline RL for Dialogue Response Generation
Jul 23, 2023



A common training technique for language models is teacher forcing (TF). TF attempts to match human language exactly, even though identical meanings can be expressed in different ways. This motivates use of sequence-level objectives for dialogue response generation. In this paper, we study the efficacy of various offline reinforcement learning (RL) methods to maximize such objectives. We present a comprehensive evaluation across multiple datasets, models, and metrics. Offline RL shows a clear performance improvement over teacher forcing while not inducing training instability or sacrificing practical training budgets.
Submodular Minimax Optimization: Finding Effective Sets
May 26, 2023

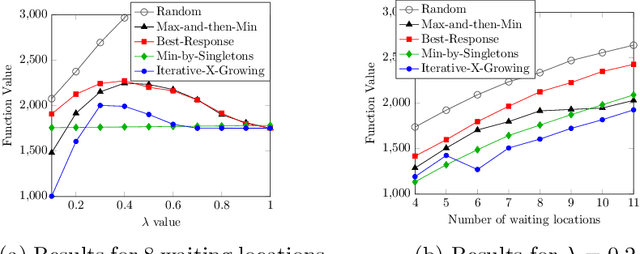
Despite the rich existing literature about minimax optimization in continuous settings, only very partial results of this kind have been obtained for combinatorial settings. In this paper, we fill this gap by providing a characterization of submodular minimax optimization, the problem of finding a set (for either the min or the max player) that is effective against every possible response. We show when and under what conditions we can find such sets. We also demonstrate how minimax submodular optimization provides robust solutions for downstream