 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Time is Here for Just-in-Time Systems: Challenges and Opportunities
May 22, 2026Core systems like key-value stores have historically taken years to build, and are designed to be general so as to amortize cost across deployments, paying a significant performance cost. We argue that LLM-based coding agents now make a different approach tractable: Just-in-Time Systems, in which the entire system is synthesized from scratch, specialized to the environment, workload, and required system properties. We present a JIT system synthesis pipeline, Jitskit, and explore its effectiveness in synthesizing key-value stores from spec cards that span different YCSB workloads, deployment constraints (e.g., compute resources), and system properties (e.g., consistency and durability). Jitskit iteratively refines a system implementation to match the specification against an evolving evaluation test suite. The resulting synthesized systems are performant, beating comparable state-of-the-art systems on 18 of 18 specs tried, by up to 4.6x over the best off-the-shelf baseline on the most favorable spec. Naively running Claude Code either reward-hacks or underperforms Jitskit by up to 5.4x. We discuss the challenges we overcame in building Jitskit and our key takeaways.
optimize_anything: A Universal API for Optimizing any Text Parameter
May 19, 2026Can a single LLM-based optimization system match specialized tools across fundamentally different domains? We show that when optimization problems are formulated as improving a text artifact evaluated by a scoring function, a single AI-based optimization system-supporting single-task search, multi-task search with cross-problem transfer, and generalization to unseen inputs-achieves state-of-the-art results across six diverse tasks. Our system discovers agent architectures that nearly triple Gemini Flash's ARC-AGI accuracy (32.5% to 89.5%), finds scheduling algorithms that cut cloud costs by 40%, generates CUDA kernels where 87% match or beat PyTorch, and outperforms AlphaEvolve's reported circle packing solution (n=26). Ablations across three domains reveal that actionable side information yields faster convergence and substantially higher final scores than score-only feedback, and that multi-task search outperforms independent optimization given equivalent per-problem budget through cross-task transfer, with benefits scaling with the number of related tasks. Together, we show for the first time that text optimization with LLM-based search is a general-purpose problem-solving paradigm, unifying tasks traditionally requiring domain-specific algorithms under a single framework. We open-source optimize\_anything with support for multiple backends as part of the GEPA project at https://github.com/gepa-ai/gepa .
* 16 pages, 11 figures; Blog: https://gepa-ai.github.io/gepa/blog/2026/02/18/introducing-optimize-anything/
Multimodal QUD: Inquisitive Questions from Scientific Figures
Apr 26, 2026Asking inquisitive questions while reading, and looking for their answers, is an important part in human discourse comprehension, curiosity, and creative ideation, and prior work has investigated this in text-only scenarios. However, in scientific or research papers, many of the critical takeaways are conveyed through both figures and the text that analyzes them. While scientific visualizations have been used to evaluate Vision-Language Models (VLMs) capabilities, current benchmarks are limited to questions that focus simply on extracting information from them. Such questions only require lower-level reasoning, do not take into account the context in which a figure appears, and do not reflect the communicative goals the authors wish to achieve. We generate inquisitive questions that reach the depth of questions humans generate when engaging with scientific papers, conditioned on both the figure and the paper's