machine learning applications such as (i) efficient prompt engineering for question answering, (ii) prompt engineering for dialog state tracking, (iii) identifying robust waiting locations for ride-sharing, (iv) ride-share difficulty kernelization, and (v) finding adversarial images. Our experiments demonstrate that our proposed algorithms consistently outperform other baselines.
Domain Private Transformers
May 23, 2023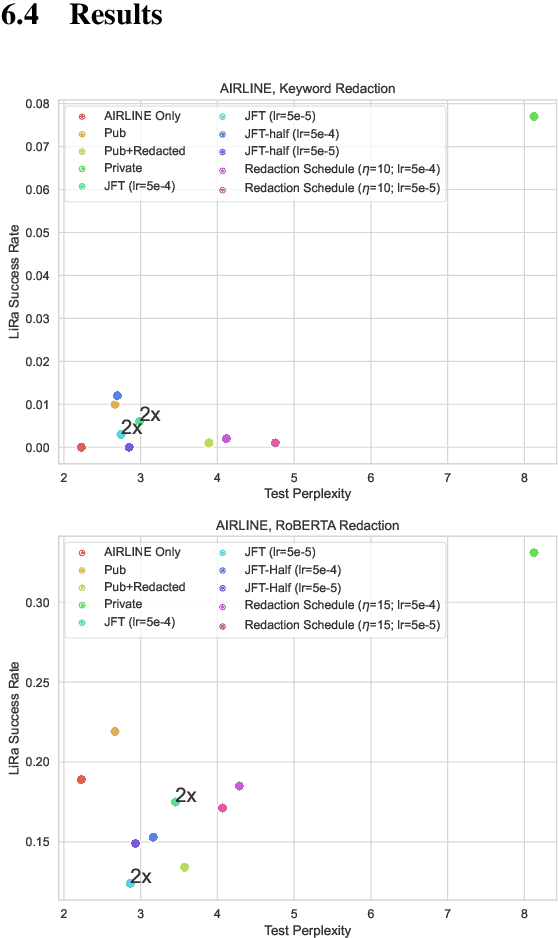
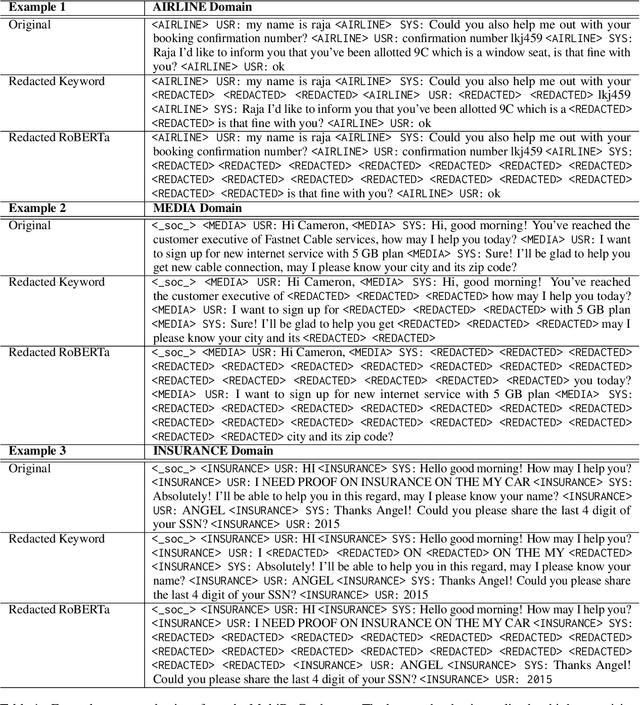
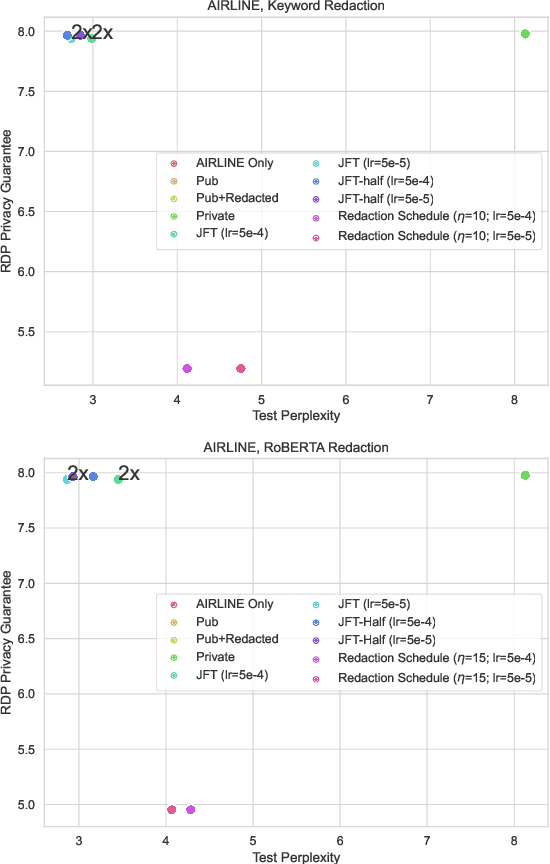
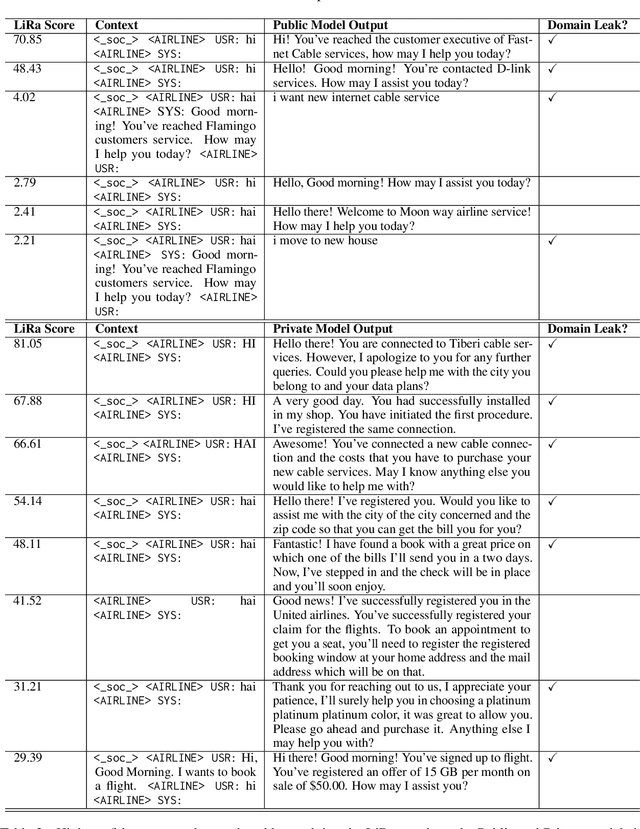
Large, general purpose language models have demonstrated impressive performance across many different conversational domains. While multi-domain language models achieve low overall perplexity, their outputs are not guaranteed to stay within the domain of a given input prompt. This paper proposes domain privacy as a novel way to quantify how likely a conditional language model will leak across domains. We also develop policy functions based on token-level domain classification, and propose an efficient fine-tuning method to improve the trained model's domain privacy. Experiments on membership inference attacks show that our proposed method has comparable resiliency to methods adapted from recent literature on differentially private language models.
CEREAL: Few-Sample Clustering Evaluation
Sep 30, 2022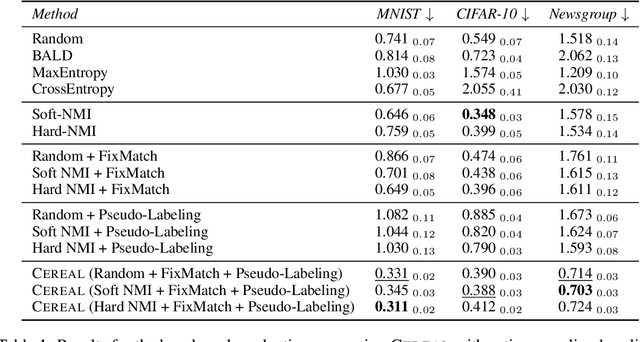



Evaluating clustering quality with reliable evaluation metrics like normalized mutual information (NMI) requires labeled data that can be expensive to annotate. We focus on the underexplored problem of estimating clustering quality with limited labels. We adapt existing approaches from the few-sample model evaluation literature to actively sub-sample, with a learned surrogate model, the most informative data points for annotation to estimate the evaluation metric. However, we find that their estimation can be biased and only relies on the labeled data. To that end, we introduce CEREAL, a comprehensive framework for few-sample clustering evaluation that extends active sampling approaches in three key ways. First, we propose novel NMI-based acquisition functions that account for the distinctive properties of clustering and uncertainties from a learned surrogate model. Next, we use ideas from semi-supervised learning and train the surrogate model with both the labeled and unlabeled data. Finally, we pseudo-label the unlabeled data with the surrogate model. We run experiments to estimate NMI in an active sampling pipeline on three datasets across vision and language. Our results show that CEREAL reduces the area under the absolute error curve by up to 57% compared to the best sampling baseline. We perform an extensive ablation study to show that our framework is agnostic to the choice of clustering algorithm and evaluation metric. We also extend CEREAL from clusterwise annotations to pairwise annotations. Overall, CEREAL can efficiently evaluate clustering with limited human annotations.