context, and require reasoning across both modalities. To do so, we extend the linguistic theory of Questions Under Discussion (QUD) from being text-only to multimodal, where implicit questions are raised and resolved as discourse progresses. We present MQUD, a dataset of research papers in which such questions are made explicit and annotated by the original authors. We show that fine-tuning a VLM on MQUD shifts the model from generating generic low-level visual questions to content-specific grounding that requires a high-level of multimodal reasoning, yielding higher-quality, more visually grounded multimodal QUD generation.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Geometric Median Matching for Robust k-Subset Selection from Noisy Data
Apr 03, 2025

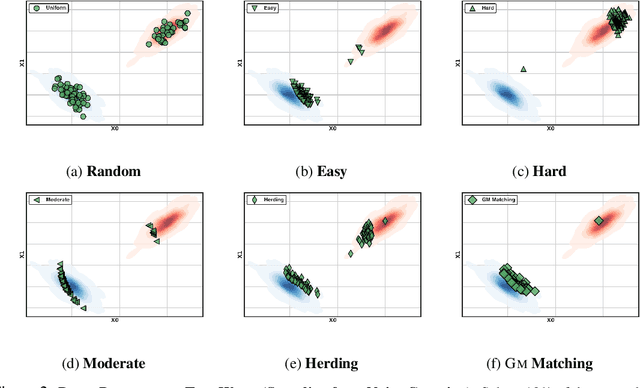

Data pruning -- the combinatorial task of selecting a small and representative subset from a large dataset, is crucial for mitigating the enormous computational costs associated with training data-hungry modern deep learning models at scale. Since large scale data collections are invariably noisy, developing data pruning strategies that remain robust even in the presence of corruption is critical in practice. However, existing data pruning methods often fail under high corruption rates due to their reliance on empirical mean estimation, which is highly sensitive to outliers. In response, we propose Geometric Median (GM) Matching, a novel k-subset selection strategy that leverages Geometric Median -- a robust estimator with an optimal breakdown point of 1/2; to enhance resilience against noisy data. Our method iteratively selects a k-subset such that the mean of the subset approximates the GM of the (potentially) noisy dataset, ensuring robustness even under arbitrary corruption. We provide theoretical guarantees, showing that GM Matching enjoys an improved O(1/k) convergence rate -- a quadratic improvement over random sampling, even under arbitrary corruption. Extensive experiments across image classification and image generation tasks demonstrate that GM Matching consistently outperforms existing pruning approaches, particularly in high-corruption settings and at high pruning rates; making it a strong baseline for robust data pruning.
Self-supervised Speech Models for Word-Level Stuttered Speech Detection
Sep 16, 2024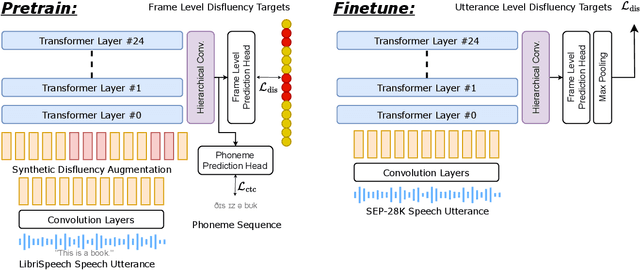
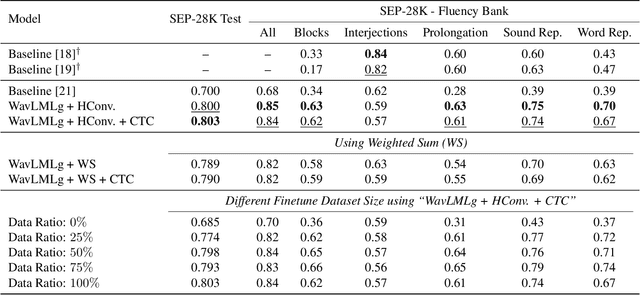
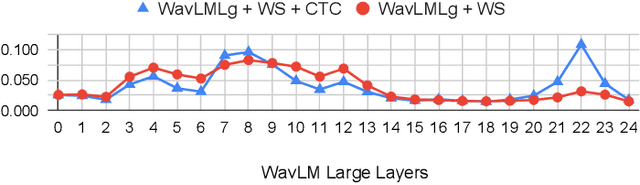
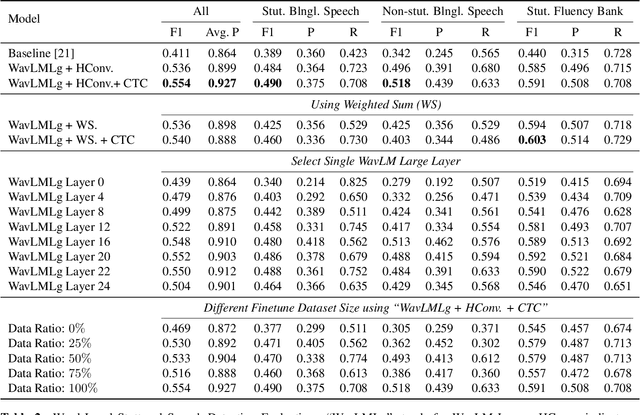
Clinical diagnosis of stuttering requires an assessment by a licensed speech-language pathologist. However, this process is time-consuming and requires clinicians with training and experience in stuttering and fluency disorders. Unfortunately, only a small percentage of speech-language pathologists report being comfortable working with individuals who stutter, which is inadequate to accommodate for the 80 million individuals who stutter worldwide. Developing machine learning models for detecting stuttered speech would enable universal and automated screening for stuttering, enabling speech pathologists to identify and follow up with patients who are most likely to be diagnosed with a stuttering speech disorder. Previous research in this area has predominantly focused on utterance-level detection, which is not sufficient for clinical settings where word-level annotation of stuttering is the norm. In this study, we curated a stuttered speech dataset with word-level annotations and introduced a word-level stuttering speech detection model leveraging self-supervised speech models. Our evaluation demonstrates that our model surpasses previous approaches in word-level stuttering speech detection. Additionally, we conducted an extensive ablation analysis of our method, providing insight into the most important aspects of adapting self-supervised speech models for stuttered speech detection.