Identifying Mislabeled Data using the Area Under the Margin Ranking
Jan 29, 2020
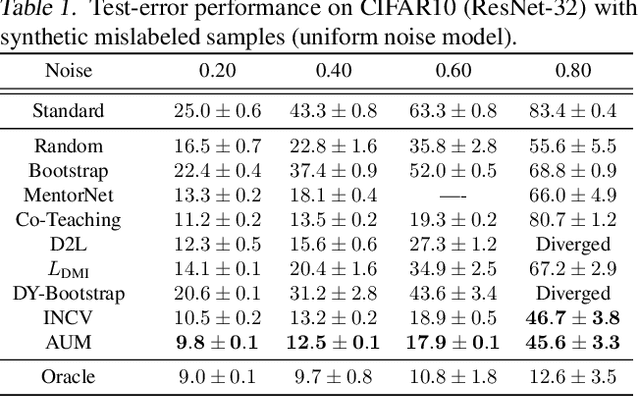

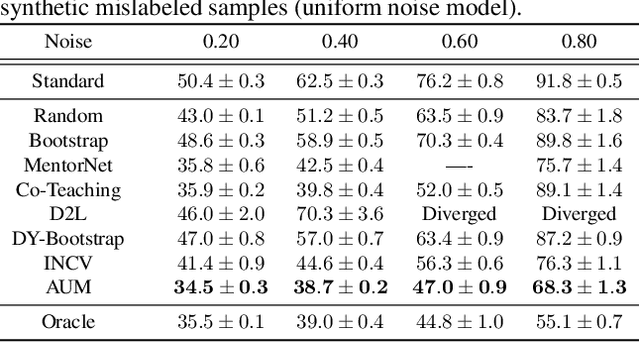
Not all data in a typical training set help with generalization; some samples can be overly ambiguous or outrightly mislabeled. This paper introduces a new method to identify such samples and mitigate their impact when training neural networks. At the heart of our algorithm is the Area Under the Margin (AUM) statistic, which exploits differences in the training dynamics of clean and mislabeled samples. A simple procedure - adding an extra class populated with purposefully mislabeled indicator samples - learns a threshold that isolates mislabeled data based on this metric. This approach consistently improves upon prior work on synthetic and real-world datasets. On the WebVision50 classification task our method removes 17% of training data, yielding a 2.6% (absolute) improvement in test error. On CIFAR100 removing 13% of the data leads to a 1.2% drop in error.
Metric Learning for Dynamic Text Classification
Nov 04, 2019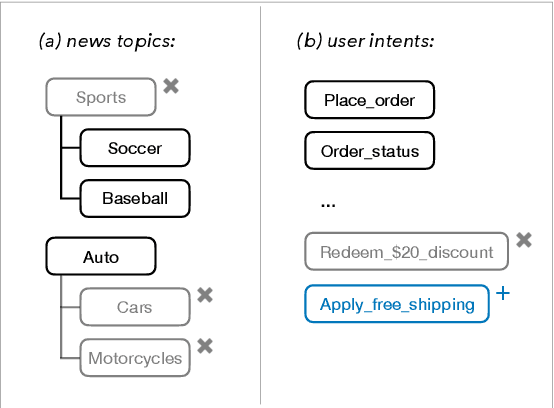
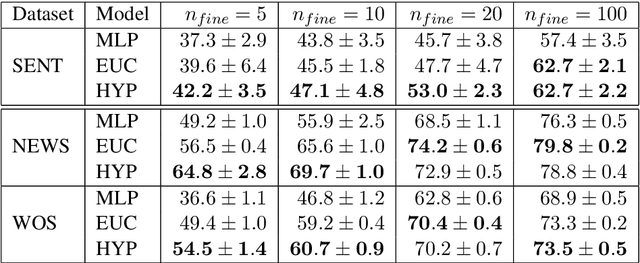
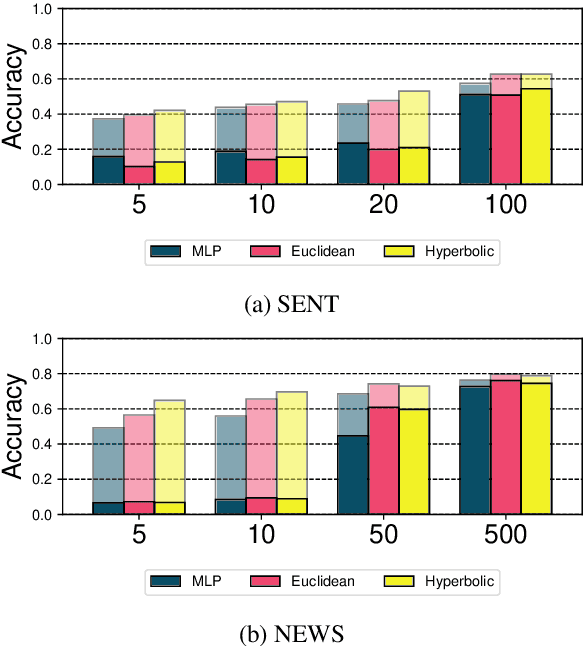
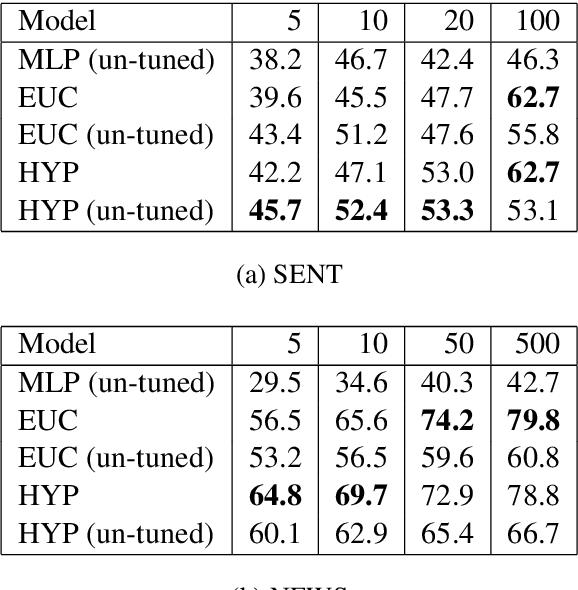
Traditional text classifiers are limited to predicting over a fixed set of labels. However, in many real-world applications the label set is frequently changing. For example, in intent classification, new intents may be added over time while others are removed. We propose to address the problem of dynamic text classification by replacing the traditional, fixed-size output layer with a learned, semantically meaningful metric space. Here the distances between textual inputs are optimized to perform nearest-neighbor classification across overlapping label sets. Changing the label set does not involve removing parameters, but rather simply adding or removing support points in the metric space. Then the learned metric can be fine-tuned with only a few additional training examples. We demonstrate that this simple strategy is robust to changes in the label space. Furthermore, our results show that learning a non-Euclidean metric can improve performance in the low data regime, suggesting that further work on metric spaces may benefit low-resource research.
Importance weighted generative networks
Jun 07, 2018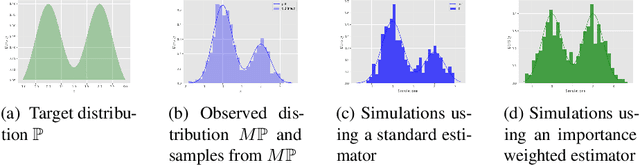

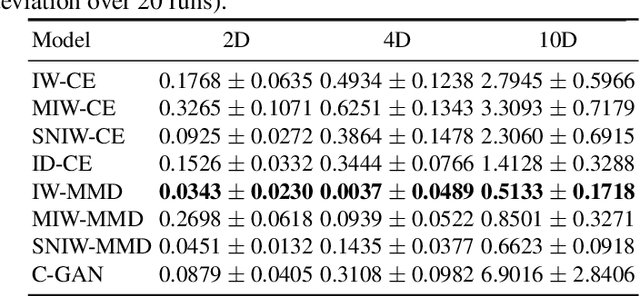
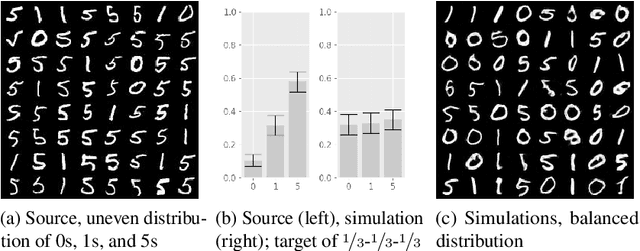
Deep generative networks can simulate from a complex target distribution, by minimizing a loss with respect to samples from that distribution. However, often we do not have direct access to our target distribution - our data may be subject to sample selection bias, or may be from a different but related distribution. We present methods based on importance weighting that can estimate the loss with respect to a target distribution, even if we cannot access that distribution directly, in a variety of settings. These estimators, which differentially weight the contribution of data to the loss function, offer both theoretical guarantees and impressive empirical performance.