DataComp-LM: In search of the next generation of training sets for language models
Jun 18, 2024



We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
Which questions should I answer? Salience Prediction of Inquisitive Questions
Apr 16, 2024Inquisitive questions -- open-ended, curiosity-driven questions people ask as they read -- are an integral part of discourse processing (Kehler and Rohde, 2017; Onea, 2016) and comprehension (Prince, 2004). Recent work in NLP has taken advantage of question generation capabilities of LLMs to enhance a wide range of applications. But the space of inquisitive questions is vast: many questions can be evoked from a given context. So which of those should be prioritized to find answers? Linguistic theories, unfortunately, have not yet provided an answer to this question. This paper presents QSALIENCE, a salience predictor of inquisitive questions. QSALIENCE is instruction-tuned over our dataset of linguist-annotated salience scores of 1,766 (context, question) pairs. A question scores high on salience if answering it would greatly enhance the understanding of the text (Van Rooy, 2003). We show that highly salient questions are empirically more likely to be answered in the same article, bridging potential questions (Onea, 2016) with Questions Under Discussion (Roberts, 2012). We further validate our findings by showing that answering salient questions is an indicator of summarization quality in news.
Pre-training Small Base LMs with Fewer Tokens
Apr 12, 2024We study the effectiveness of a simple approach to develop a small base language model (LM) starting from an existing large base LM: first inherit a few transformer blocks from the larger LM, and then train this smaller model on a very small subset (0.1\%) of the raw pretraining data of the larger model. We call our simple recipe Inheritune and first demonstrate it for building a small base LM with 1.5B parameters using 1B tokens (and a starting few layers of larger LM of 3B parameters); we do this using a single A6000 GPU for less than half a day. Across 9 diverse evaluation datasets as well as the MMLU benchmark, the resulting model compares favorably to publicly available base models of 1B-2B size, some of which have been trained using 50-1000 times more tokens. We investigate Inheritune in a slightly different setting where we train small LMs utilizing larger LMs and their full pre-training dataset. Here we show that smaller LMs trained utilizing some of the layers of GPT2-medium (355M) and GPT-2-large (770M) can effectively match the val loss of their bigger counterparts when trained from scratch for the same number of training steps on OpenWebText dataset with 9B tokens. We analyze our recipe with extensive experiments and demonstrate it efficacy on diverse settings. Our code is available at https://github.com/sanyalsunny111/LLM-Inheritune.
Language models scale reliably with over-training and on downstream tasks
Mar 13, 2024



Scaling laws are useful guides for developing language models, but there are still gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., "Chinchilla optimal" regime); however, in practice, models are often over-trained to reduce inference costs. Moreover, scaling laws mostly predict loss on next-token prediction, but ultimately models are compared based on downstream task performance. In this paper, we address both shortcomings. To do so, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we investigate scaling in the over-trained regime. We fit scaling laws that extrapolate in both the number of model parameters and the ratio of training tokens to parameters. This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32$\times$ over-trained) and a 6.9B parameter, 138B token run$\unicode{x2014}$each from experiments that take 300$\times$ less compute. Second, we relate the perplexity of a language model to its downstream task performance via a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models using experiments that take 20$\times$ less compute. Our experiments are available at https://github.com/mlfoundations/scaling.