Streaming Weak Submodularity: Interpreting Neural Networks on the Fly
Nov 22, 2017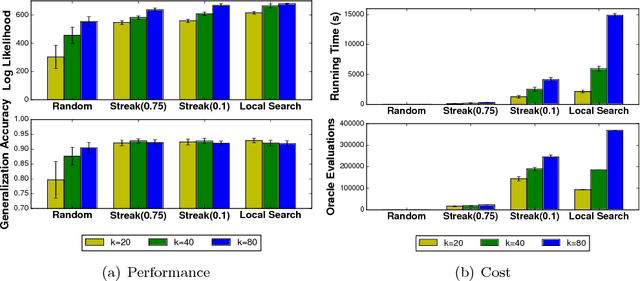
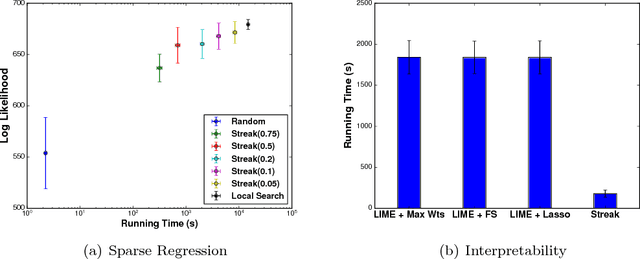
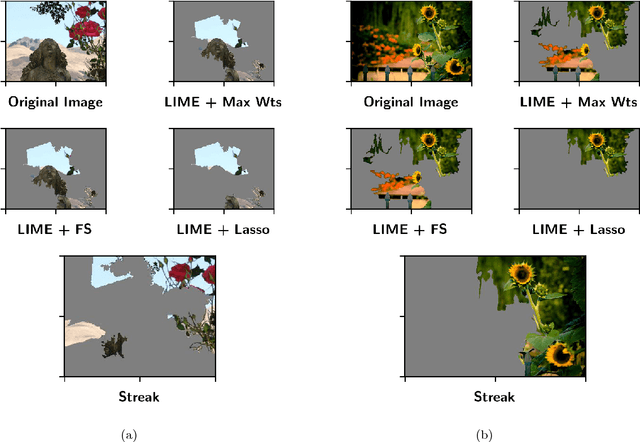

In many machine learning applications, it is important to explain the predictions of a black-box classifier. For example, why does a deep neural network assign an image to a particular class? We cast interpretability of black-box classifiers as a combinatorial maximization problem and propose an efficient streaming algorithm to solve it subject to cardinality constraints. By extending ideas from Badanidiyuru et al. [2014], we provide a constant factor approximation guarantee for our algorithm in the case of random stream order and a weakly submodular objective function. This is the first such theoretical guarantee for this general class of functions, and we also show that no such algorithm exists for a worst case stream order. Our algorithm obtains similar explanations of Inception V3 predictions $10$ times faster than the state-of-the-art LIME framework of Ribeiro et al. [2016].
Restricted Strong Convexity Implies Weak Submodularity
Oct 12, 2017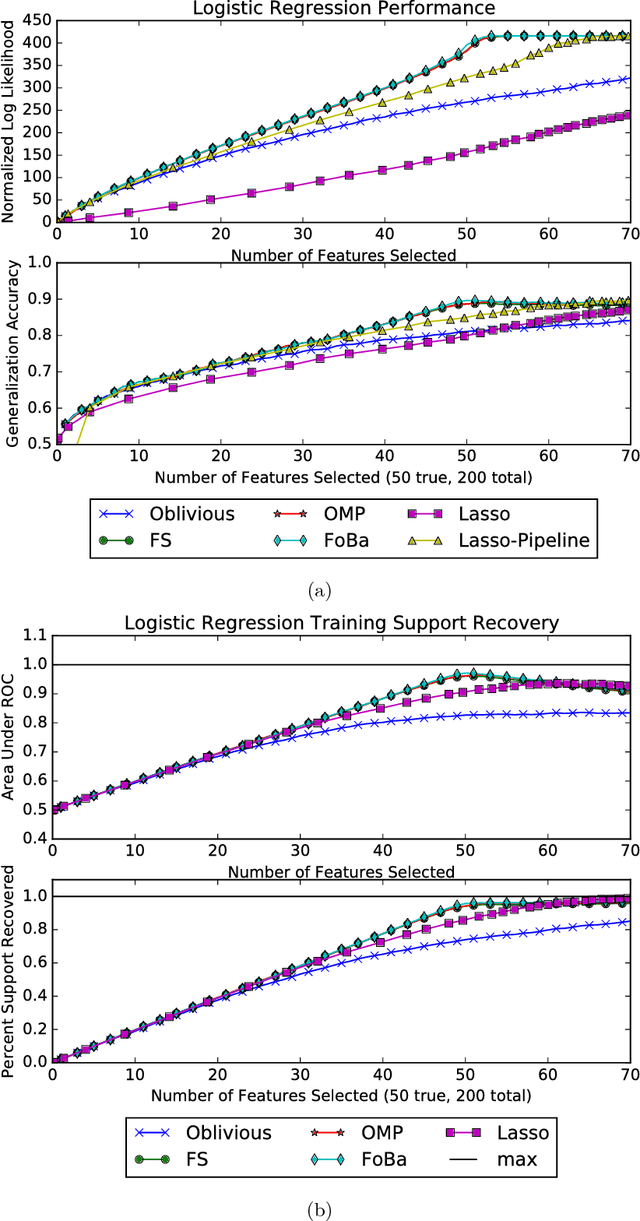
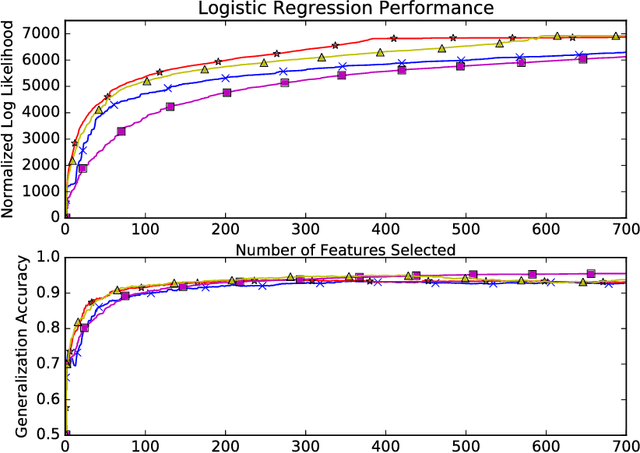
We connect high-dimensional subset selection and submodular maximization. Our results extend the work of Das and Kempe (2011) from the setting of linear regression to arbitrary objective functions. For greedy feature selection, this connection allows us to obtain strong multiplicative performance bounds on several methods without statistical modeling assumptions. We also derive recovery guarantees of this form under standard assumptions. Our work shows that greedy algorithms perform within a constant factor from the best possible subset-selection solution for a broad class of general objective functions. Our methods allow a direct control over the number of obtained features as opposed to regularization parameters that only implicitly control sparsity. Our proof technique uses the concept of weak submodularity initially defined by Das and Kempe. We draw a connection between convex analysis and submodular set function theory which may be of independent interest for other statistical learning applications that have combinatorial structure.